 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Nov 14, 2022



Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.
GM-TCNet: Gated Multi-scale Temporal Convolutional Network using Emotion Causality for Speech Emotion Recognition
Oct 28, 2022



In human-computer interaction, Speech Emotion Recognition (SER) plays an essential role in understanding the user's intent and improving the interactive experience. While similar sentimental speeches own diverse speaker characteristics but share common antecedents and consequences, an essential challenge for SER is how to produce robust and discriminative representations through causality between speech emotions. In this paper, we propose a Gated Multi-scale Temporal Convolutional Network (GM-TCNet) to construct a novel emotional causality representation learning component with a multi-scale receptive field. GM-TCNet deploys a novel emotional causality representation learning component to capture the dynamics of emotion across the time domain, constructed with dilated causal convolution layer and gating mechanism. Besides, it utilizes skip connection fusing high-level features from different gated convolution blocks to capture abundant and subtle emotion changes in human speech. GM-TCNet first uses a single type of feature, mel-frequency cepstral coefficients, as inputs and then passes them through the gated temporal convolutional module to generate the high-level features. Finally, the features are fed to the emotion classifier to accomplish the SER task. The experimental results show that our model maintains the highest performance in most cases compared to state-of-the-art techniques.
* The source code is available at: https://github.com/Jiaxin-Ye/GM-TCNet
Prompt-driven efficient Open-set Semi-supervised Learning
Sep 28, 2022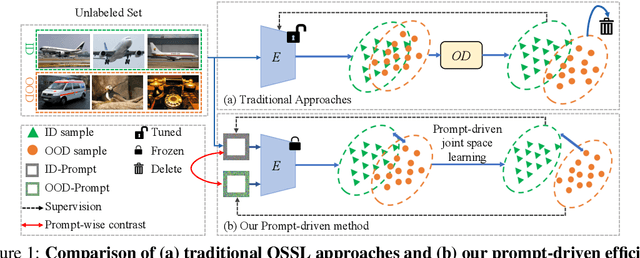
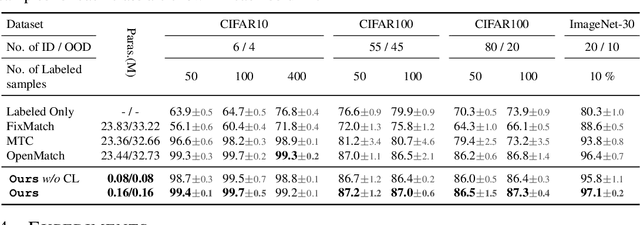
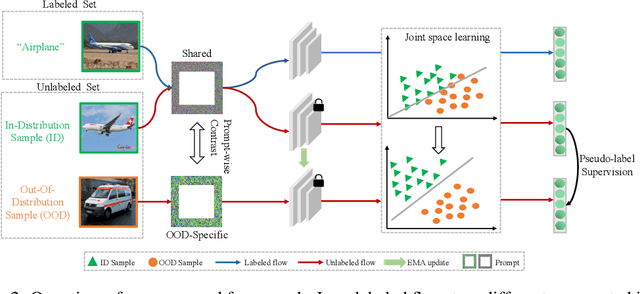
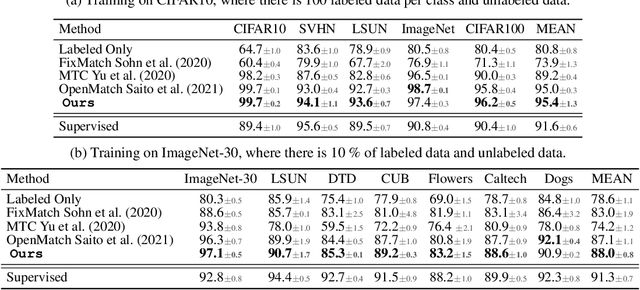
Open-set semi-supervised learning (OSSL) has attracted growing interest, which investigates a more practical scenario where out-of-distribution (OOD) samples are only contained in unlabeled data. Existing OSSL methods like OpenMatch learn an OOD detector to identify outliers, which often update all modal parameters (i.e., full fine-tuning) to propagate class information from labeled data to unlabeled ones. Currently, prompt learning has been developed to bridge gaps between pre-training and fine-tuning, which shows higher computational efficiency in several downstream tasks. In this paper, we propose a prompt-driven efficient OSSL framework, called OpenPrompt, which can propagate class information from labeled to unlabeled data with only a small number of trainable parameters. We propose a prompt-driven joint space learning mechanism to detect OOD data by maximizing the distribution gap between ID and OOD samples in unlabeled data, thereby our method enables the outliers to be detected in a new way. The experimental results on three public datasets show that OpenPrompt outperforms state-of-the-art methods with less than 1% of trainable parameters. More importantly, OpenPrompt achieves a 4% improvement in terms of AUROC on outlier detection over a fully supervised model on CIFAR10.
