 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022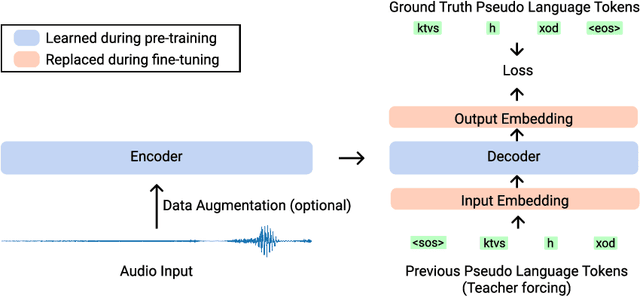

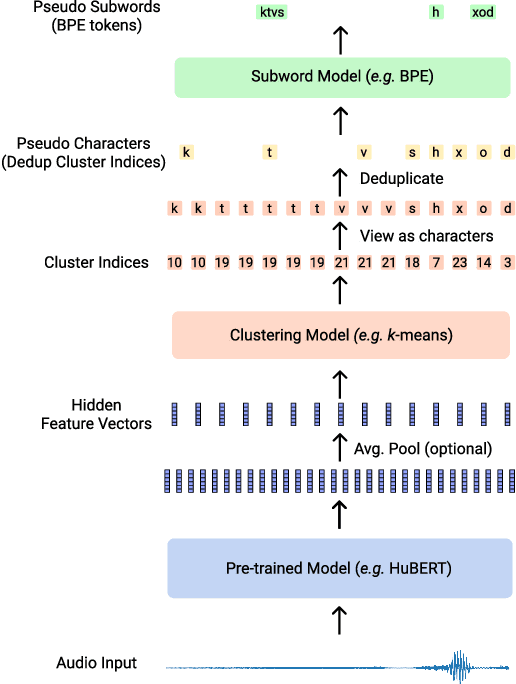
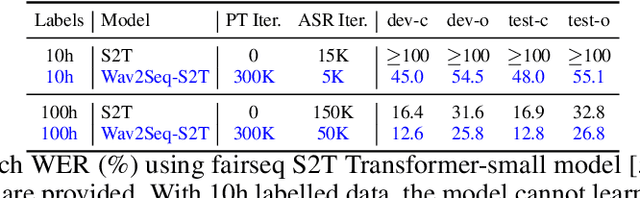
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.
Simulating Bandit Learning from User Feedback for Extractive Question Answering
Mar 18, 2022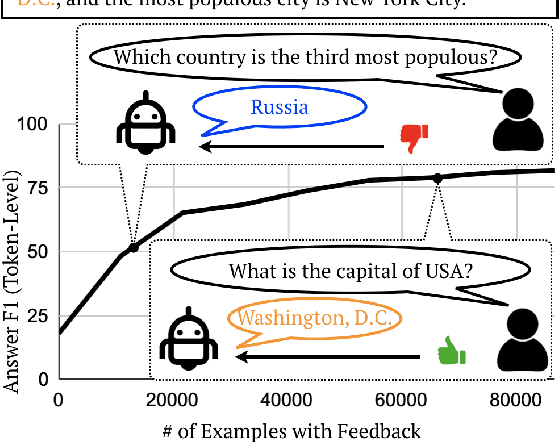

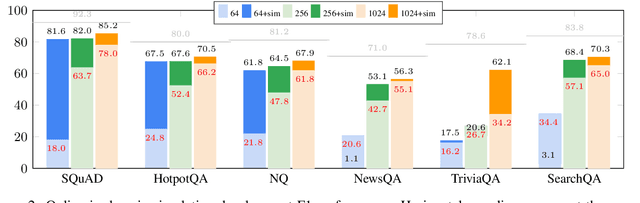
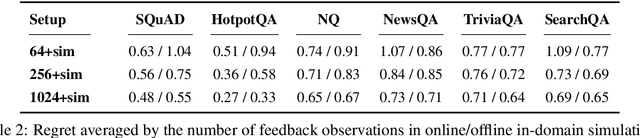
We study learning from user feedback for extractive question answering by simulating feedback using supervised data. We cast the problem as contextual bandit learning, and analyze the characteristics of several learning scenarios with focus on reducing data annotation. We show that systems initially trained on a small number of examples can dramatically improve given feedback from users on model-predicted answers, and that one can use existing datasets to deploy systems in new domains without any annotation, but instead improving the system on-the-fly via user feedback.
