 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025



Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
E2ESlack: An End-to-End Graph-Based Framework for Pre-Routing Slack Prediction
Jan 14, 2025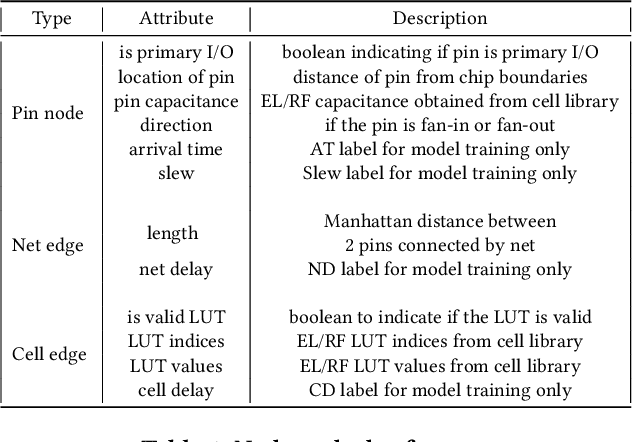
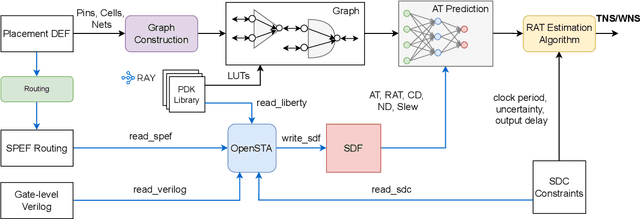

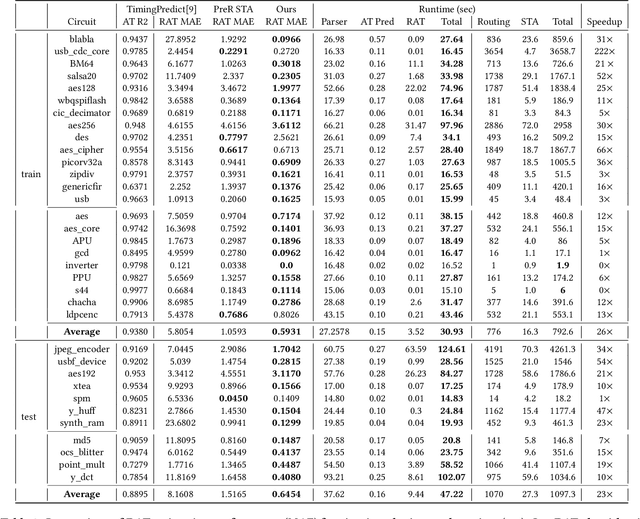
Pre-routing slack prediction remains a critical area of research in Electronic Design Automation (EDA). Despite numerous machine learning-based approaches targeting this task, there is still a lack of a truly end-to-end framework that engineers can use to obtain TNS/WNS metrics from raw circuit data at the placement stage. Existing works have demonstrated effectiveness in Arrival Time (AT) prediction but lack a mechanism for Required Arrival Time (RAT) prediction, which is essential for slack prediction and obtaining TNS/WNS metrics. In this work, we propose E2ESlack, an end-to-end graph-based framework for pre-routing slack prediction. The framework includes a TimingParser that supports DEF, SDF and LIB files for feature extraction and graph construction, an arrival time prediction model and a fast RAT estimation module. To the best of our knowledge, this is the first work capable of predicting path-level slacks at the pre-routing stage. We perform extensive experiments and demonstrate that our proposed RAT estimation method outperforms the SOTA ML-based prediction method and also pre-routing STA tool. Additionally, the proposed E2ESlack framework achieves TNS/WNS values comparable to post-routing STA results while saving up to 23x runtime.
TransPlace: Transferable Circuit Global Placement via Graph Neural Network
Jan 10, 2025