A Survey on Incomplete Multi-view Clustering
Aug 17, 2022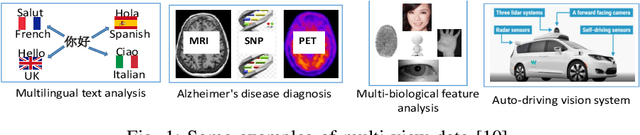
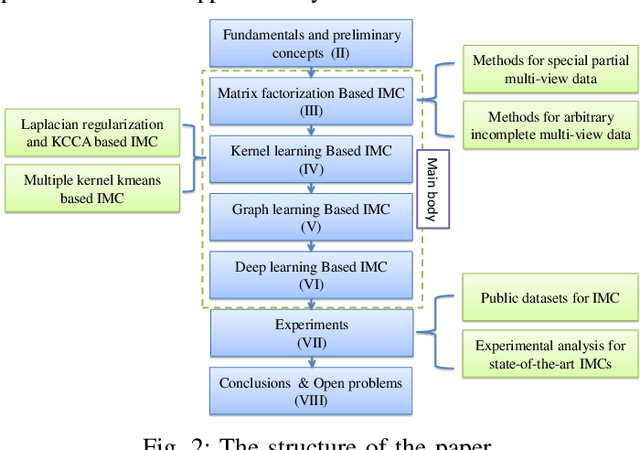
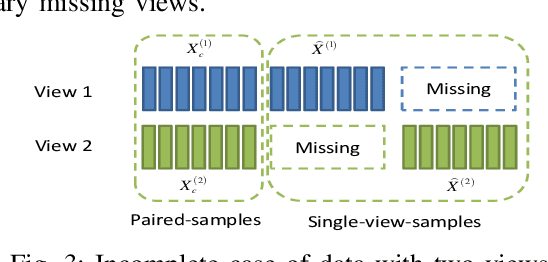
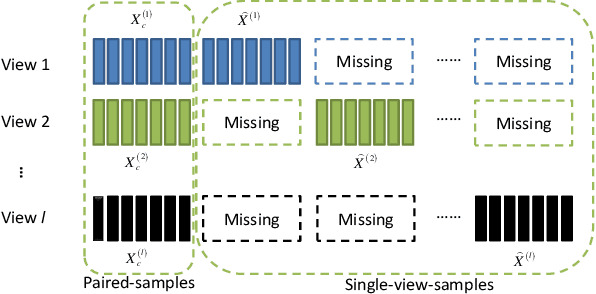
Conventional multi-view clustering seeks to partition data into respective groups based on the assumption that all views are fully observed. However, in practical applications, such as disease diagnosis, multimedia analysis, and recommendation system, it is common to observe that not all views of samples are available in many cases, which leads to the failure of the conventional multi-view clustering methods. Clustering on such incomplete multi-view data is referred to as incomplete multi-view clustering. In view of the promising application prospects, the research of incomplete multi-view clustering has noticeable advances in recent years. However, there is no survey to summarize the current progresses and point out the future research directions. To this end, we review the recent studies of incomplete multi-view clustering. Importantly, we provide some frameworks to unify the corresponding incomplete multi-view clustering methods, and make an in-depth comparative analysis for some representative methods from theoretical and experimental perspectives. Finally, some open problems in the incomplete multi-view clustering field are offered for researchers.
