 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Feb 27, 2025



Modern automatic speech recognition (ASR) models, such as OpenAI's Whisper, rely on deep encoder-decoder architectures, and their encoders are a critical bottleneck for efficient deployment due to high computational intensity. We introduce LiteASR, a low-rank compression scheme for ASR encoders that significantly reduces inference costs while maintaining transcription accuracy. Our approach leverages the strong low-rank properties observed in intermediate activations: by applying principal component analysis (PCA) with a small calibration dataset, we approximate linear transformations with a chain of low-rank matrix multiplications, and further optimize self-attention to work in the reduced dimension. Evaluation results show that our method can compress Whisper large-v3's encoder size by over 50%, matching Whisper medium's size with better transcription accuracy, thereby establishing a new Pareto-optimal frontier of efficiency and performance. The code of LiteASR is available at https://github.com/efeslab/LiteASR.
A Joint Study of Phrase Grounding and Task Performance in Vision and Language Models
Sep 06, 2023Key to tasks that require reasoning about natural language in visual contexts is grounding words and phrases to image regions. However, observing this grounding in contemporary models is complex, even if it is generally expected to take place if the task is addressed in a way that is conductive to generalization. We propose a framework to jointly study task performance and phrase grounding, and propose three benchmarks to study the relation between the two. Our results show that contemporary models demonstrate inconsistency between their ability to ground phrases and solve tasks. We show how this can be addressed through brute-force training on ground phrasing annotations, and analyze the dynamics it creates. Code and at available at https://github.com/lil-lab/phrase_grounding.
Abstract Visual Reasoning with Tangram Shapes
Nov 29, 2022



We introduce KiloGram, a resource for studying abstract visual reasoning in humans and machines. Drawing on the history of tangram puzzles as stimuli in cognitive science, we build a richly annotated dataset that, with >1k distinct stimuli, is orders of magnitude larger and more diverse than prior resources. It is both visually and linguistically richer, moving beyond whole shape descriptions to include segmentation maps and part labels. We use this resource to evaluate the abstract visual reasoning capacities of recent multi-modal models. We observe that pre-trained weights demonstrate limited abstract reasoning, which dramatically improves with fine-tuning. We also observe that explicitly describing parts aids abstract reasoning for both humans and models, especially when jointly encoding the linguistic and visual inputs. KiloGram is available at https://lil.nlp.cornell.edu/kilogram .
lilGym: Natural Language Visual Reasoning with Reinforcement Learning
Nov 03, 2022We present lilGym, a new benchmark for language-conditioned reinforcement learning in visual environments. lilGym is based on 2,661 highly-compositional human-written natural language statements grounded in an interactive visual environment. We annotate all statements with executable Python programs representing their meaning to enable exact reward computation in every possible world state. Each statement is paired with multiple start states and reward functions to form thousands of distinct Markov Decision Processes of varying difficulty. We experiment with lilGym with different models and learning regimes. Our results and analysis show that while existing methods are able to achieve non-trivial performance, lilGym forms a challenging open problem. lilGym is available at https://lil.nlp.cornell.edu/lilgym/.
Markup-to-Image Diffusion Models with Scheduled Sampling
Oct 11, 2022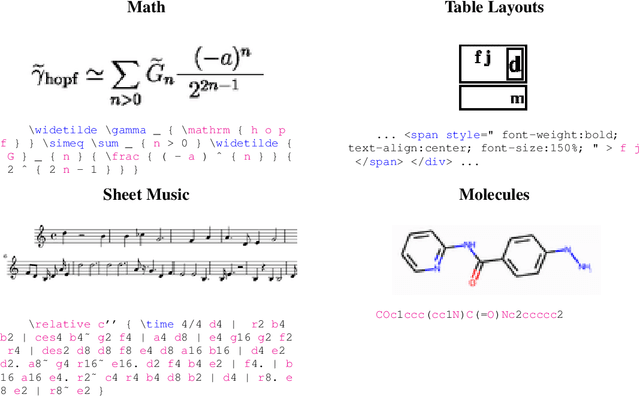

