 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinTrack: A Simple and Strong Baseline for Transformer Tracking
Dec 08, 2021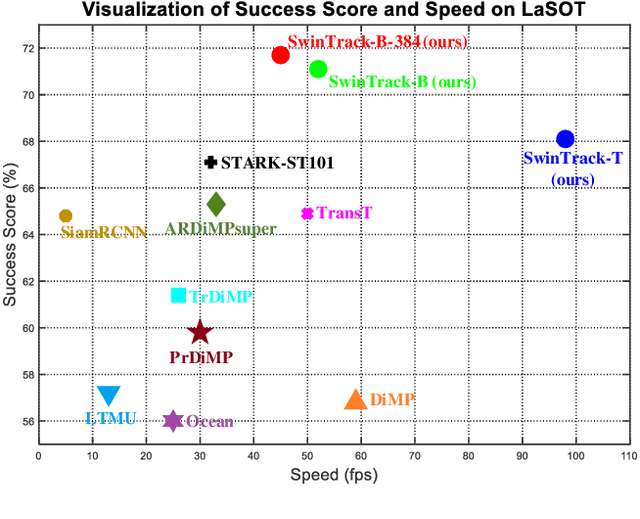
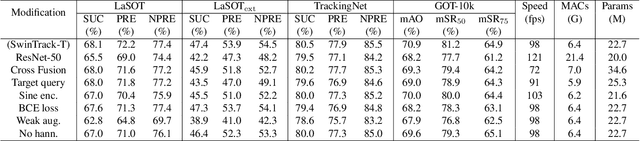
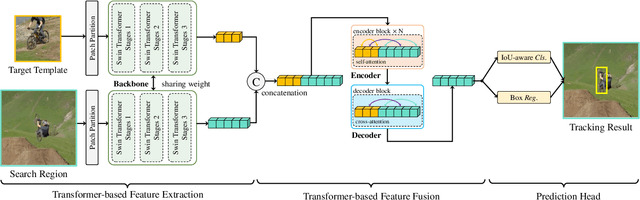
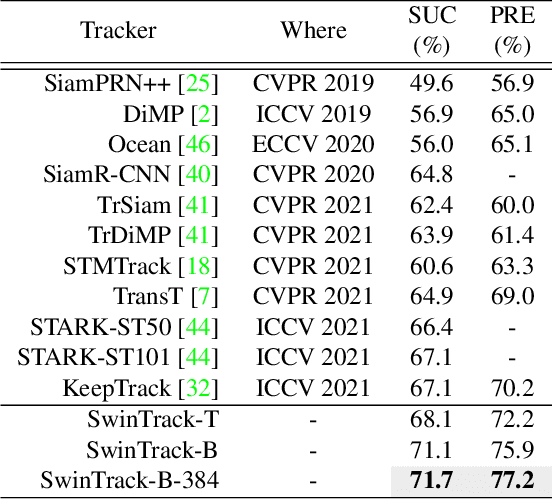
Transformer has recently demonstrated clear potential in improving visual tracking algorithms. Nevertheless, existing transformer-based trackers mostly use Transformer to fuse and enhance the features generated by convolutional neural networks (CNNs). By contrast, in this paper, we propose a fully attentional-based Transformer tracking algorithm, Swin-Transformer Tracker (SwinTrack). SwinTrack uses Transformer for both feature extraction and feature fusion, allowing full interactions between the target object and the search region for tracking. To further improve performance, we investigate comprehensively different strategies for feature fusion, position encoding, and training loss. All these efforts make SwinTrack a simple yet solid baseline. In our thorough experiments, SwinTrack sets a new record with 0.702 SUC on LaSOT, surpassing STARK by 3.1% while still running at 45 FPS. Besides, it achieves state-of-the-art performances with 0.476 SUC, 0.840 SUC and 0.694 AO on other challenging LaSOT$_{ext}$, TrackingNet, and GOT-10k datasets. Our implementation and trained models are available at https://github.com/LitingLin/SwinTrack.