Localized Sparse Incomplete Multi-view Clustering
Aug 05, 2022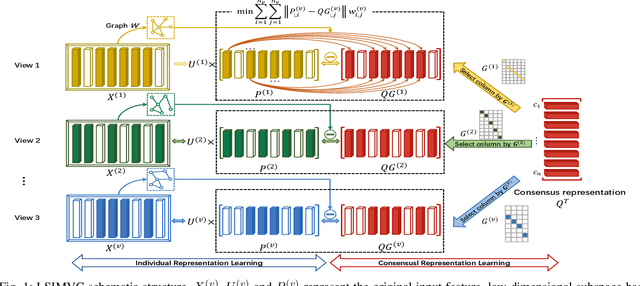
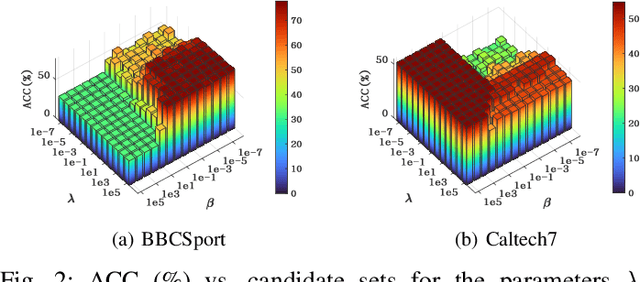
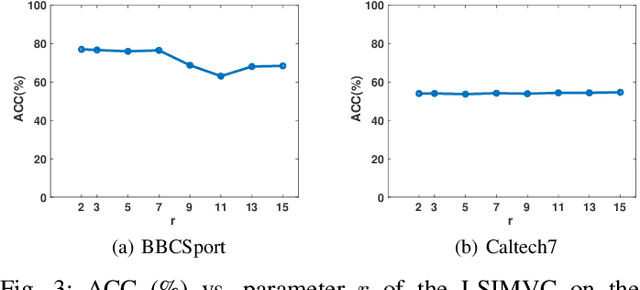
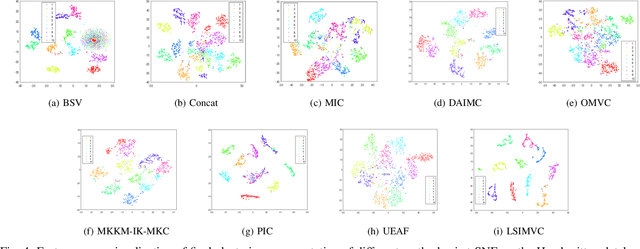
Incomplete multi-view clustering, which aims to solve the clustering problem on the incomplete multi-view data with partial view missing, has received more and more attention in recent years. Although numerous methods have been developed, most of the methods either cannot flexibly handle the incomplete multi-view data with arbitrary missing views or do not consider the negative factor of information imbalance among views. Moreover, some methods do not fully explore the local structure of all incomplete views. To tackle these problems, this paper proposes a simple but effective method, named localized sparse incomplete multi-view clustering (LSIMVC). Different from the existing methods, LSIMVC intends to learn a sparse and structured consensus latent representation from the incomplete multi-view data by optimizing a sparse regularized and novel graph embedded multi-view matrix factorization model. Specifically, in such a novel model based on the matrix factorization, a l1 norm based sparse constraint is introduced to obtain the sparse low-dimensional individual representations and the sparse consensus representation. Moreover, a novel local graph embedding term is introduced to learn the structured consensus representation. Different from the existing works, our local graph embedding term aggregates the graph embedding task and consensus representation learning task into a concise term. Furthermore, to reduce the imbalance factor of incomplete multi-view learning, an adaptive weighted learning scheme is introduced to LSIMVC. Finally, an efficient optimization strategy is given to solve the optimization problem of our proposed model. Comprehensive experimental results performed on six incomplete multi-view databases verify that the performance of our LSIMVC is superior to the state-of-the-art IMC approaches. The code is available in https://github.com/justsmart/LSIMVC.
