 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Auto-Research: Roadmap & User Guide
May 18, 2026AI-assisted research is crossing a threshold: fully automated systems can now generate research papers for as little as $15, while long-horizon agents can execute experiments, draft manuscripts, and simulate critique with minimal human input. Yet this productivity frontier exposes a deeper integrity problem: under scientific pressure, even frontier LLMs still fabricate results, miss hidden errors, and fail to judge novelty reliably. Studying developments through April 2026, we present an end-to-end analysis of AI across the complete research lifecycle, organized into four epistemological phases: Creation (idea generation, literature review, coding & experiments, tables & figures), Writing (paper writing), Validation (peer review, rebuttal & revision), and Dissemination (posters, slides, videos, social media, project pages, and interactive agents). We identify a sharp, stage-dependent boundary between reliable assistance and unreliable autonomy: AI excels at structured, retrieval-grounded, and tool-mediated tasks, but remains fragile for genuinely novel ideas, research-level experiments, and scientific judgment. Generated ideas often degrade after implementation, research code lags far behind pattern-matching benchmarks, and end-to-end autonomous systems have not yet consistently reached major-venue acceptance standards. We further show that greater automation can obscure rather than eliminate failure modes, making human-governed collaboration the most credible deployment paradigm. Finally, we provide a structured taxonomy, benchmark suite, and tool inventory, cross-stage design principles, and a practitioner-oriented playbook, with resources maintained at our project page.
Large Language Model Agents Are Not Always Faithful Self-Evolvers
Jan 30, 2026Self-evolving large language model (LLM) agents continually improve by accumulating and reusing past experience, yet it remains unclear whether they faithfully rely on that experience to guide their behavior. We present the first systematic investigation of experience faithfulness, the causal dependence of an agent's decisions on the experience it is given, in self-evolving LLM agents. Using controlled causal interventions on both raw and condensed forms of experience, we comprehensively evaluate four representative frameworks across 10 LLM backbones and 9 environments. Our analysis uncovers a striking asymmetry: while agents consistently depend on raw experience, they often disregard or misinterpret condensed experience, even when it is the only experience provided. This gap persists across single- and multi-agent configurations and across backbone scales. We trace its underlying causes to three factors: the semantic limitations of condensed content, internal processing biases that suppress experience, and task regimes where pretrained priors already suffice. These findings challenge prevailing assumptions about self-evolving methods and underscore the need for more faithful and reliable approaches to experience integration.
Identification of Pediatric Respiratory Diseases Using Fine-grained Diagnosis System
Aug 24, 2021
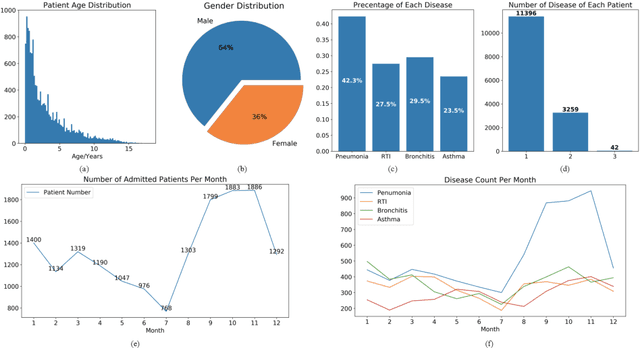
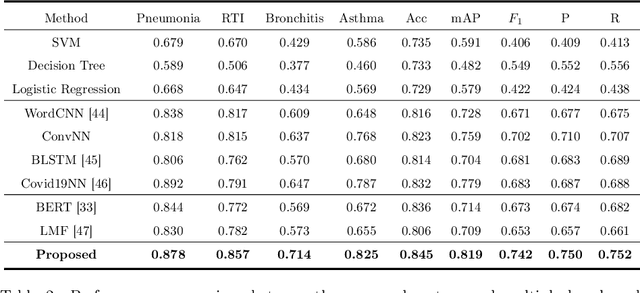
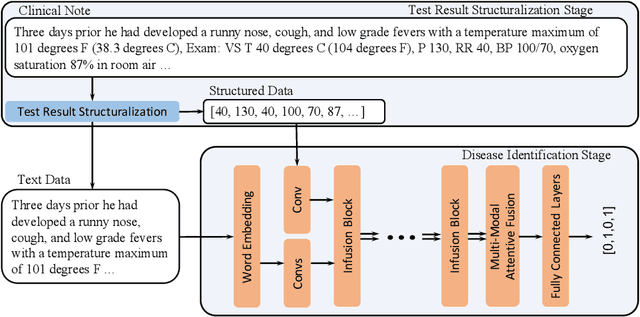
Respiratory diseases, including asthma, bronchitis, pneumonia, and upper respiratory tract infection (RTI), are among the most common diseases in clinics. The similarities among the symptoms of these diseases precludes prompt diagnosis upon the patients' arrival. In pediatrics, the patients' limited ability in expressing their situation makes precise diagnosis even harder. This becomes worse in primary hospitals, where the lack of medical imaging devices and the doctors' limited experience further increase the difficulty of distinguishing among similar diseases. In this paper, a pediatric fine-grained diagnosis-assistant system is proposed to provide prompt and precise diagnosis using solely clinical notes upon admission, which would assist clinicians without changing the diagnostic process. The proposed system consists of two stages: a test result structuralization stage and a disease identification stage. The first stage structuralizes test results by extracting relevant numerical values from clinical notes, and the disease identification stage provides a diagnosis based on text-form clinical notes and the structured data obtained from the first stage. A novel deep learning algorithm was developed for the disease identification stage, where techniques including adaptive feature infusion and multi-modal attentive fusion were introduced to fuse structured and text data together. Clinical notes from over 12000 patients with respiratory diseases were used to train a deep learning model, and clinical notes from a non-overlapping set of about 1800 patients were used to evaluate the performance of the trained model. The average precisions (AP) for pneumonia, RTI, bronchitis and asthma are 0.878, 0.857, 0.714, and 0.825, respectively, achieving a mean AP (mAP) of 0.819.