Joint AEC AND Beamforming with Double-Talk Detection using RNN-Transformer
Nov 09, 2021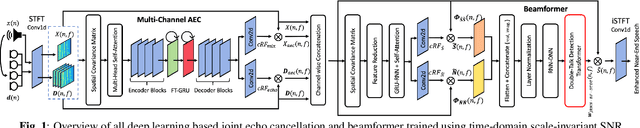
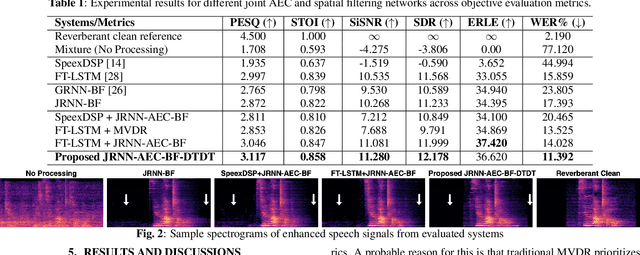
Acoustic echo cancellation (AEC) is a technique used in full-duplex communication systems to eliminate acoustic feedback of far-end speech. However, their performance degrades in naturalistic environments due to nonlinear distortions introduced by the speaker, as well as background noise, reverberation, and double-talk scenarios. To address nonlinear distortions and co-existing background noise, several deep neural network (DNN)-based joint AEC and denoising systems were developed. These systems are based on either purely "black-box" neural networks or "hybrid" systems that combine traditional AEC algorithms with neural networks. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. We propose an all-deep-learning framework that combines multi-channel AEC and our recently proposed self-attentive recurrent neural network (RNN) beamformer. Furthermore, we propose a double-talk detection transformer (DTDT) module based on the multi-head attention transformer structure that computes attention over time by leveraging frame-wise double-talk predictions. Experiments show that our proposed method outperforms other approaches in terms of improving speech quality and speech recognition rate of an ASR system.
Multi-modal Aggregation Network for Fast MR Imaging
Oct 20, 2021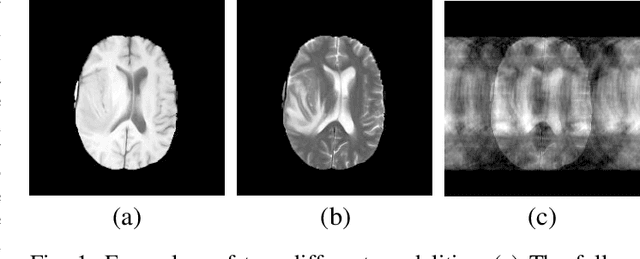
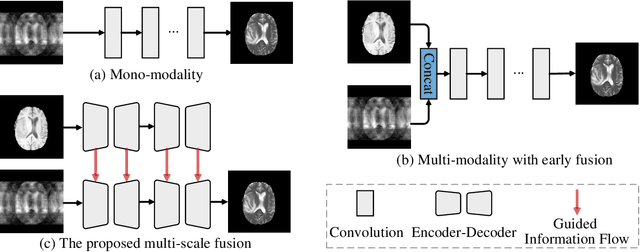
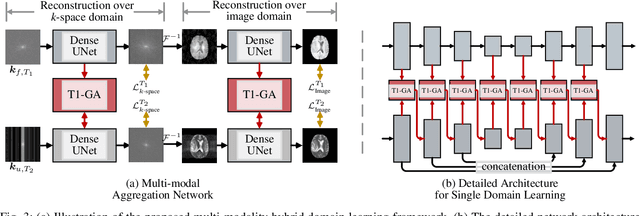
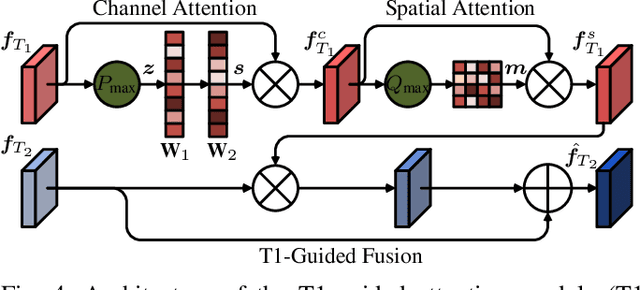
Magnetic resonance (MR) imaging is a commonly used scanning technique for disease detection, diagnosis and treatment monitoring. Although it is able to produce detailed images of organs and tissues with better contrast, it suffers from a long acquisition time, which makes the image quality vulnerable to say motion artifacts. Recently, many approaches have been developed to reconstruct full-sampled images from partially observed measurements in order to accelerate MR imaging. However, most of these efforts focus on reconstruction over a single modality or simple fusion of multiple modalities, neglecting the discovery of correlation knowledge at different feature level. In this work, we propose a novel Multi-modal Aggregation Network, named MANet, which is capable of discovering complementary representations from a fully sampled auxiliary modality, with which to hierarchically guide the reconstruction of a given target modality. In our MANet, the representations from the fully sampled auxiliary and undersampled target modalities are learned independently through a specific network. Then, a guided attention module is introduced in each convolutional stage to selectively aggregate multi-modal features for better reconstruction, yielding comprehensive, multi-scale, multi-modal feature fusion. Moreover, our MANet follows a hybrid domain learning framework, which allows it to simultaneously recover the frequency signal in the $k$-space domain as well as restore the image details from the image domain. Extensive experiments demonstrate the superiority of the proposed approach over state-of-the-art MR image reconstruction methods.