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022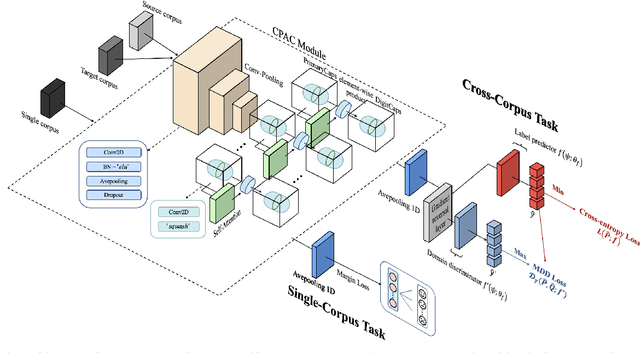
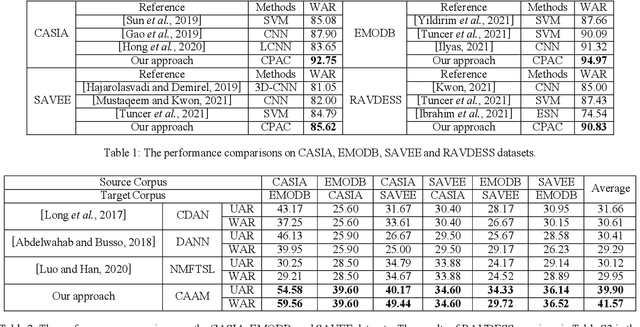
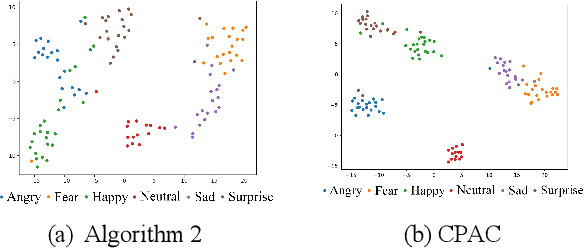

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet
Multi-Behavior Sequential Recommendation with Temporal Graph Transformer
Jun 06, 2022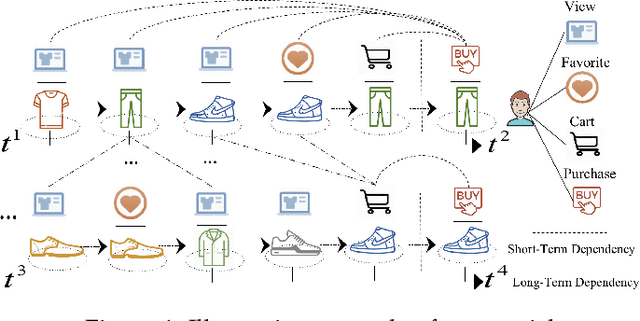

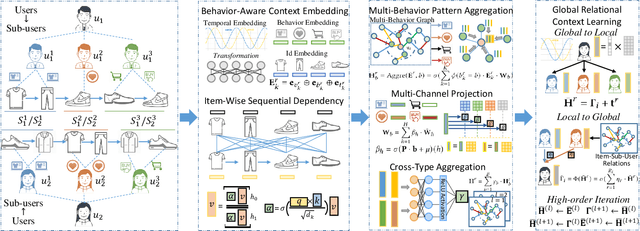

Modeling time-evolving preferences of users with their sequential item interactions, has attracted increasing attention in many online applications. Hence, sequential recommender systems have been developed to learn the dynamic user interests from the historical interactions for suggesting items. However, the interaction pattern encoding functions in most existing sequential recommender systems have focused on single type of user-item interactions. In many real-life online platforms, user-item interactive behaviors are often multi-typed (e.g., click, add-to-favorite, purchase) with complex cross-type behavior inter-dependencies. Learning from informative representations of users and items based on their multi-typed interaction data, is of great importance to accurately characterize the time-evolving user preference. In this work, we tackle the dynamic user-item relation learning with the awareness of multi-behavior interactive patterns. Towards this end, we propose a new Temporal Graph Transformer (TGT) recommendation framework to jointly capture dynamic short-term and long-range user-item interactive patterns, by exploring the evolving correlations across different types of behaviors. The new TGT method endows the sequential recommendation architecture to distill dedicated knowledge for type-specific behavior relational context and the implicit behavior dependencies. Experiments on the real-world datasets indicate that our method TGT consistently outperforms various state-of-the-art recommendation methods. Our model implementation codes are available at https://github.com/akaxlh/TGT.
