 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning dissection trajectories from expert surgical videos via imitation learning with equivariant diffusion
Jun 05, 2025



Endoscopic Submucosal Dissection (ESD) is a well-established technique for removing epithelial lesions. Predicting dissection trajectories in ESD videos offers significant potential for enhancing surgical skill training and simplifying the learning process, yet this area remains underexplored. While imitation learning has shown promise in acquiring skills from expert demonstrations, challenges persist in handling uncertain future movements, learning geometric symmetries, and generalizing to diverse surgical scenarios. To address these, we introduce a novel approach: Implicit Diffusion Policy with Equivariant Representations for Imitation Learning (iDPOE). Our method models expert behavior through a joint state action distribution, capturing the stochastic nature of dissection trajectories and enabling robust visual representation learning across various endoscopic views. By incorporating a diffusion model into policy learning, iDPOE ensures efficient training and sampling, leading to more accurate predictions and better generalization. Additionally, we enhance the model's ability to generalize to geometric symmetries by embedding equivariance into the learning process. To address state mismatches, we develop a forward-process guided action inference strategy for conditional sampling. Using an ESD video dataset of nearly 2000 clips, experimental results show that our approach surpasses state-of-the-art methods, both explicit and implicit, in trajectory prediction. To the best of our knowledge, this is the first application of imitation learning to surgical skill development for dissection trajectory prediction.
SegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024



Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
Multi-objective Cross-task Learning via Goal-conditioned GPT-based Decision Transformers for Surgical Robot Task Automation
May 29, 2024



Surgical robot task automation has been a promising research topic for improving surgical efficiency and quality. Learning-based methods have been recognized as an interesting paradigm and been increasingly investigated. However, existing approaches encounter difficulties in long-horizon goal-conditioned tasks due to the intricate compositional structure, which requires decision-making for a sequence of sub-steps and understanding of inherent dynamics of goal-reaching tasks. In this paper, we propose a new learning-based framework by leveraging the strong reasoning capability of the GPT-based architecture to automate surgical robotic tasks. The key to our approach is developing a goal-conditioned decision transformer to achieve sequential representations with goal-aware future indicators in order to enhance temporal reasoning. Moreover, considering to exploit a general understanding of dynamics inherent in manipulations, thus making the model's reasoning ability to be task-agnostic, we also design a cross-task pretraining paradigm that uses multiple training objectives associated with data from diverse tasks. We have conducted extensive experiments on 10 tasks using the surgical robot learning simulator SurRoL~\cite{long2023human}. The results show that our new approach achieves promising performance and task versatility compared to existing methods. The learned trajectories can be deployed on the da Vinci Research Kit (dVRK) for validating its practicality in real surgical robot settings. Our project website is at: https://med-air.github.io/SurRoL.
Efficient Data-driven Scene Simulation using Robotic Surgery Videos via Physics-embedded 3D Gaussians
May 02, 2024



Surgical scene simulation plays a crucial role in surgical education and simulator-based robot learning. Traditional approaches for creating these environments with surgical scene involve a labor-intensive process where designers hand-craft tissues models with textures and geometries for soft body simulations. This manual approach is not only time-consuming but also limited in the scalability and realism. In contrast, data-driven simulation offers a compelling alternative. It has the potential to automatically reconstruct 3D surgical scenes from real-world surgical video data, followed by the application of soft body physics. This area, however, is relatively uncharted. In our research, we introduce 3D Gaussian as a learnable representation for surgical scene, which is learned from stereo endoscopic video. To prevent over-fitting and ensure the geometrical correctness of these scenes, we incorporate depth supervision and anisotropy regularization into the Gaussian learning process. Furthermore, we apply the Material Point Method, which is integrated with physical properties, to the 3D Gaussians to achieve realistic scene deformations. Our method was evaluated on our collected in-house and public surgical videos datasets. Results show that it can reconstruct and simulate surgical scenes from endoscopic videos efficiently-taking only a few minutes to reconstruct the surgical scene-and produce both visually and physically plausible deformations at a speed approaching real-time. The results demonstrate great potential of our proposed method to enhance the efficiency and variety of simulations available for surgical education and robot learning.
Efficient Physically-based Simulation of Soft Bodies in Embodied Environment for Surgical Robot
Feb 02, 2024Surgical robot simulation platform plays a crucial role in enhancing training efficiency and advancing research on robot learning. Much effort have been made by scholars on developing open-sourced surgical robot simulators to facilitate research. We also developed SurRoL formerly, an open-source, da Vinci Research Kit (dVRK) compatible and interactive embodied environment for robot learning. Despite its advancements, the simulation of soft bodies still remained a major challenge within the open-source platforms available for surgical robotics. To this end, we develop an interactive physically based soft body simulation framework and integrate it to SurRoL. Specifically, we utilized a high-performance adaptation of the Material Point Method (MPM) along with the Neo-Hookean model to represent the deformable tissue. Lagrangian particles are used to track the motion and deformation of the soft body throughout the simulation and Eulerian grids are leveraged to discretize space and facilitate the calculation of forces, velocities, and other physical quantities. We also employed an efficient collision detection and handling strategy to simulate the interaction between soft body and rigid tool of the surgical robot. By employing the Taichi programming language, our implementation harnesses parallel computing to boost simulation speed. Experimental results show that our platform is able to simulate soft bodies efficiently with strong physical interpretability and plausible visual effects. These new features in SurRoL enable the efficient simulation of surgical tasks involving soft tissue manipulation and pave the path for further investigation of surgical robot learning. The code will be released in a new branch of SurRoL github repo.
Visual-Kinematics Graph Learning for Procedure-agnostic Instrument Tip Segmentation in Robotic Surgeries
Sep 02, 2023



