 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi- and Weakly-Supervised Domain Generalization for Object Detection
Oct 30, 2023Object detectors do not work well when domains largely differ between training and testing data. To solve this problem, domain generalization approaches, which require training data with ground-truth labels from multiple domains, have been proposed. However, it is time-consuming and labor-intensive to collect those data for object detection because not only class labels but also bounding boxes must be annotated. To overcome the problem of domain gap in object detection without requiring expensive annotations, we propose to consider two new problem settings: semi-supervised domain generalizable object detection (SS-DGOD) and weakly-supervised DGOD (WS-DGOD). In contrast to the conventional domain generalization for object detection that requires labeled data from multiple domains, SS-DGOD and WS-DGOD require labeled data only from one domain and unlabeled or weakly-labeled data from multiple domains for training. We show that object detectors can be effectively trained on the proposed settings with the same student-teacher learning framework, where a student network is trained with pseudo labels output from a teacher on the unlabeled or weakly-labeled data. The experimental results demonstrate that the object detectors trained on the proposed settings significantly outperform baseline detectors trained on one labeled domain data and perform comparably to or better than those trained on unsupervised domain adaptation (UDA) settings, while ours do not use target domain data for training in contrast to UDA.
Image Cropping under Design Constraints
Oct 13, 2023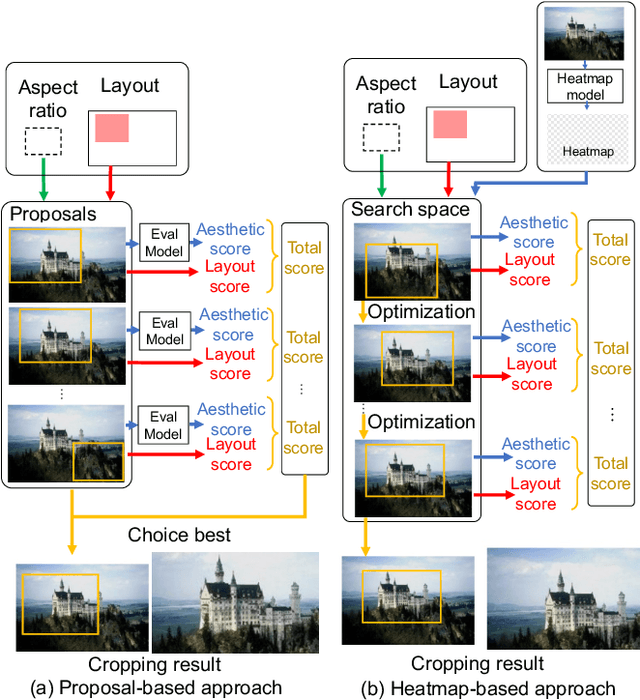
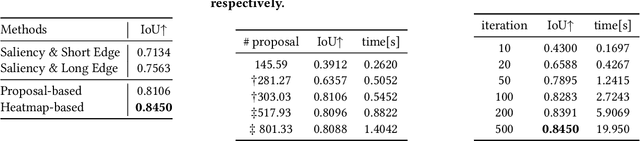

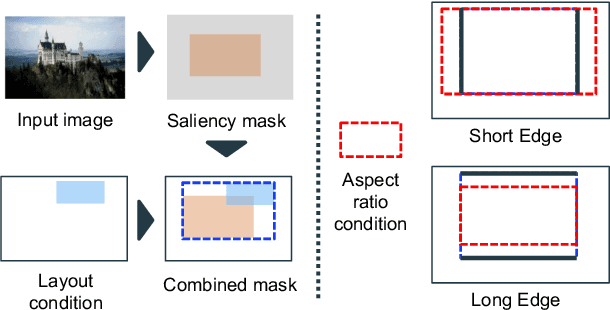
Image cropping is essential in image editing for obtaining a compositionally enhanced image. In display media, image cropping is a prospective technique for automatically creating media content. However, image cropping for media contents is often required to satisfy various constraints, such as an aspect ratio and blank regions for placing texts or objects. We call this problem image cropping under design constraints. To achieve image cropping under design constraints, we propose a score function-based approach, which computes scores for cropped results whether aesthetically plausible and satisfies design constraints. We explore two derived approaches, a proposal-based approach, and a heatmap-based approach, and we construct a dataset for evaluating the performance of the proposed approaches on image cropping under design constraints. In experiments, we demonstrate that the proposed approaches outperform a baseline, and we observe that the proposal-based approach is better than the heatmap-based approach under the same computation cost, but the heatmap-based approach leads to better scores by increasing computation cost. The experimental results indicate that balancing aesthetically plausible regions and satisfying design constraints is not a trivial problem and requires sensitive balance, and both proposed approaches are reasonable alternatives.
Proposal-based Temporal Action Localization with Point-level Supervision
Oct 09, 2023