Deniable Steganography
May 25, 2022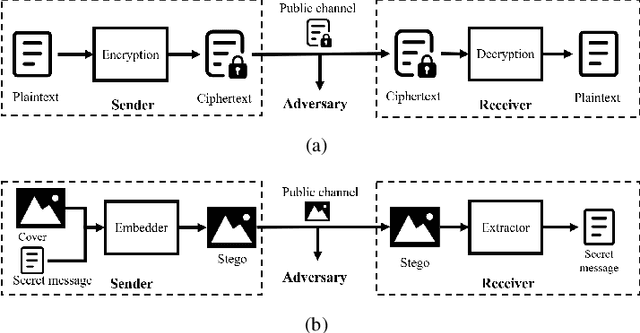
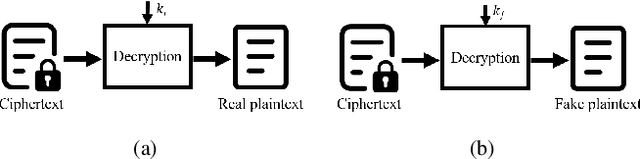

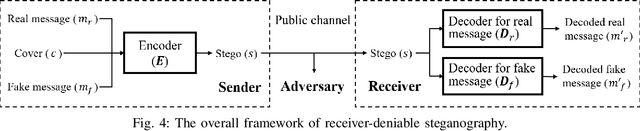
Steganography conceals the secret message into the cover media, generating a stego media which can be transmitted on public channels without drawing suspicion. As its countermeasure, steganalysis mainly aims to detect whether the secret message is hidden in a given media. Although the steganography techniques are improving constantly, the sophisticated steganalysis can always break a known steganographic method to some extent. With a stego media discovered, the adversary could find out the sender or receiver and coerce them to disclose the secret message, which we name as coercive attack in this paper. Inspired by the idea of deniable encryption, we build up the concepts of deniable steganography for the first time and discuss the feasible constructions for it. As an example, we propose a receiver-deniable steganographic scheme to deal with the receiver-side coercive attack using deep neural networks (DNN). Specifically, besides the real secret message, a piece of fake message is also embedded into the cover. On the receiver side, the real message can be extracted with an extraction module; while once the receiver has to surrender a piece of secret message under coercive attack, he can extract the fake message to deceive the adversary with another extraction module. Experiments demonstrate the scalability and sensitivity of the DNN-based receiver-deniable steganographic scheme.
NeuralEcho: A Self-Attentive Recurrent Neural Network For Unified Acoustic Echo Suppression And Speech Enhancement
May 20, 2022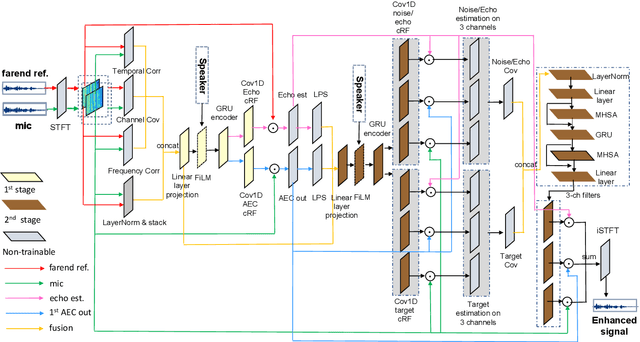
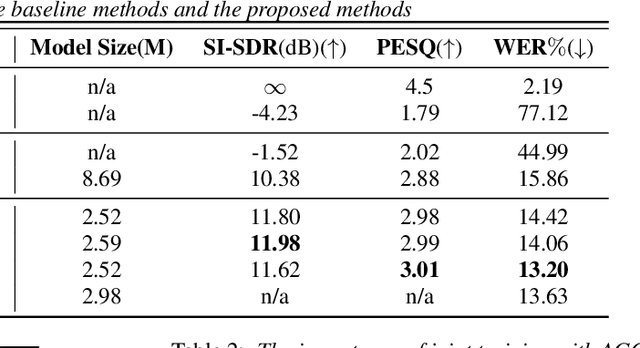
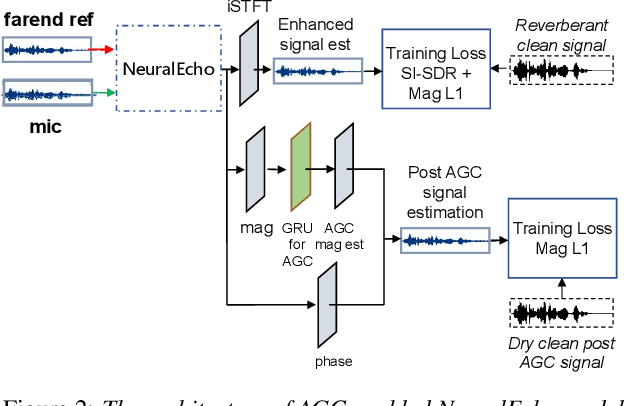

Acoustic echo cancellation (AEC) plays an important role in the full-duplex speech communication as well as the front-end speech enhancement for recognition in the conditions when the loudspeaker plays back. In this paper, we present an all-deep-learning framework that implicitly estimates the second order statistics of echo/noise and target speech, and jointly solves echo and noise suppression through an attention based recurrent neural network. The proposed model outperforms the state-of-the-art joint echo cancellation and speech enhancement method F-T-LSTM in terms of objective speech quality metrics, speech recognition accuracy and model complexity. We show that this model can work with speaker embedding for better target speech enhancement and furthermore develop a branch for automatic gain control (AGC) task to form an all-in-one front-end speech enhancement system.