Global Context Enhanced Social Recommendation with Hierarchical Graph Neural Networks
Oct 08, 2021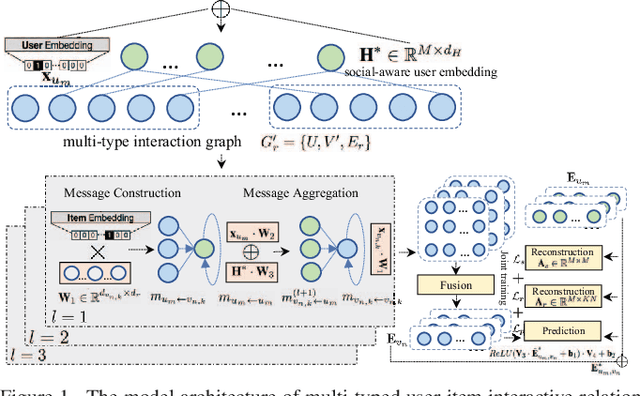
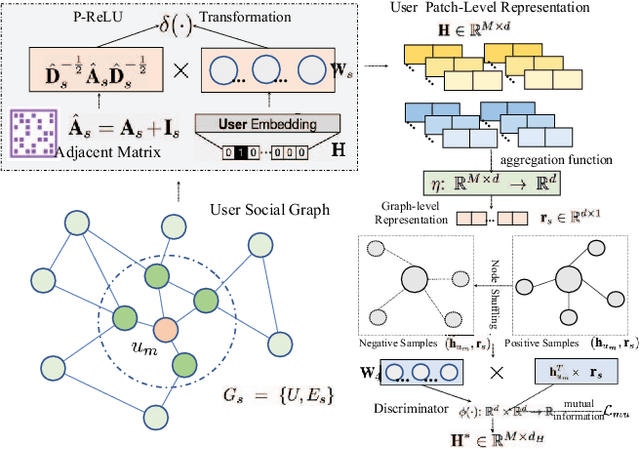
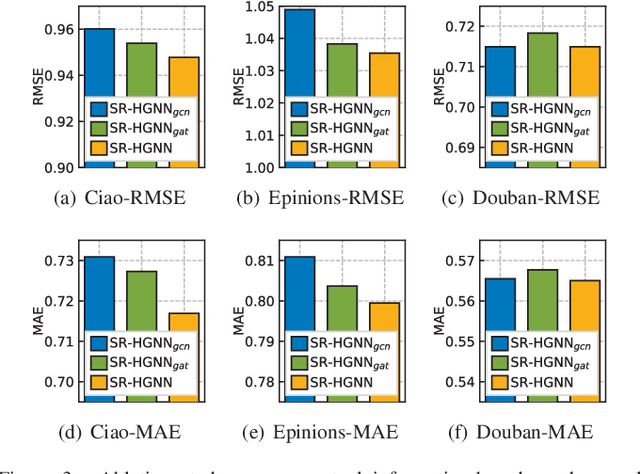
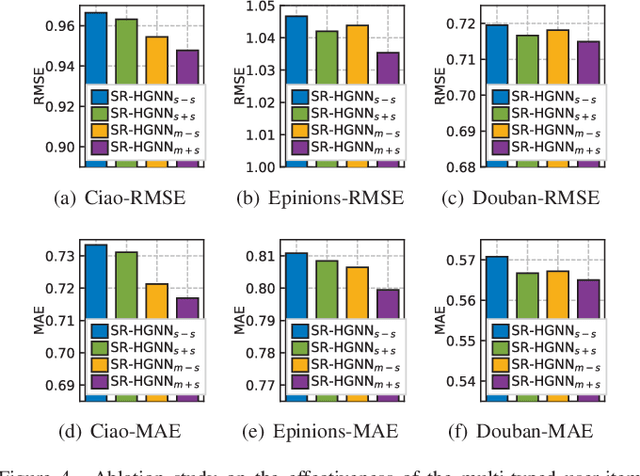
Social recommendation which aims to leverage social connections among users to enhance the recommendation performance. With the revival of deep learning techniques, many efforts have been devoted to developing various neural network-based social recommender systems, such as attention mechanisms and graph-based message passing frameworks. However, two important challenges have not been well addressed yet: (i) Most of existing social recommendation models fail to fully explore the multi-type user-item interactive behavior as well as the underlying cross-relational inter-dependencies. (ii) While the learned social state vector is able to model pair-wise user dependencies, it still has limited representation capacity in capturing the global social context across users. To tackle these limitations, we propose a new Social Recommendation framework with Hierarchical Graph Neural Networks (SR-HGNN). In particular, we first design a relation-aware reconstructed graph neural network to inject the cross-type collaborative semantics into the recommendation framework. In addition, we further augment SR-HGNN with a social relation encoder based on the mutual information learning paradigm between low-level user embeddings and high-level global representation, which endows SR-HGNN with the capability of capturing the global social contextual signals. Empirical results on three public benchmarks demonstrate that SR-HGNN significantly outperforms state-of-the-art recommendation methods. Source codes are available at: https://github.com/xhcdream/SR-HGNN.
Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network