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021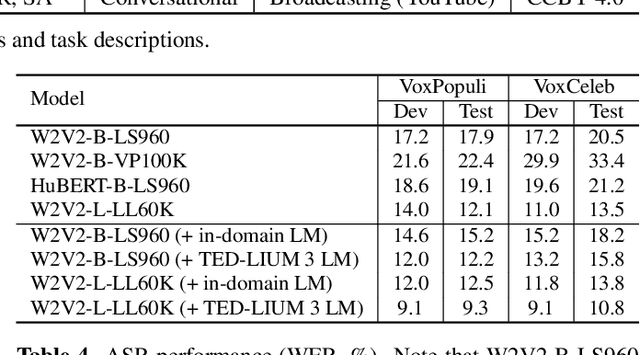
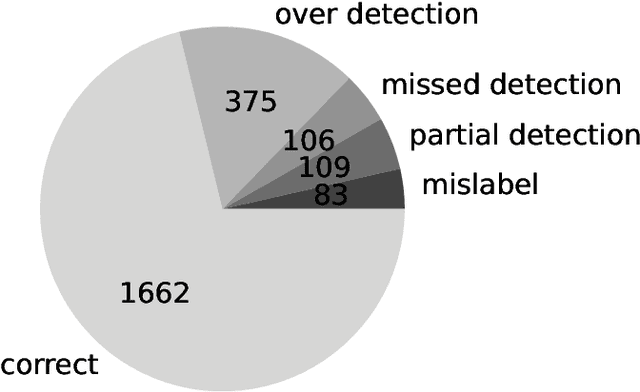
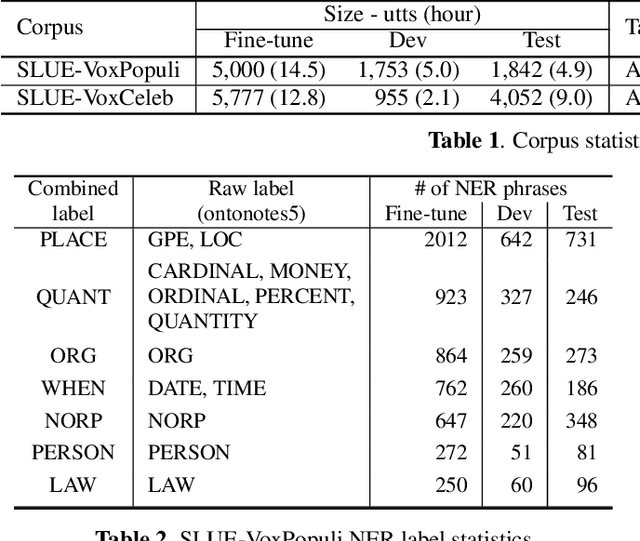
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
When in Doubt: Improving Classification Performance with Alternating Normalization
Sep 28, 2021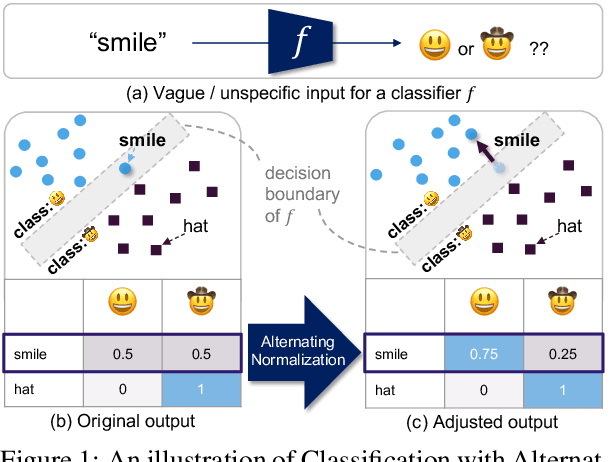
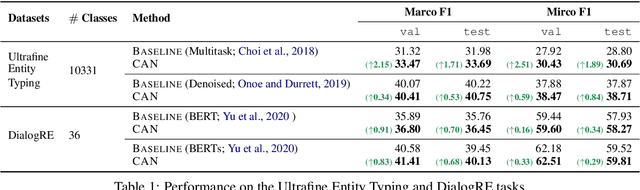
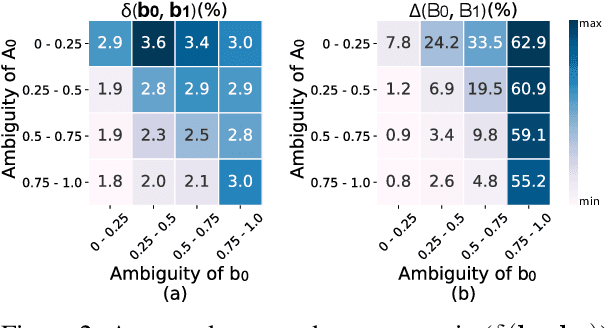
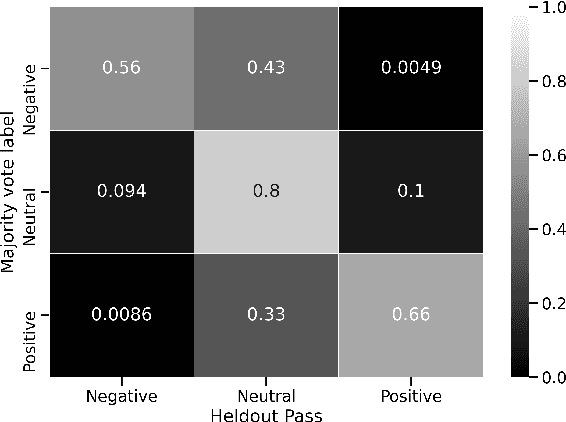
We introduce Classification with Alternating Normalization (CAN), a non-parametric post-processing step for classification. CAN improves classification accuracy for challenging examples by re-adjusting their predicted class probability distribution using the predicted class distributions of high-confidence validation examples. CAN is easily applicable to any probabilistic classifier, with minimal computation overhead. We analyze the properties of CAN using simulated experiments, and empirically demonstrate its effectiveness across a diverse set of classification tasks.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021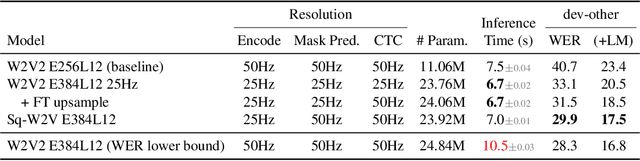