Hypergraph Contrastive Collaborative Filtering
Apr 27, 2022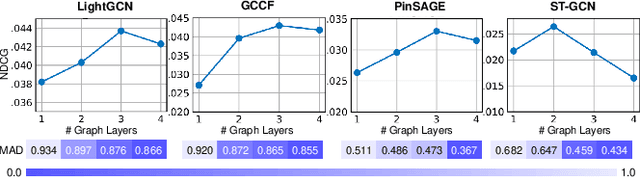
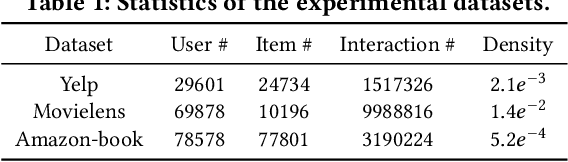
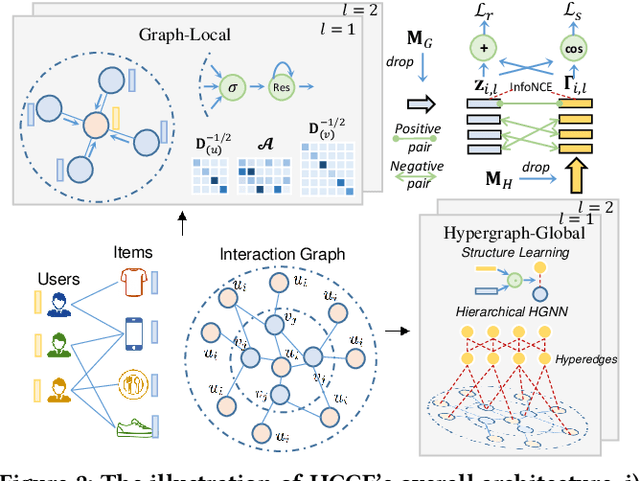
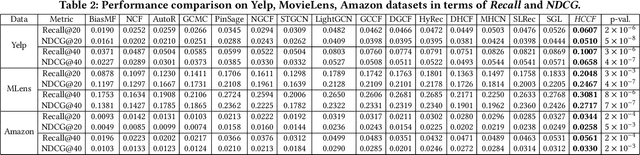
Collaborative Filtering (CF) has emerged as fundamental paradigms for parameterizing users and items into latent representation space, with their correlative patterns from interaction data. Among various CF techniques, the development of GNN-based recommender systems, e.g., PinSage and LightGCN, has offered the state-of-the-art performance. However, two key challenges have not been well explored in existing solutions: i) The over-smoothing effect with deeper graph-based CF architecture, may cause the indistinguishable user representations and degradation of recommendation results. ii) The supervision signals (i.e., user-item interactions) are usually scarce and skewed distributed in reality, which limits the representation power of CF paradigms. To tackle these challenges, we propose a new self-supervised recommendation framework Hypergraph Contrastive Collaborative Filtering (HCCF) to jointly capture local and global collaborative relations with a hypergraph-enhanced cross-view contrastive learning architecture. In particular, the designed hypergraph structure learning enhances the discrimination ability of GNN-based CF paradigm, so as to comprehensively capture the complex high-order dependencies among users. Additionally, our HCCF model effectively integrates the hypergraph structure encoding with self-supervised learning to reinforce the representation quality of recommender systems, based on the hypergraph-enhanced self-discrimination. Extensive experiments on three benchmark datasets demonstrate the superiority of our model over various state-of-the-art recommendation methods, and the robustness against sparse user interaction data. Our model implementation codes are available at https://github.com/akaxlh/HCCF.