Oct 08, 2021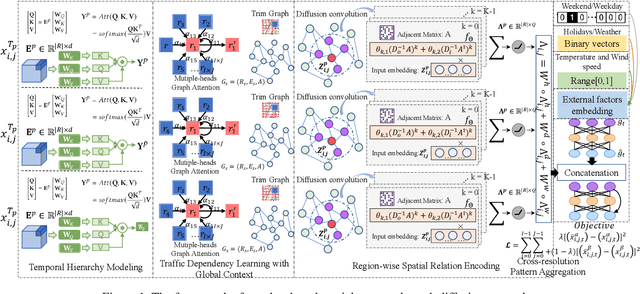
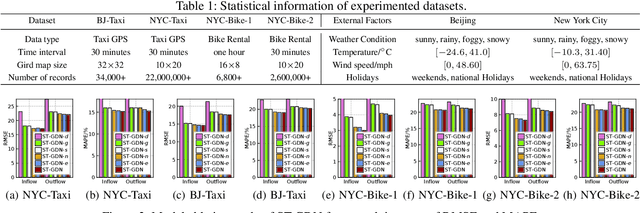
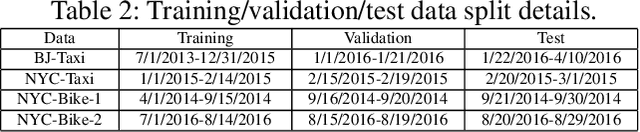
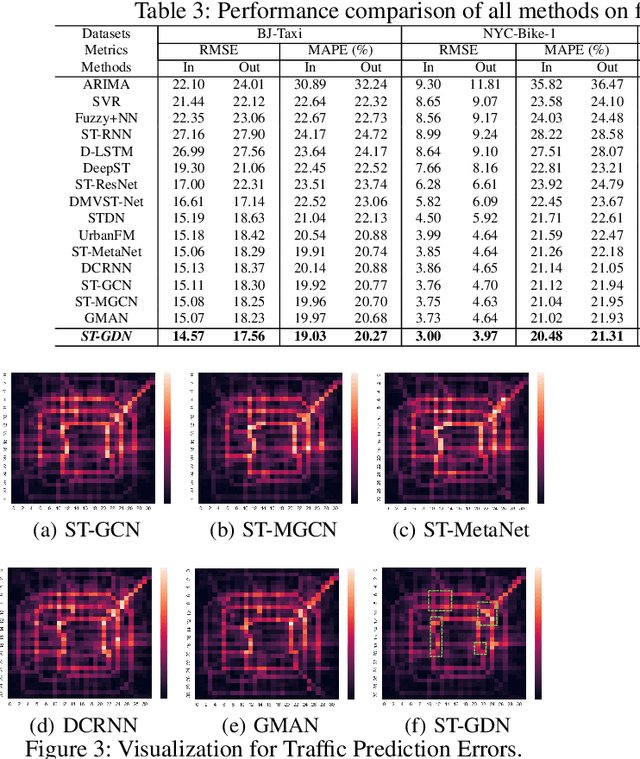
Accurate forecasting of citywide traffic flow has been playing critical role in a variety of spatial-temporal mining applications, such as intelligent traffic control and public risk assessment. While previous work has made significant efforts to learn traffic temporal dynamics and spatial dependencies, two key limitations exist in current models. First, only the neighboring spatial correlations among adjacent regions are considered in most existing methods, and the global inter-region dependency is ignored. Additionally, these methods fail to encode the complex traffic transition regularities exhibited with time-dependent and multi-resolution in nature. To tackle these challenges, we develop a new traffic prediction framework-Spatial-Temporal Graph Diffusion Network (ST-GDN). In particular, ST-GDN is a hierarchically structured graph neural architecture which learns not only the local region-wise geographical dependencies, but also the spatial semantics from a global perspective. Furthermore, a multi-scale attention network is developed to empower ST-GDN with the capability of capturing multi-level temporal dynamics. Experiments on several real-life traffic datasets demonstrate that ST-GDN outperforms different types of state-of-the-art baselines. Source codes of implementations are available at https://github.com/jill001/ST-GDN.
Multiplex Behavioral Relation Learning for Recommendation via Memory Augmented Transformer Network
Oct 08, 2021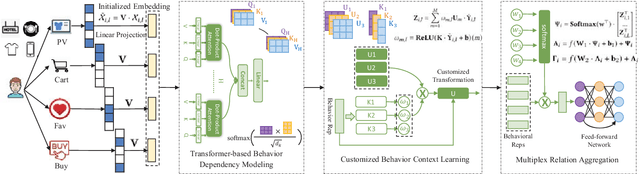

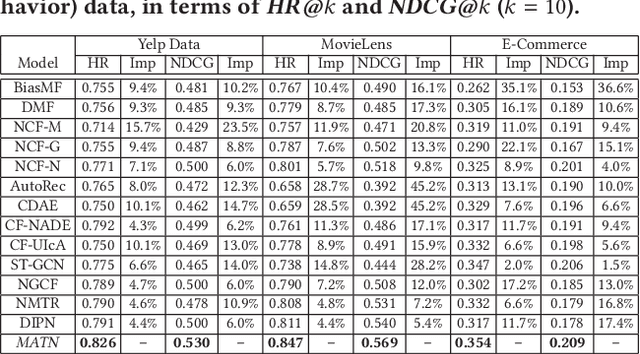
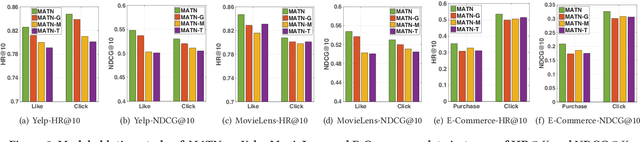