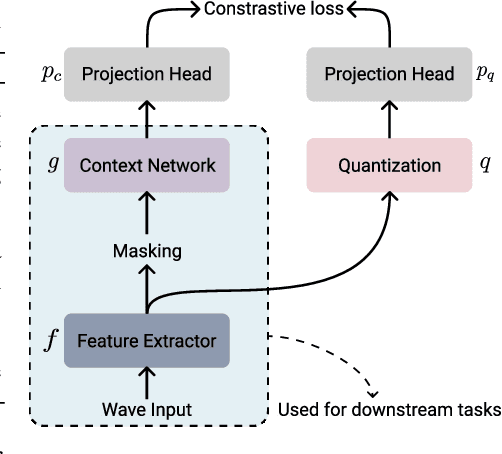
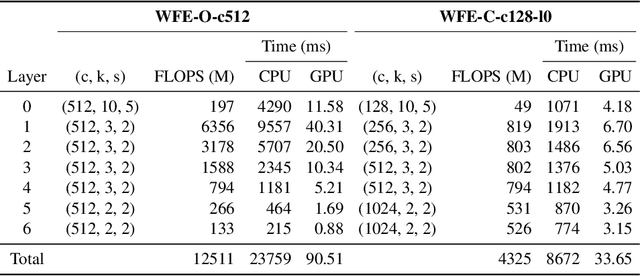
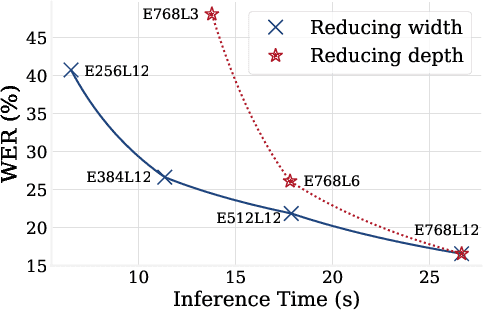
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Analysis of Language Change in Collaborative Instruction Following
Sep 09, 2021
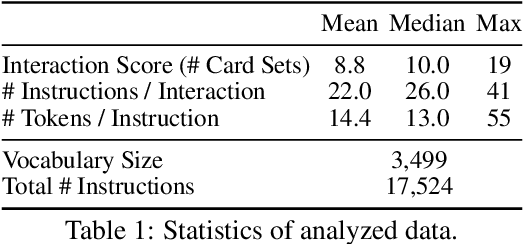
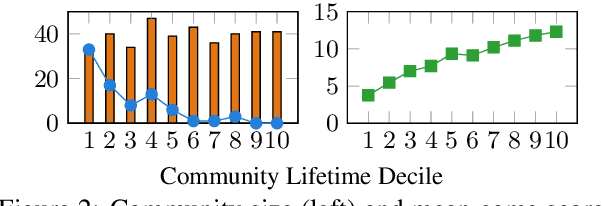
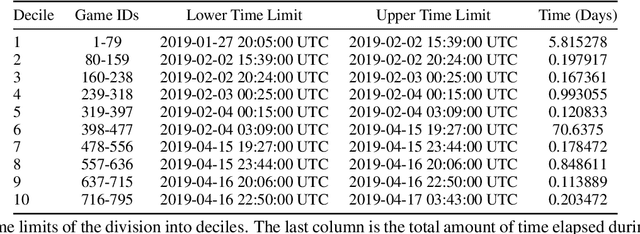
We analyze language change over time in a collaborative, goal-oriented instructional task, where utility-maximizing participants form conventions and increase their expertise. Prior work studied such scenarios mostly in the context of reference games, and consistently found that language complexity is reduced along multiple dimensions, such as utterance length, as conventions are formed. In contrast, we find that, given the ability to increase instruction utility, instructors increase language complexity along these previously studied dimensions to better collaborate with increasingly skilled instruction followers.