Point-level supervised temporal action localization (PTAL) aims at recognizing and localizing actions in untrimmed videos where only a single point (frame) within every action instance is annotated in training data. Without temporal annotations, most previous works adopt the multiple instance learning (MIL) framework, where the input video is segmented into non-overlapped short snippets, and action classification is performed independently on every short snippet. We argue that the MIL framework is suboptimal for PTAL because it operates on separated short snippets that contain limited temporal information. Therefore, the classifier only focuses on several easy-to-distinguish snippets instead of discovering the whole action instance without missing any relevant snippets. To alleviate this problem, we propose a novel method that localizes actions by generating and evaluating action proposals of flexible duration that involve more comprehensive temporal information. Moreover, we introduce an efficient clustering algorithm to efficiently generate dense pseudo labels that provide stronger supervision, and a fine-grained contrastive loss to further refine the quality of pseudo labels. Experiments show that our proposed method achieves competitive or superior performance to the state-of-the-art methods and some fully-supervised methods on four benchmarks: ActivityNet 1.3, THUMOS 14, GTEA, and BEOID datasets.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Structural Multiplane Image: Bridging Neural View Synthesis and 3D Reconstruction
Mar 10, 2023



The Multiplane Image (MPI), containing a set of fronto-parallel RGBA layers, is an effective and efficient representation for view synthesis from sparse inputs. Yet, its fixed structure limits the performance, especially for surfaces imaged at oblique angles. We introduce the Structural MPI (S-MPI), where the plane structure approximates 3D scenes concisely. Conveying RGBA contexts with geometrically-faithful structures, the S-MPI directly bridges view synthesis and 3D reconstruction. It can not only overcome the critical limitations of MPI, i.e., discretization artifacts from sloped surfaces and abuse of redundant layers, and can also acquire planar 3D reconstruction. Despite the intuition and demand of applying S-MPI, great challenges are introduced, e.g., high-fidelity approximation for both RGBA layers and plane poses, multi-view consistency, non-planar regions modeling, and efficient rendering with intersected planes. Accordingly, we propose a transformer-based network based on a segmentation model. It predicts compact and expressive S-MPI layers with their corresponding masks, poses, and RGBA contexts. Non-planar regions are inclusively handled as a special case in our unified framework. Multi-view consistency is ensured by sharing global proxy embeddings, which encode plane-level features covering the complete 3D scenes with aligned coordinates. Intensive experiments show that our method outperforms both previous state-of-the-art MPI-based view synthesis methods and planar reconstruction methods.
Fine-grained Affordance Annotation for Egocentric Hand-Object Interaction Videos
Feb 10, 2023



Object affordance is an important concept in hand-object interaction, providing information on action possibilities based on human motor capacity and objects' physical property thus benefiting tasks such as action anticipation and robot imitation learning. However, the definition of affordance in existing datasets often: 1) mix up affordance with object functionality; 2) confuse affordance with goal-related action; and 3) ignore human motor capacity. This paper proposes an efficient annotation scheme to address these issues by combining goal-irrelevant motor actions and grasp types as affordance labels and introducing the concept of mechanical action to represent the action possibilities between two objects. We provide new annotations by applying this scheme to the EPIC-KITCHENS dataset and test our annotation with tasks such as affordance recognition, hand-object interaction hotspots prediction, and cross-domain evaluation of affordance. The results show that models trained with our annotation can distinguish affordance from other concepts, predict fine-grained interaction possibilities on objects, and generalize through different domains.
ClipCrop: Conditioned Cropping Driven by Vision-Language Model
Nov 21, 2022