Capturing users' precise preferences is of great importance in various recommender systems (eg., e-commerce platforms), which is the basis of how to present personalized interesting product lists to individual users. In spite of significant progress has been made to consider relations between users and items, most of the existing recommendation techniques solely focus on singular type of user-item interactions. However, user-item interactive behavior is often exhibited with multi-type (e.g., page view, add-to-favorite and purchase) and inter-dependent in nature. The overlook of multiplex behavior relations can hardly recognize the multi-modal contextual signals across different types of interactions, which limit the feasibility of current recommendation methods. To tackle the above challenge, this work proposes a Memory-Augmented Transformer Networks (MATN), to enable the recommendation with multiplex behavioral relational information, and joint modeling of type-specific behavioral context and type-wise behavior inter-dependencies, in a fully automatic manner. In our MATN framework, we first develop a transformer-based multi-behavior relation encoder, to make the learned interaction representations be reflective of the cross-type behavior relations. Furthermore, a memory attention network is proposed to supercharge MATN capturing the contextual signals of different types of behavior into the category-specific latent embedding space. Finally, a cross-behavior aggregation component is introduced to promote the comprehensive collaboration across type-aware interaction behavior representations, and discriminate their inherent contributions in assisting recommendations. Extensive experiments on two benchmark datasets and a real-world e-commence user behavior data demonstrate significant improvements obtained by MATN over baselines. Codes are available at: https://github.com/akaxlh/MATN.
Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation
Oct 08, 2021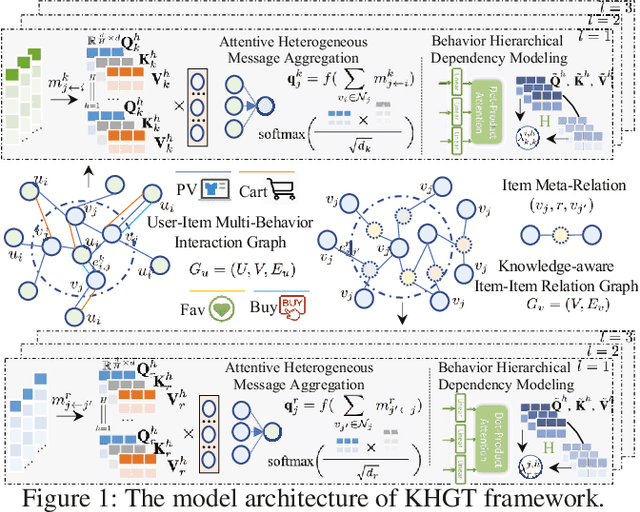

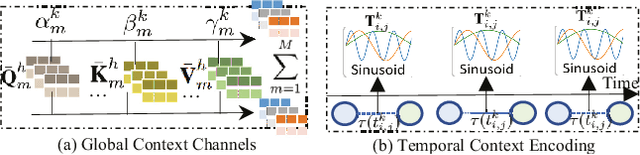
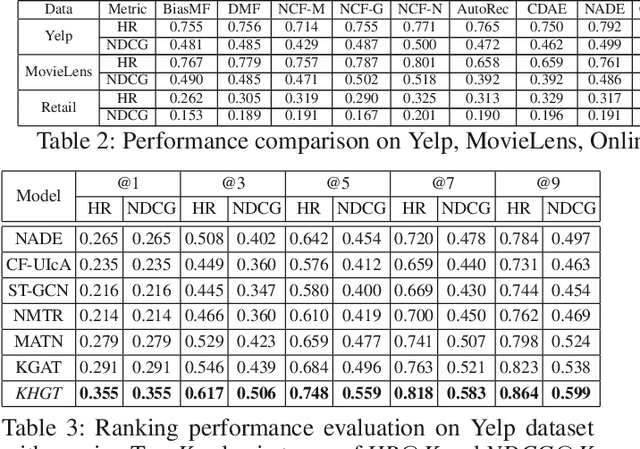
Accurate user and item embedding learning is crucial for modern recommender systems. However, most existing recommendation techniques have thus far focused on modeling users' preferences over singular type of user-item interactions. Many practical recommendation scenarios involve multi-typed user interactive behaviors (e.g., page view, add-to-favorite and purchase), which presents unique challenges that cannot be handled by current recommendation solutions. In particular: i) complex inter-dependencies across different types of user behaviors; ii) the incorporation of knowledge-aware item relations into the multi-behavior recommendation framework; iii) dynamic characteristics of multi-typed user-item interactions. To tackle these challenges, this work proposes a Knowledge-Enhanced Hierarchical Graph Transformer Network (KHGT), to investigate multi-typed interactive patterns between users and items in recommender systems. Specifically, KHGT is built upon a graph-structured neural architecture to i) capture type-specific behavior characteristics; ii) explicitly discriminate which types of user-item interactions are more important in assisting the forecasting task on the target behavior. Additionally, we further integrate the graph attention layer with the temporal encoding strategy, to empower the learned embeddings be reflective of both dedicated multiplex user-item and item-item relations, as well as the underlying interaction dynamics. Extensive experiments conducted on three real-world datasets show that KHGT consistently outperforms many state-of-the-art recommendation methods across various evaluation settings. Our implementation code is available at https://github.com/akaxlh/KHGT.