Global placement, a critical step in designing the physical layout of computer chips, is essential to optimize chip performance. Prior global placement methods optimize each circuit design individually from scratch. Their neglect of transferable knowledge limits solution efficiency and chip performance as circuit complexity drastically increases. This study presents TransPlace, a global placement framework that learns to place millions of mixed-size cells in continuous space. TransPlace introduces i) Netlist Graph to efficiently model netlist topology, ii) Cell-flow and relative position encoding to learn SE(2)-invariant representation, iii) a tailored graph neural network architecture for informed parameterization of placement knowledge, and iv) a two-stage strategy for coarse-to-fine placement. Compared to state-of-the-art placement methods, TransPlace-trained on a few high-quality placements-can place unseen circuits with 1.2x speedup while reducing congestion by 30%, timing by 9%, and wirelength by 5%.
Path-of-Thoughts: Extracting and Following Paths for Robust Relational Reasoning with Large Language Models
Dec 23, 2024



Large language models (LLMs) possess vast semantic knowledge but often struggle with complex reasoning tasks, particularly in relational reasoning problems such as kinship or spatial reasoning. In this paper, we present Path-of-Thoughts (PoT), a novel framework designed to tackle relation reasoning by decomposing the task into three key stages: graph extraction, path identification, and reasoning. Unlike previous approaches, PoT efficiently extracts a task-agnostic graph that identifies crucial entities, relations, and attributes within the problem context. Subsequently, PoT identifies relevant reasoning chains within the graph corresponding to the posed question, facilitating inference of potential answers. Experimental evaluations on four benchmark datasets, demanding long reasoning chains, demonstrate that PoT surpasses state-of-the-art baselines by a significant margin (maximum 21.3%) without necessitating fine-tuning or extensive LLM calls. Furthermore, as opposed to prior neuro-symbolic methods, PoT exhibits improved resilience against LLM errors by leveraging the compositional nature of graphs.
Hint Marginalization for Improved Reasoning in Large Language Models
Dec 17, 2024Large Language Models (LLMs) have exhibited an impressive capability to perform reasoning tasks, especially if they are encouraged to generate a sequence of intermediate steps. Reasoning performance can be improved by suitably combining multiple LLM responses, generated either in parallel in a single query, or via sequential interactions with LLMs throughout the reasoning process. Existing strategies for combination, such as self-consistency and progressive-hint-prompting, make inefficient usage of the LLM responses. We present Hint Marginalization, a novel and principled algorithmic framework to enhance the reasoning capabilities of LLMs. Our approach can be viewed as an iterative sampling strategy for forming a Monte Carlo approximation of an underlying distribution of answers, with the goal of identifying the mode the most likely answer. Empirical evaluation on several benchmark datasets for arithmetic reasoning demonstrates the superiority of the proposed approach.
Retrieval-Augmented Machine Translation with Unstructured Knowledge
Dec 05, 2024Retrieval-augmented generation (RAG) introduces additional information to enhance large language models (LLMs). In machine translation (MT), previous work typically retrieves in-context examples from paired MT corpora, or domain-specific knowledge from knowledge graphs, to enhance models' MT ability. However, a large amount of world knowledge is organized in unstructured documents, and might not be fully paired across different languages. In this paper, we study retrieval-augmented MT using unstructured documents. Specifically, we build RAGtrans, the first benchmark to train and evaluate LLMs' retrieval-augmented MT ability. RAGtrans contains 79K MT samples collected via GPT-4o and human translators. Besides, documents from different languages are also provided to supply the knowledge to these samples. Based on RAGtrans, we further propose a multi-task training method to teach LLMs how to use information from multilingual documents during their translation. The method uses existing multilingual corpora to create auxiliary training objectives without additional labeling requirements. Extensive experiments show that the method improves LLMs by 1.58-3.09 BLEU and 1.00-2.03 COMET scores.
The Graph's Apprentice: Teaching an LLM Low Level Knowledge for Circuit Quality Estimation
Oct 30, 2024Logic synthesis is a crucial phase in the circuit design process, responsible for transforming hardware description language (HDL) designs into optimized netlists. However, traditional logic synthesis methods are computationally intensive, restricting their iterative use in refining chip designs. Recent advancements in large language models (LLMs), particularly those fine-tuned on programming languages, present a promising alternative. In this paper, we introduce VeriDistill, the first end-to-end machine learning model that directly processes raw Verilog code to predict circuit quality-of-result metrics. Our model employs a novel knowledge distillation method, transferring low-level circuit insights via graphs into the predictor based on LLM. Experiments show VeriDistill outperforms state-of-the-art baselines on large-scale Verilog datasets and demonstrates robust performance when evaluated on out-of-distribution datasets.
Enhancing CTR Prediction in Recommendation Domain with Search Query Representation
Oct 28, 2024