Image cropping has progressed tremendously under the data-driven paradigm. However, current approaches do not account for the intentions of the user, which is an issue especially when the composition of the input image is complex. Moreover, labeling of cropping data is costly and hence the amount of data is limited, leading to poor generalization performance of current algorithms in the wild. In this work, we take advantage of vision-language models as a foundation for creating robust and user-intentional cropping algorithms. By adapting a transformer decoder with a pre-trained CLIP-based detection model, OWL-ViT, we develop a method to perform cropping with a text or image query that reflects the user's intention as guidance. In addition, our pipeline design allows the model to learn text-conditioned aesthetic cropping with a small cropping dataset, while inheriting the open-vocabulary ability acquired from millions of text-image pairs. We validate our model through extensive experiments on existing datasets as well as a new cropping test set we compiled that is characterized by content ambiguity.
Surgical Skill Assessment via Video Semantic Aggregation
Aug 04, 2022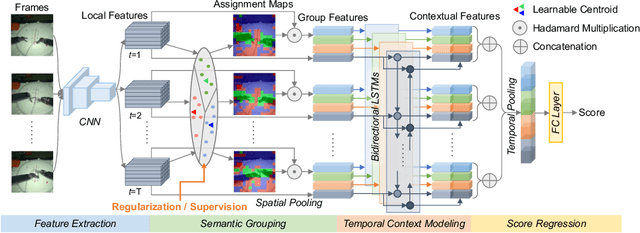
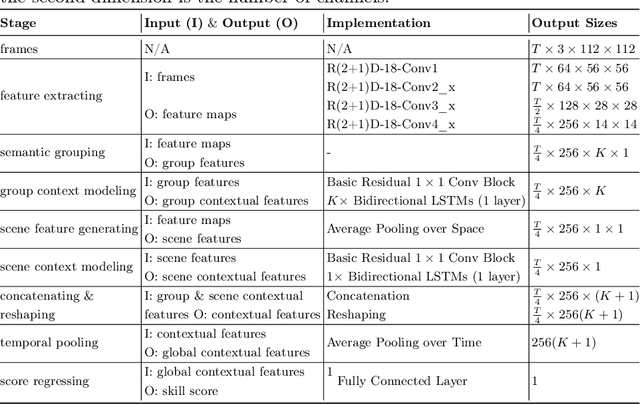
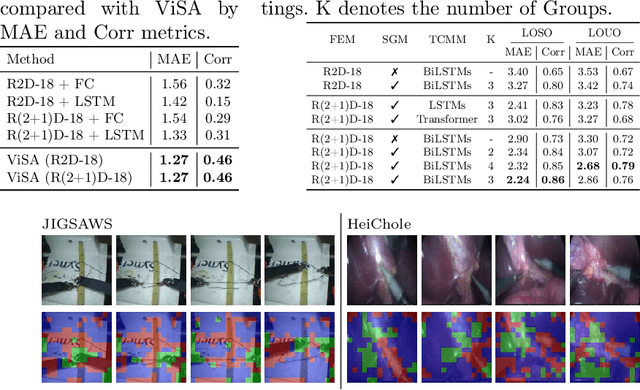
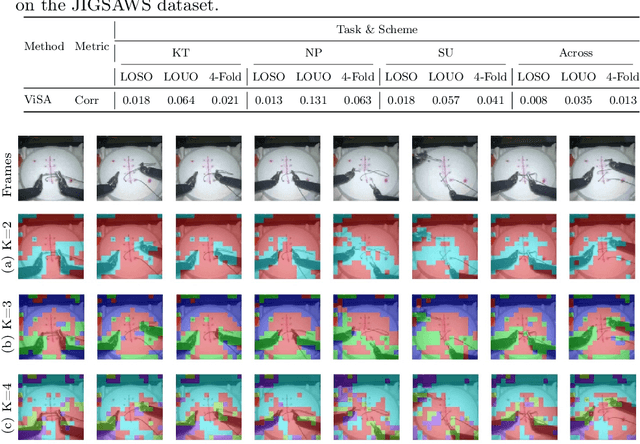
Automated video-based assessment of surgical skills is a promising task in assisting young surgical trainees, especially in poor-resource areas. Existing works often resort to a CNN-LSTM joint framework that models long-term relationships by LSTMs on spatially pooled short-term CNN features. However, this practice would inevitably neglect the difference among semantic concepts such as tools, tissues, and background in the spatial dimension, impeding the subsequent temporal relationship modeling. In this paper, we propose a novel skill assessment framework, Video Semantic Aggregation (ViSA), which discovers different semantic parts and aggregates them across spatiotemporal dimensions. The explicit discovery of semantic parts provides an explanatory visualization that helps understand the neural network's decisions. It also enables us to further incorporate auxiliary information such as the kinematic data to improve representation learning and performance. The experiments on two datasets show the competitiveness of ViSA compared to state-of-the-art methods. Source code is available at: bit.ly/MICCAI2022ViSA.
CompNVS: Novel View Synthesis with Scene Completion
Jul 23, 2022