Graph-Enhanced Multi-Task Learning of Multi-Level Transition Dynamics for Session-based Recommendation
Oct 08, 2021
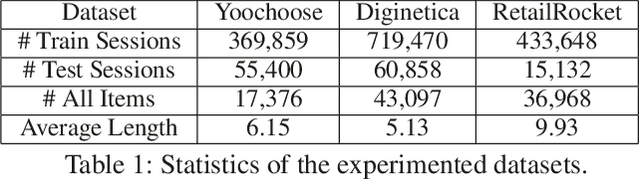

Session-based recommendation plays a central role in a wide spectrum of online applications, ranging from e-commerce to online advertising services. However, the majority of existing session-based recommendation techniques (e.g., attention-based recurrent network or graph neural network) are not well-designed for capturing the complex transition dynamics exhibited with temporally-ordered and multi-level inter-dependent relation structures. These methods largely overlook the relation hierarchy of item transitional patterns. In this paper, we propose a multi-task learning framework with Multi-level Transition Dynamics (MTD), which enables the jointly learning of intra- and inter-session item transition dynamics in automatic and hierarchical manner. Towards this end, we first develop a position-aware attention mechanism to learn item transitional regularities within individual session. Then, a graph-structured hierarchical relation encoder is proposed to explicitly capture the cross-session item transitions in the form of high-order connectivities by performing embedding propagation with the global graph context. The learning process of intra- and inter-session transition dynamics are integrated, to preserve the underlying low- and high-level item relationships in a common latent space. Extensive experiments on three real-world datasets demonstrate the superiority of MTD as compared to state-of-the-art baselines.
Knowledge-aware Coupled Graph Neural Network for Social Recommendation
Oct 08, 2021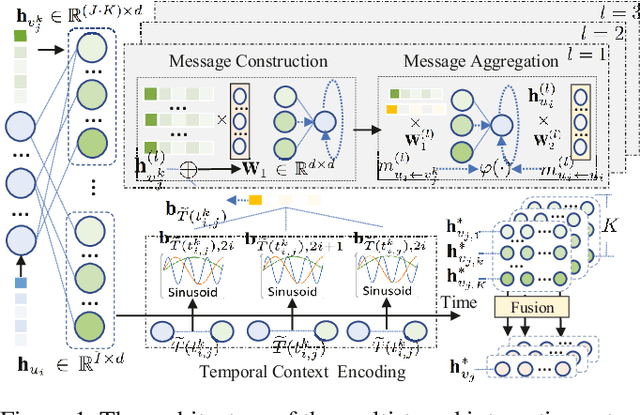

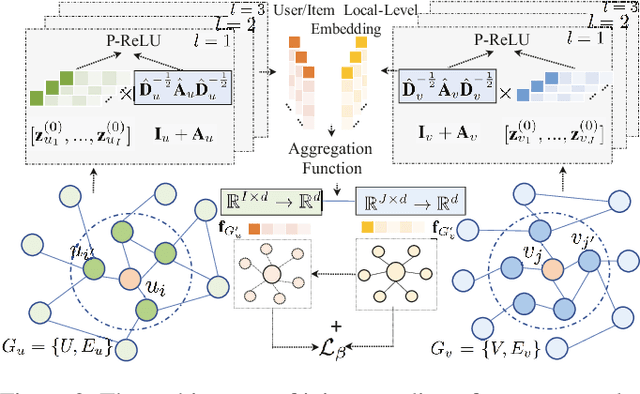

Social recommendation task aims to predict users' preferences over items with the incorporation of social connections among users, so as to alleviate the sparse issue of collaborative filtering. While many recent efforts show the effectiveness of neural network-based social recommender systems, several important challenges have not been well addressed yet: (i) The majority of models only consider users' social connections, while ignoring the inter-dependent knowledge across items; (ii) Most of existing solutions are designed for singular type of user-item interactions, making them infeasible to capture the interaction heterogeneity; (iii) The dynamic nature of user-item interactions has been less explored in many social-aware recommendation techniques. To tackle the above challenges, this work proposes a Knowledge-aware Coupled Graph Neural Network (KCGN) that jointly injects the inter-dependent knowledge across items and users into the recommendation framework. KCGN enables the high-order user- and item-wise relation encoding by exploiting the mutual information for global graph structure awareness. Additionally, we further augment KCGN with the capability of capturing dynamic multi-typed user-item interactive patterns. Experimental studies on real-world datasets show the effectiveness of our method against many strong baselines in a variety of settings. Source codes are available at: https://github.com/xhcdream/KCGN.