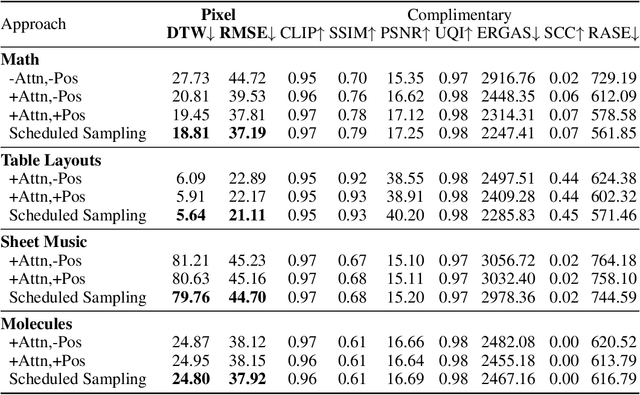
Building on recent advances in image generation, we present a fully data-driven approach to rendering markup into images. The approach is based on diffusion models, which parameterize the distribution of data using a sequence of denoising operations on top of a Gaussian noise distribution. We view the diffusion denoising process as a sequential decision making process, and show that it exhibits compounding errors similar to exposure bias issues in imitation learning problems. To mitigate these issues, we adapt the scheduled sampling algorithm to diffusion training. We conduct experiments on four markup datasets: mathematical formulas (LaTeX), table layouts (HTML), sheet music (LilyPond), and molecular images (SMILES). These experiments each verify the effectiveness of the diffusion process and the use of scheduled sampling to fix generation issues. These results also show that the markup-to-image task presents a useful controlled compositional setting for diagnosing and analyzing generative image models.
Continual Learning for Grounded Instruction Generation by Observing Human Following Behavior
Aug 10, 2021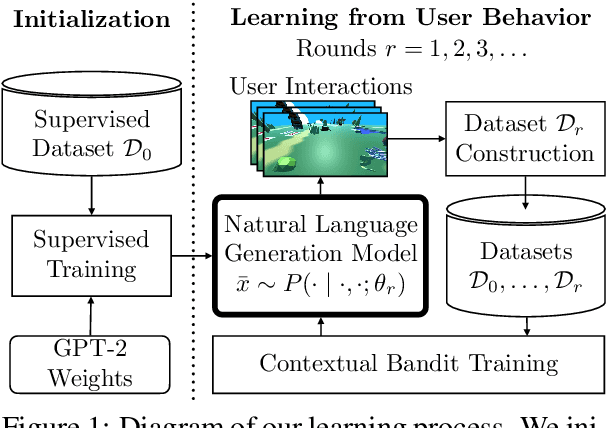

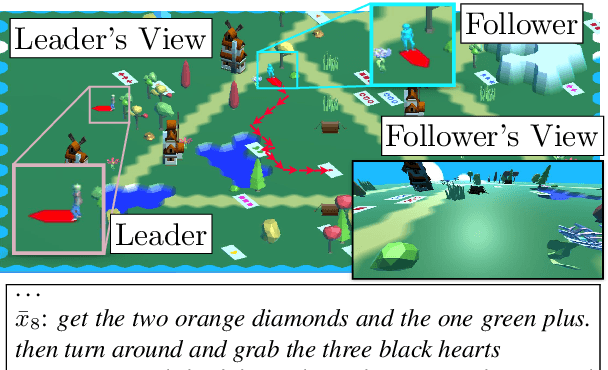
We study continual learning for natural language instruction generation, by observing human users' instruction execution. We focus on a collaborative scenario, where the system both acts and delegates tasks to human users using natural language. We compare user execution of generated instructions to the original system intent as an indication to the system's success communicating its intent. We show how to use this signal to improve the system's ability to generate instructions via contextual bandit learning. In interaction with real users, our system demonstrates dramatic improvements in its ability to generate language over time.
OASIS: A Large-Scale Dataset for Single Image 3D in the Wild
Jul 26, 2020

