 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-time Trajectory Optimization for Manga Image Editing
Mar 29, 2026We present an inference-time adaptation method that tailors a pretrained image editing model to each input manga image using only the input image itself. Despite recent progress in pretrained image editing, such models often underperform on manga because they are trained predominantly on natural-image data. Re-training or fine-tuning large-scale models on manga is, however, generally impractical due to both computational cost and copyright constraints. To address this issue, our method slightly corrects the generation trajectory at inference time so that the input image can be reconstructed more faithfully under an empty prompt. Experimental results show that our method consistently outperforms existing baselines while incurring only negligible computational overhead.
Affordance-Guided Diffusion Prior for 3D Hand Reconstruction
Oct 01, 2025

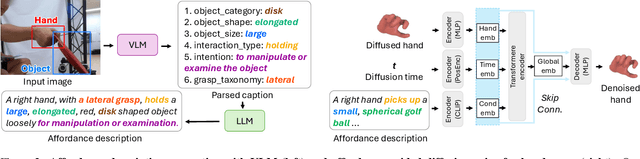

How can we reconstruct 3D hand poses when large portions of the hand are heavily occluded by itself or by objects? Humans often resolve such ambiguities by leveraging contextual knowledge -- such as affordances, where an object's shape and function suggest how the object is typically grasped. Inspired by this observation, we propose a generative prior for hand pose refinement guided by affordance-aware textual descriptions of hand-object interactions (HOI). Our method employs a diffusion-based generative model that learns the distribution of plausible hand poses conditioned on affordance descriptions, which are inferred from a large vision-language model (VLM). This enables the refinement of occluded regions into more accurate and functionally coherent hand poses. Extensive experiments on HOGraspNet, a 3D hand-affordance dataset with severe occlusions, demonstrate that our affordance-guided refinement significantly improves hand pose estimation over both recent regression methods and diffusion-based refinement lacking contextual reasoning.
EgoInstruct: An Egocentric Video Dataset of Face-to-face Instructional Interactions with Multi-modal LLM Benchmarking
Sep 26, 2025Analyzing instructional interactions between an instructor and a learner who are co-present in the same physical space is a critical problem for educational support and skill transfer. Yet such face-to-face instructional scenes have not been systematically studied in computer vision. We identify two key reasons: i) the lack of suitable datasets and ii) limited analytical techniques. To address this gap, we present a new egocentric video dataset of face-to-face instruction and provide ground-truth annotations for two fundamental tasks that serve as a first step toward a comprehensive understanding of instructional interactions: procedural step segmentation and conversation-state classification. Using this dataset, we benchmark multimodal large language models (MLLMs) against conventional task-specific models. Since face-to-face instruction involves multiple modalities (speech content and prosody, gaze and body motion, and visual context), effective understanding requires methods that handle verbal and nonverbal communication in an integrated manner. Accordingly, we evaluate recently introduced MLLMs that jointly process images, audio, and text. This evaluation quantifies the extent to which current machine learning models understand face-to-face instructional scenes. In experiments, MLLMs outperform specialized baselines even without task-specific fine-tuning, suggesting their promise for holistic understanding of instructional interactions.
Leadership Assessment in Pediatric Intensive Care Unit Team Training
May 30, 2025This paper addresses the task of assessing PICU team's leadership skills by developing an automated analysis framework based on egocentric vision. We identify key behavioral cues, including fixation object, eye contact, and conversation patterns, as essential indicators of leadership assessment. In order to capture these multimodal signals, we employ Aria Glasses to record egocentric video, audio, gaze, and head movement data. We collect one-hour videos of four simulated sessions involving doctors with different roles and levels. To automate data processing, we propose a method leveraging REMoDNaV, SAM, YOLO, and ChatGPT for fixation object detection, eye contact detection, and conversation classification. In the experiments, significant correlations are observed between leadership skills and behavioral metrics, i.e., the output of our proposed methods, such as fixation time, transition patterns, and direct orders in speech. These results indicate that our proposed data collection and analysis framework can effectively solve skill assessment for training PICU teams.
SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
Feb 21, 2025