Accurate segmentation of surgical instrument tip is an important task for enabling downstream applications in robotic surgery, such as surgical skill assessment, tool-tissue interaction and deformation modeling, as well as surgical autonomy. However, this task is very challenging due to the small sizes of surgical instrument tips, and significant variance of surgical scenes across different procedures. Although much effort has been made on visual-based methods, existing segmentation models still suffer from low robustness thus not usable in practice. Fortunately, kinematics data from the robotic system can provide reliable prior for instrument location, which is consistent regardless of different surgery types. To make use of such multi-modal information, we propose a novel visual-kinematics graph learning framework to accurately segment the instrument tip given various surgical procedures. Specifically, a graph learning framework is proposed to encode relational features of instrument parts from both image and kinematics. Next, a cross-modal contrastive loss is designed to incorporate robust geometric prior from kinematics to image for tip segmentation. We have conducted experiments on a private paired visual-kinematics dataset including multiple procedures, i.e., prostatectomy, total mesorectal excision, fundoplication and distal gastrectomy on cadaver, and distal gastrectomy on porcine. The leave-one-procedure-out cross validation demonstrated that our proposed multi-modal segmentation method significantly outperformed current image-based state-of-the-art approaches, exceeding averagely 11.2% on Dice.
Value-Informed Skill Chaining for Policy Learning of Long-Horizon Tasks with Surgical Robot
Jul 31, 2023



Reinforcement learning is still struggling with solving long-horizon surgical robot tasks which involve multiple steps over an extended duration of time due to the policy exploration challenge. Recent methods try to tackle this problem by skill chaining, in which the long-horizon task is decomposed into multiple subtasks for easing the exploration burden and subtask policies are temporally connected to complete the whole long-horizon task. However, smoothly connecting all subtask policies is difficult for surgical robot scenarios. Not all states are equally suitable for connecting two adjacent subtasks. An undesired terminate state of the previous subtask would make the current subtask policy unstable and result in a failed execution. In this work, we introduce value-informed skill chaining (ViSkill), a novel reinforcement learning framework for long-horizon surgical robot tasks. The core idea is to distinguish which terminal state is suitable for starting all the following subtask policies. To achieve this target, we introduce a state value function that estimates the expected success probability of the entire task given a state. Based on this value function, a chaining policy is learned to instruct subtask policies to terminate at the state with the highest value so that all subsequent policies are more likely to be connected for accomplishing the task. We demonstrate the effectiveness of our method on three complex surgical robot tasks from SurRoL, a comprehensive surgical simulation platform, achieving high task success rates and execution efficiency. Code is available at $\href{https://github.com/med-air/ViSkill}{\text{https://github.com/med-air/ViSkill}}$.
Human-in-the-loop Embodied Intelligence with Interactive Simulation Environment for Surgical Robot Learning
Jan 01, 2023