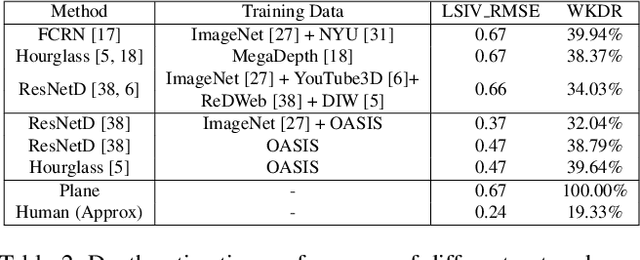

Single-view 3D is the task of recovering 3D properties such as depth and surface normals from a single image. We hypothesize that a major obstacle to single-image 3D is data. We address this issue by presenting Open Annotations of Single Image Surfaces (OASIS), a dataset for single-image 3D in the wild consisting of annotations of detailed 3D geometry for 140,000 images. We train and evaluate leading models on a variety of single-image 3D tasks. We expect OASIS to be a useful resource for 3D vision research. Project site: https://pvl.cs.princeton.edu/OASIS.
What is Learned in Visually Grounded Neural Syntax Acquisition
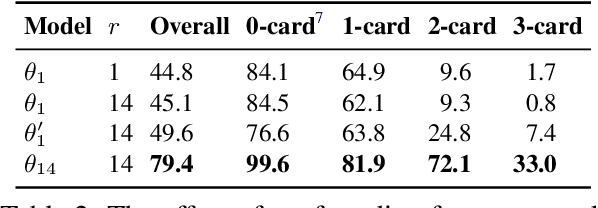
May 18, 2020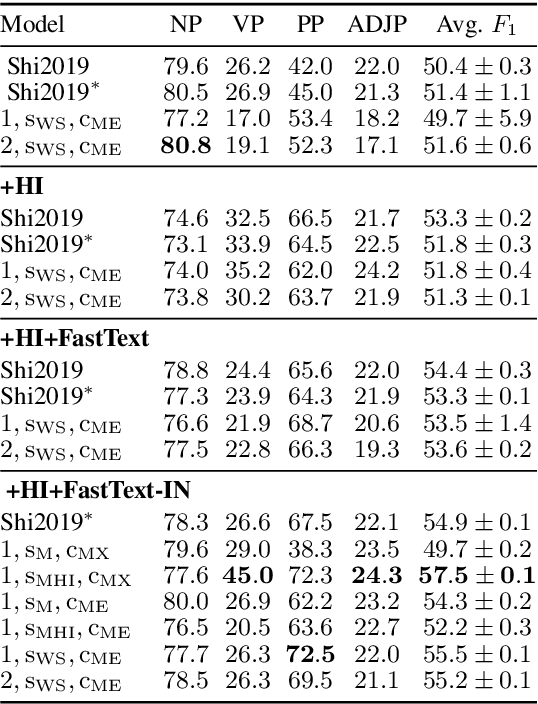
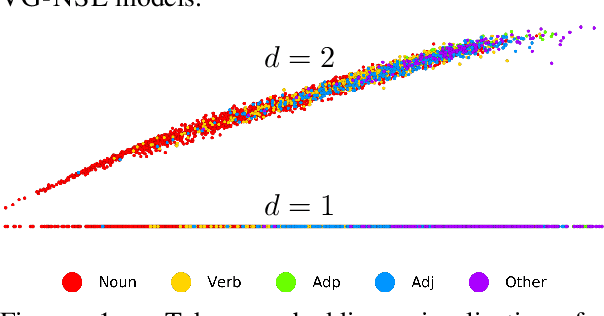
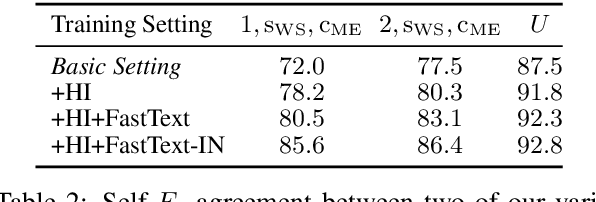
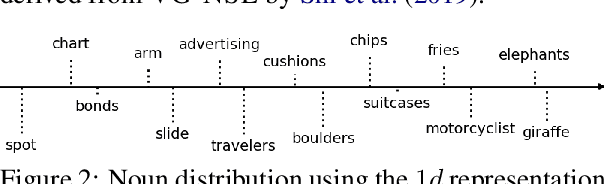
Visual features are a promising signal for learning bootstrap textual models. However, blackbox learning models make it difficult to isolate the specific contribution of visual components. In this analysis, we consider the case study of the Visually Grounded Neural Syntax Learner (Shi et al., 2019), a recent approach for learning syntax from a visual training signal. By constructing simplified versions of the model, we isolate the core factors that yield the model's strong performance. Contrary to what the model might be capable of learning, we find significantly less expressive versions produce similar predictions and perform just as well, or even better. We also find that a simple lexical signal of noun concreteness plays the main role in the model's predictions as opposed to more complex syntactic reasoning.
To Learn or Not to Learn: Analyzing the Role of Learning for Navigation in Virtual Environments
Jul 26, 2019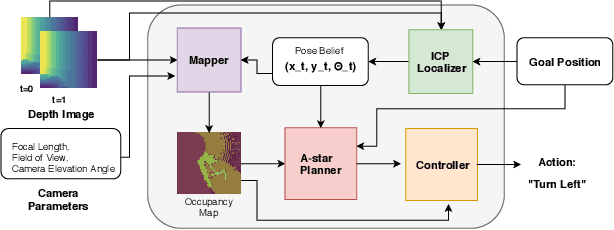
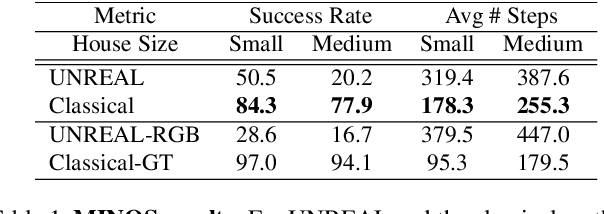
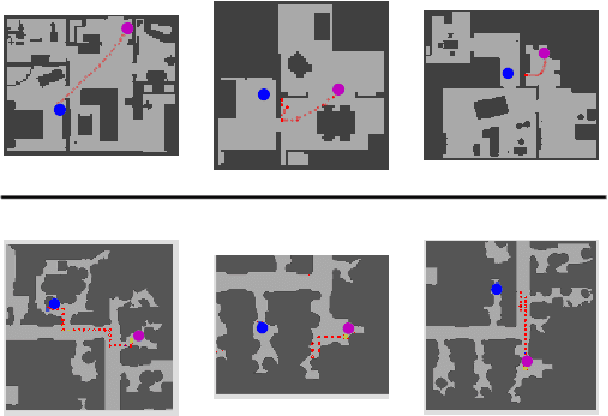