We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.
Learning Gaussian Data Augmentation in Feature Space for One-shot Object Detection in Manga
Oct 08, 2024We tackle one-shot object detection in Japanese Manga. The rising global popularity of Japanese manga has made the object detection of character faces increasingly important, with potential applications such as automatic colorization. However, obtaining sufficient data for training conventional object detectors is challenging due to copyright restrictions. Additionally, new characters appear every time a new volume of manga is released, making it impractical to re-train object detectors each time to detect these new characters. Therefore, one-shot object detection, where only a single query (reference) image is required to detect a new character, is an essential task in the manga industry. One challenge with one-shot object detection in manga is the large variation in the poses and facial expressions of characters in target images, despite having only one query image as a reference. Another challenge is that the frequency of character appearances follows a long-tail distribution. To overcome these challenges, we propose a data augmentation method in feature space to increase the variation of the query. The proposed method augments the feature from the query by adding Gaussian noise, with the noise variance at each channel learned during training. The experimental results show that the proposed method improves the performance for both seen and unseen classes, surpassing data augmentation methods in image space.
Pre-Training for 3D Hand Pose Estimation with Contrastive Learning on Large-Scale Hand Images in the Wild
Sep 15, 2024



We present a contrastive learning framework based on in-the-wild hand images tailored for pre-training 3D hand pose estimators, dubbed HandCLR. Pre-training on large-scale images achieves promising results in various tasks, but prior 3D hand pose pre-training methods have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our method with contrastive learning. Specifically, we collected over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands; pairs of similar hand poses originating from different samples, and propose a novel contrastive learning method that embeds similar hand pairs closer in the latent space. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands.
ActionVOS: Actions as Prompts for Video Object Segmentation
Jul 10, 2024



Delving into the realm of egocentric vision, the advancement of referring video object segmentation (RVOS) stands as pivotal in understanding human activities. However, existing RVOS task primarily relies on static attributes such as object names to segment target objects, posing challenges in distinguishing target objects from background objects and in identifying objects undergoing state changes. To address these problems, this work proposes a novel action-aware RVOS setting called ActionVOS, aiming at segmenting only active objects in egocentric videos using human actions as a key language prompt. This is because human actions precisely describe the behavior of humans, thereby helping to identify the objects truly involved in the interaction and to understand possible state changes. We also build a method tailored to work under this specific setting. Specifically, we develop an action-aware labeling module with an efficient action-guided focal loss. Such designs enable ActionVOS model to prioritize active objects with existing readily-available annotations. Experimental results on VISOR dataset reveal that ActionVOS significantly reduces the mis-segmentation of inactive objects, confirming that actions help the ActionVOS model understand objects' involvement. Further evaluations on VOST and VSCOS datasets show that the novel ActionVOS setting enhances segmentation performance when encountering challenging circumstances involving object state changes. We will make our implementation available at https://github.com/ut-vision/ActionVOS.
Learning Object States from Actions via Large Language Models
May 02, 2024



Temporally localizing the presence of object states in videos is crucial in understanding human activities beyond actions and objects. This task has suffered from a lack of training data due to object states' inherent ambiguity and variety. To avoid exhaustive annotation, learning from transcribed narrations in instructional videos would be intriguing. However, object states are less described in narrations compared to actions, making them less effective. In this work, we propose to extract the object state information from action information included in narrations, using large language models (LLMs). Our observation is that LLMs include world knowledge on the relationship between actions and their resulting object states, and can infer the presence of object states from past action sequences. The proposed LLM-based framework offers flexibility to generate plausible pseudo-object state labels against arbitrary categories. We evaluate our method with our newly collected Multiple Object States Transition (MOST) dataset including dense temporal annotation of 60 object state categories. Our model trained by the generated pseudo-labels demonstrates significant improvement of over 29% in mAP against strong zero-shot vision-language models, showing the effectiveness of explicitly extracting object state information from actions through LLMs.
FineBio: A Fine-Grained Video Dataset of Biological Experiments with Hierarchical Annotation
Feb 01, 2024



In the development of science, accurate and reproducible documentation of the experimental process is crucial. Automatic recognition of the actions in experiments from videos would help experimenters by complementing the recording of experiments. Towards this goal, we propose FineBio, a new fine-grained video dataset of people performing biological experiments. The dataset consists of multi-view videos of 32 participants performing mock biological experiments with a total duration of 14.5 hours. One experiment forms a hierarchical structure, where a protocol consists of several steps, each further decomposed into a set of atomic operations. The uniqueness of biological experiments is that while they require strict adherence to steps described in each protocol, there is freedom in the order of atomic operations. We provide hierarchical annotation on protocols, steps, atomic operations, object locations, and their manipulation states, providing new challenges for structured activity understanding and hand-object interaction recognition. To find out challenges on activity understanding in biological experiments, we introduce baseline models and results on four different tasks, including (i) step segmentation, (ii) atomic operation detection (iii) object detection, and (iv) manipulated/affected object detection. Dataset and code are available from https://github.com/aistairc/FineBio.