Who's Waldo? Linking People Across Text and Images
Aug 17, 2021

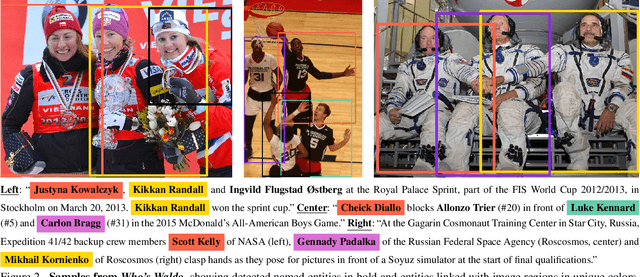
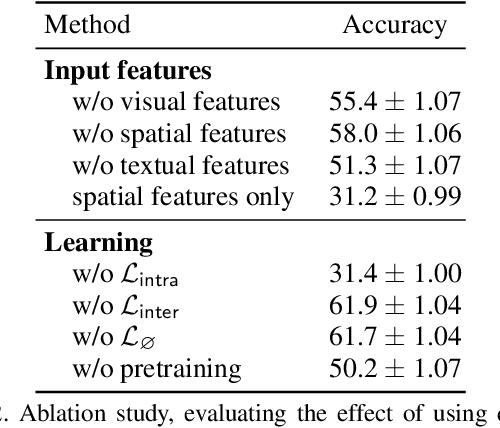
We present a task and benchmark dataset for person-centric visual grounding, the problem of linking between people named in a caption and people pictured in an image. In contrast to prior work in visual grounding, which is predominantly object-based, our new task masks out the names of people in captions in order to encourage methods trained on such image-caption pairs to focus on contextual cues (such as rich interactions between multiple people), rather than learning associations between names and appearances. To facilitate this task, we introduce a new dataset, Who's Waldo, mined automatically from image-caption data on Wikimedia Commons. We propose a Transformer-based method that outperforms several strong baselines on this task, and are releasing our data to the research community to spur work on contextual models that consider both vision and language.