Surgical robot automation has attracted increasing research interest over the past decade, expecting its huge potential to benefit surgeons, nurses and patients. Recently, the learning paradigm of embodied AI has demonstrated promising ability to learn good control policies for various complex tasks, where embodied AI simulators play an essential role to facilitate relevant researchers. However, existing open-sourced simulators for surgical robot are still not sufficiently supporting human interactions through physical input devices, which further limits effective investigations on how human demonstrations would affect policy learning. In this paper, we study human-in-the-loop embodied intelligence with a new interactive simulation platform for surgical robot learning. Specifically, we establish our platform based on our previously released SurRoL simulator with several new features co-developed to allow high-quality human interaction via an input device. With these, we further propose to collect human demonstrations and imitate the action patterns to achieve more effective policy learning. We showcase the improvement of our simulation environment with the designed new features and tasks, and validate state-of-the-art reinforcement learning algorithms using the interactive environment. Promising results are obtained, with which we hope to pave the way for future research on surgical embodied intelligence. Our platform is released and will be continuously updated in the website: https://med-air.github.io/SurRoL/
Distilled Visual and Robot Kinematics Embeddings for Metric Depth Estimation in Monocular Scene Reconstruction
Nov 27, 2022



Estimating precise metric depth and scene reconstruction from monocular endoscopy is a fundamental task for surgical navigation in robotic surgery. However, traditional stereo matching adopts binocular images to perceive the depth information, which is difficult to transfer to the soft robotics-based surgical systems due to the use of monocular endoscopy. In this paper, we present a novel framework that combines robot kinematics and monocular endoscope images with deep unsupervised learning into a single network for metric depth estimation and then achieve 3D reconstruction of complex anatomy. Specifically, we first obtain the relative depth maps of surgical scenes by leveraging a brightness-aware monocular depth estimation method. Then, the corresponding endoscope poses are computed based on non-linear optimization of geometric and photometric reprojection residuals. Afterwards, we develop a Depth-driven Sliding Optimization (DDSO) algorithm to extract the scaling coefficient from kinematics and calculated poses offline. By coupling the metric scale and relative depth data, we form a robust ensemble that represents the metric and consistent depth. Next, we treat the ensemble as supervisory labels to train a metric depth estimation network for surgeries (i.e., MetricDepthS-Net) that distills the embeddings from the robot kinematics, endoscopic videos, and poses. With accurate metric depth estimation, we utilize a dense visual reconstruction method to recover the 3D structure of the whole surgical site. We have extensively evaluated the proposed framework on public SCARED and achieved comparable performance with stereo-based depth estimation methods. Our results demonstrate the feasibility of the proposed approach to recover the metric depth and 3D structure with monocular inputs.
AutoLaparo: A New Dataset of Integrated Multi-tasks for Image-guided Surgical Automation in Laparoscopic Hysterectomy
Aug 03, 2022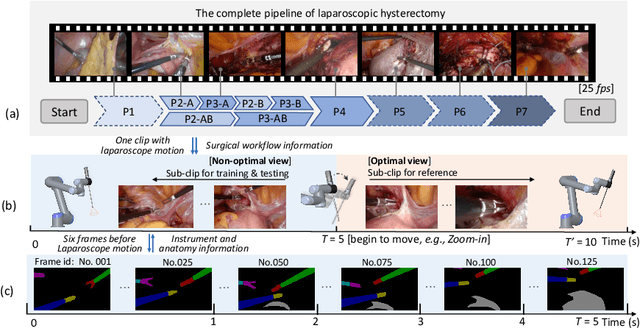

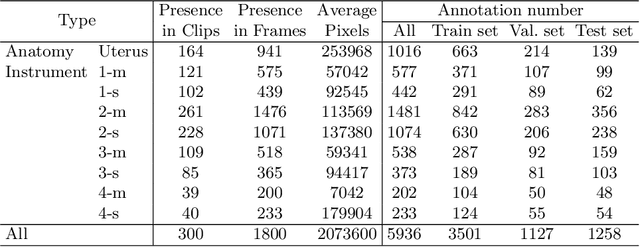

Computer-assisted minimally invasive surgery has great potential in benefiting modern operating theatres. The video data streamed from the endoscope provides rich information to support context-awareness for next-generation intelligent surgical systems. To achieve accurate perception and automatic manipulation during the procedure, learning based technique is a promising way, which enables advanced image analysis and scene understanding in recent years. However, learning such models highly relies on large-scale, high-quality, and multi-task labelled data. This is currently a bottleneck for the topic, as available public dataset is still extremely limited in the field of CAI. In this paper, we present and release the first integrated dataset (named AutoLaparo) with multiple image-based perception tasks to facilitate learning-based automation in hysterectomy surgery. Our AutoLaparo dataset is developed based on full-length videos of entire hysterectomy procedures. Specifically, three different yet highly correlated tasks are formulated in the dataset, including surgical workflow recognition, laparoscope motion prediction, and instrument and key anatomy segmentation. In addition, we provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset. The dataset is available at https://autolaparo.github.io.