Many platforms, such as e-commerce websites, offer both search and recommendation services simultaneously to better meet users' diverse needs. Recommendation services suggest items based on user preferences, while search services allow users to search for items before providing recommendations. Since users and items are often shared between the search and recommendation domains, there is a valuable opportunity to enhance the recommendation domain by leveraging user preferences extracted from the search domain. Existing approaches either overlook the shift in user intention between these domains or fail to capture the significant impact of learning from users' search queries on understanding their interests. In this paper, we propose a framework that learns from user search query embeddings within the context of user preferences in the recommendation domain. Specifically, user search query sequences from the search domain are used to predict the items users will click at the next time point in the recommendation domain. Additionally, the relationship between queries and items is explored through contrastive learning. To address issues of data sparsity, the diffusion model is incorporated to infer positive items the user will select after searching with certain queries in a denoising manner, which is particularly effective in preventing false positives. Effectively extracting this information, the queries are integrated into click-through rate prediction in the recommendation domain. Experimental analysis demonstrates that our model outperforms state-of-the-art models in the recommendation domain.
* Accepted by CIKM 2024 Full Research Track
CRAT: A Multi-Agent Framework for Causality-Enhanced Reflective and Retrieval-Augmented Translation with Large Language Models
Oct 28, 2024



Large language models (LLMs) have shown great promise in machine translation, but they still struggle with contextually dependent terms, such as new or domain-specific words. This leads to inconsistencies and errors that are difficult to address. Existing solutions often depend on manual identification of such terms, which is impractical given the complexity and evolving nature of language. While Retrieval-Augmented Generation (RAG) could provide some assistance, its application to translation is limited by issues such as hallucinations from information overload. In this paper, we propose CRAT, a novel multi-agent translation framework that leverages RAG and causality-enhanced self-reflection to address these challenges. This framework consists of several specialized agents: the Unknown Terms Identification agent detects unknown terms within the context, the Knowledge Graph (KG) Constructor agent extracts relevant internal knowledge about these terms and retrieves bilingual information from external sources, the Causality-enhanced Judge agent validates the accuracy of the information, and the Translator agent incorporates the refined information into the final output. This automated process allows for more precise and consistent handling of key terms during translation. Our results show that CRAT significantly improves translation accuracy, particularly in handling context-sensitive terms and emerging vocabulary.
Sparse Decomposition of Graph Neural Networks
Oct 25, 2024



Graph Neural Networks (GNN) exhibit superior performance in graph representation learning, but their inference cost can be high, due to an aggregation operation that can require a memory fetch for a very large number of nodes. This inference cost is the major obstacle to deploying GNN models with \emph{online prediction} to reflect the potentially dynamic node features. To address this, we propose an approach to reduce the number of nodes that are included during aggregation. We achieve this through a sparse decomposition, learning to approximate node representations using a weighted sum of linearly transformed features of a carefully selected subset of nodes within the extended neighbourhood. The approach achieves linear complexity with respect to the average node degree and the number of layers in the graph neural network. We introduce an algorithm to compute the optimal parameters for the sparse decomposition, ensuring an accurate approximation of the original GNN model, and present effective strategies to reduce the training time and improve the learning process. We demonstrate via extensive experiments that our method outperforms other baselines designed for inference speedup, achieving significant accuracy gains with comparable inference times for both node classification and spatio-temporal forecasting tasks.