In this paper we compare learning-based methods and classical methods for navigation in virtual environments. We construct classical navigation agents and demonstrate that they outperform state-of-the-art learning-based agents on two standard benchmarks: MINOS and Stanford Large-Scale 3D Indoor Spaces. We perform detailed analysis to study the strengths and weaknesses of learned agents and classical agents, as well as how characteristics of the virtual environment impact navigation performance. Our results show that learned agents have inferior collision avoidance and memory management, but are superior in handling ambiguity and noise. These results can inform future design of navigation agents.
Speaker Naming in Movies
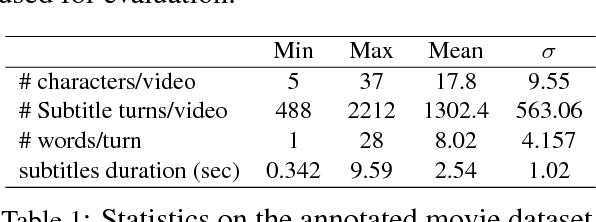
Sep 24, 2018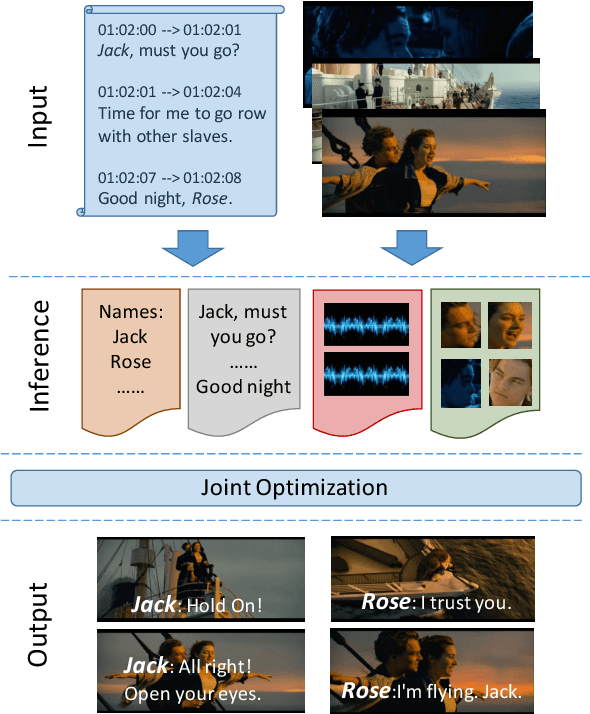
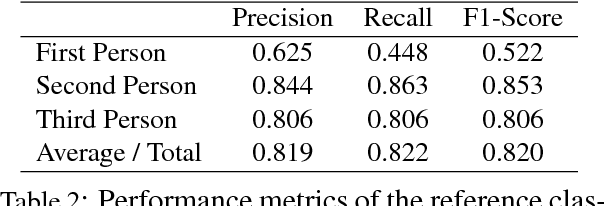
We propose a new model for speaker naming in movies that leverages visual, textual, and acoustic modalities in an unified optimization framework. To evaluate the performance of our model, we introduce a new dataset consisting of six episodes of the Big Bang Theory TV show and eighteen full movies covering different genres. Our experiments show that our multimodal model significantly outperforms several competitive baselines on the average weighted F-score metric. To demonstrate the effectiveness of our framework, we design an end-to-end memory network model that leverages our speaker naming model and achieves state-of-the-art results on the subtitles task of the MovieQA 2017 Challenge.