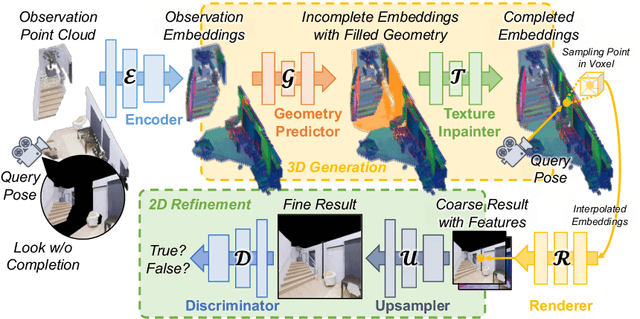

We introduce a scalable framework for novel view synthesis from RGB-D images with largely incomplete scene coverage. While generative neural approaches have demonstrated spectacular results on 2D images, they have not yet achieved similar photorealistic results in combination with scene completion where a spatial 3D scene understanding is essential. To this end, we propose a generative pipeline performing on a sparse grid-based neural scene representation to complete unobserved scene parts via a learned distribution of scenes in a 2.5D-3D-2.5D manner. We process encoded image features in 3D space with a geometry completion network and a subsequent texture inpainting network to extrapolate the missing area. Photorealistic image sequences can be finally obtained via consistency-relevant differentiable rendering. Comprehensive experiments show that the graphical outputs of our method outperform the state of the art, especially within unobserved scene parts.
Compound Prototype Matching for Few-shot Action Recognition
Jul 19, 2022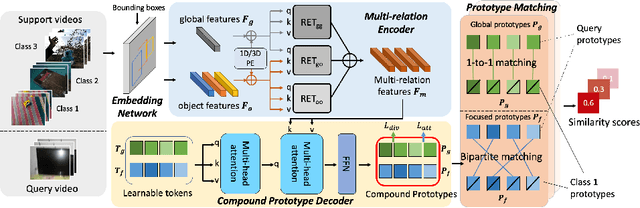
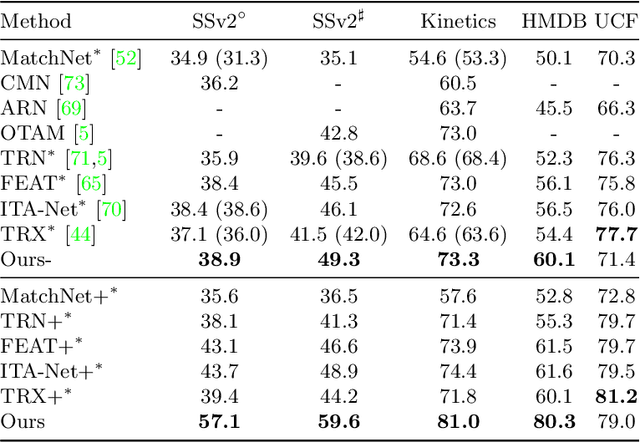
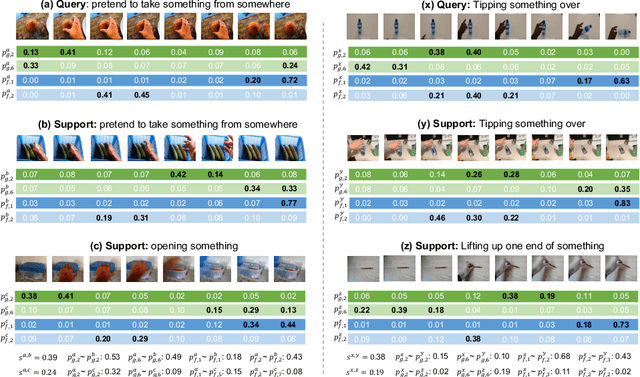
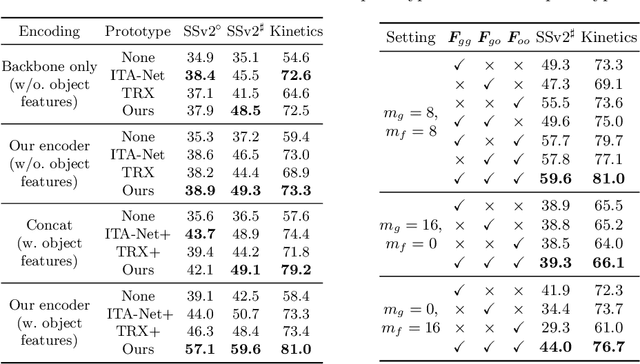
Few-shot action recognition aims to recognize novel action classes using only a small number of labeled training samples. In this work, we propose a novel approach that first summarizes each video into compound prototypes consisting of a group of global prototypes and a group of focused prototypes, and then compares video similarity based on the prototypes. Each global prototype is encouraged to summarize a specific aspect from the entire video, for example, the start/evolution of the action. Since no clear annotation is provided for the global prototypes, we use a group of focused prototypes to focus on certain timestamps in the video. We compare video similarity by matching the compound prototypes between the support and query videos. The global prototypes are directly matched to compare videos from the same perspective, for example, to compare whether two actions start similarly. For the focused prototypes, since actions have various temporal variations in the videos, we apply bipartite matching to allow the comparison of actions with different temporal positions and shifts. Experiments demonstrate that our proposed method achieves state-of-the-art results on multiple benchmarks.