Continual Learning for Grounded Instruction Generation by Observing Human Following Behavior
Aug 10, 2021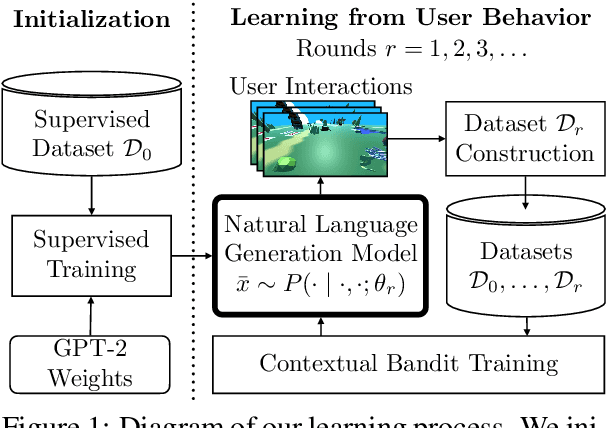

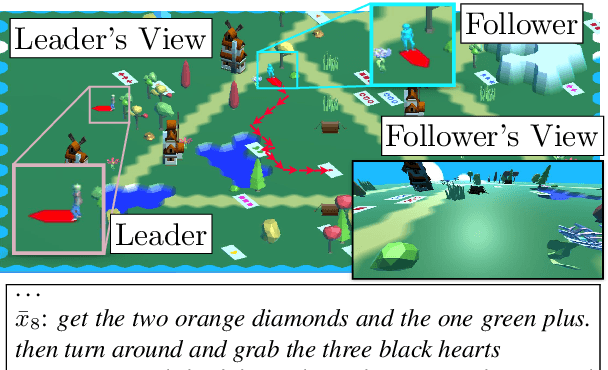
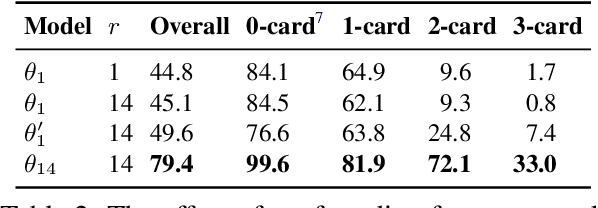
We study continual learning for natural language instruction generation, by observing human users' instruction execution. We focus on a collaborative scenario, where the system both acts and delegates tasks to human users using natural language. We compare user execution of generated instructions to the original system intent as an indication to the system's success communicating its intent. We show how to use this signal to improve the system's ability to generate instructions via contextual bandit learning. In interaction with real users, our system demonstrates dramatic improvements in its ability to generate language over time.
A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution
Jul 12, 2021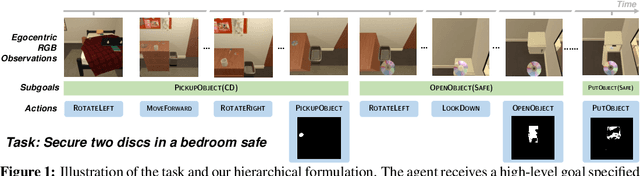
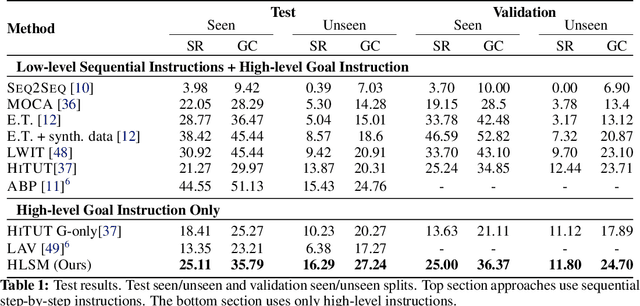
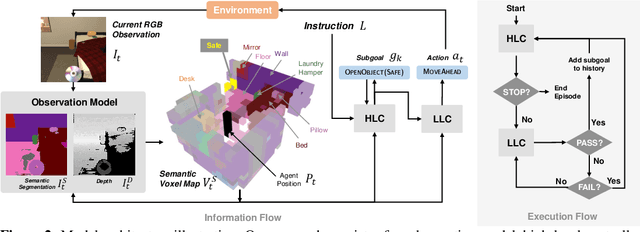
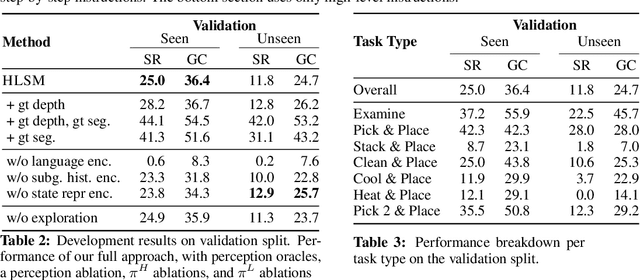
Natural language provides an accessible and expressive interface to specify long-term tasks for robotic agents. However, non-experts are likely to specify such tasks with high-level instructions, which abstract over specific robot actions through several layers of abstraction. We propose that key to bridging this gap between language and robot actions over long execution horizons are persistent representations. We propose a persistent