Graph Meta Network for Multi-Behavior Recommendation
Oct 08, 2021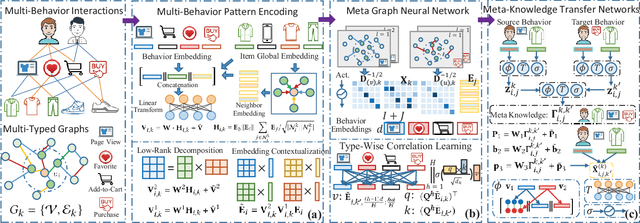

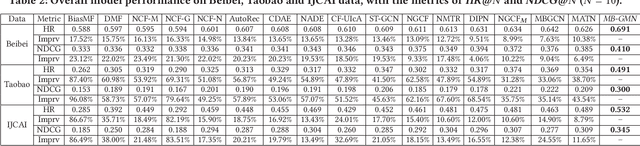
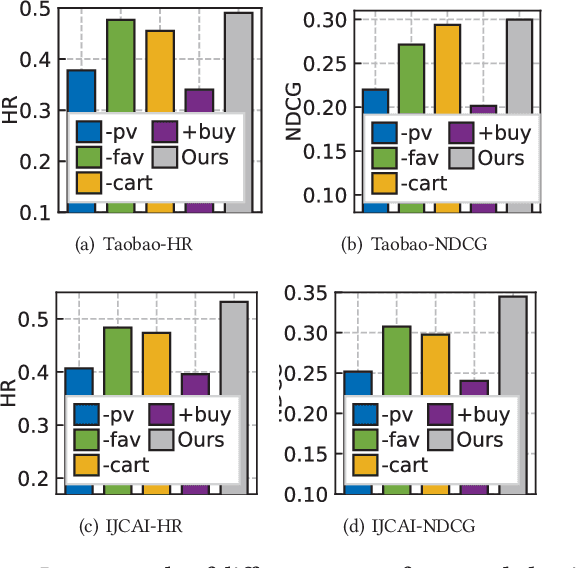
Modern recommender systems often embed users and items into low-dimensional latent representations, based on their observed interactions. In practical recommendation scenarios, users often exhibit various intents which drive them to interact with items with multiple behavior types (e.g., click, tag-as-favorite, purchase). However, the diversity of user behaviors is ignored in most of the existing approaches, which makes them difficult to capture heterogeneous relational structures across different types of interactive behaviors. Exploring multi-typed behavior patterns is of great importance to recommendation systems, yet is very challenging because of two aspects: i) The complex dependencies across different types of user-item interactions; ii) Diversity of such multi-behavior patterns may vary by users due to their personalized preference. To tackle the above challenges, we propose a Multi-Behavior recommendation framework with Graph Meta Network to incorporate the multi-behavior pattern modeling into a meta-learning paradigm. Our developed MB-GMN empowers the user-item interaction learning with the capability of uncovering type-dependent behavior representations, which automatically distills the behavior heterogeneity and interaction diversity for recommendations. Extensive experiments on three real-world datasets show the effectiveness of MB-GMN by significantly boosting the recommendation performance as compared to various state-of-the-art baselines. The source code is available athttps://github.com/akaxlh/MB-GMN.