spatial semantic representation method, and show how it enables building an agent that performs hierarchical reasoning to effectively execute long-term tasks. We evaluate our approach on the ALFRED benchmark and achieve state-of-the-art results, despite completely avoiding the commonly used step-by-step instructions.
Few-shot Object Grounding and Mapping for Natural Language Robot Instruction Following
Nov 14, 2020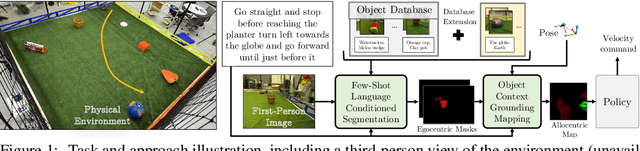
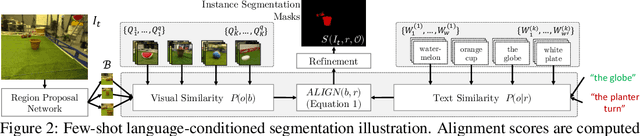
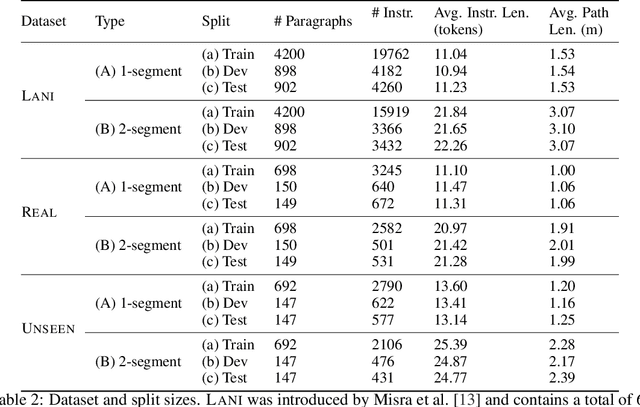
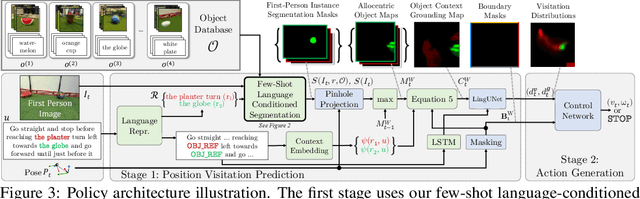
We study the problem of learning a robot policy to follow natural language instructions that can be easily extended to reason about new objects. We introduce a few-shot language-conditioned object grounding method trained from augmented reality data that uses exemplars to identify objects and align them to their mentions in instructions. We present a learned map representation that encodes object locations and their instructed use, and construct it from our few-shot grounding output. We integrate this mapping approach into an instruction-following policy, thereby allowing it to reason about previously unseen objects at test-time by simply adding exemplars. We evaluate on the task of learning to map raw observations and instructions to continuous control of a physical quadcopter. Our approach significantly outperforms the prior state of the art in the presence of new objects, even when the prior approach observes all objects during training.