 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-branch Attentive Transformer
Jun 18, 2020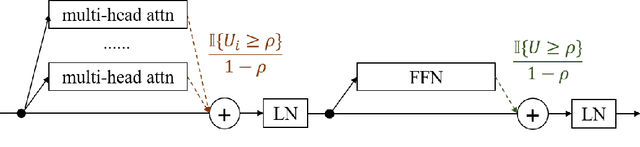
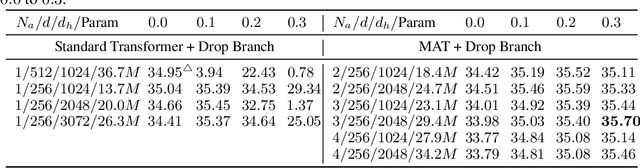
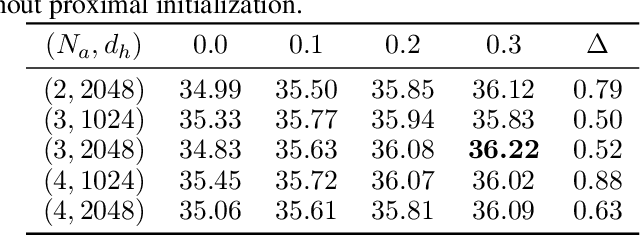
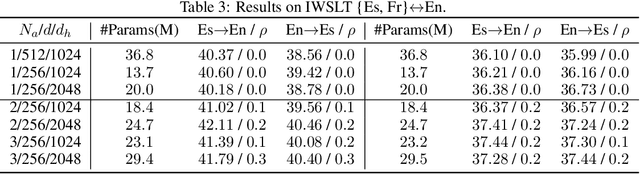
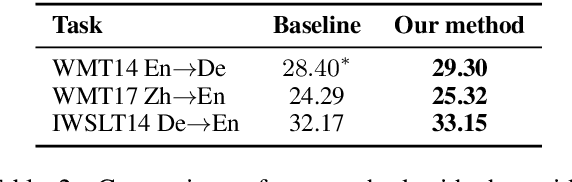
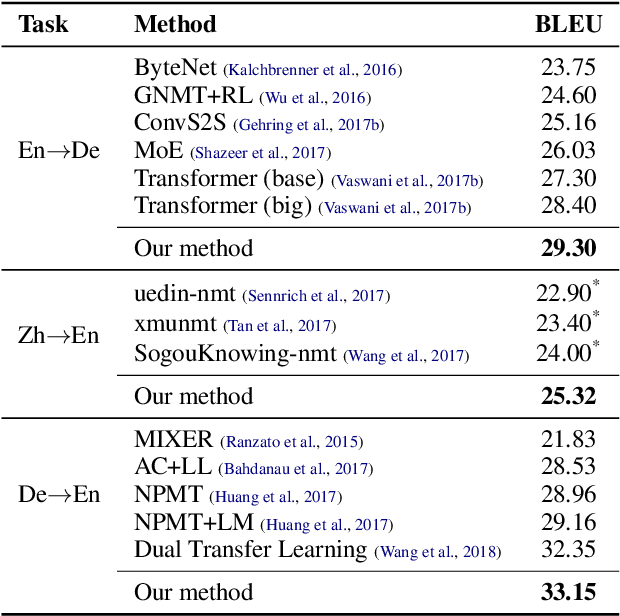
While the multi-branch architecture is one of the key ingredients to the success of computer vision tasks, it has not been well investigated in natural language processing, especially sequence learning tasks. In this work, we propose a simple yet effective variant of Transformer called multi-branch attentive Transformer (briefly, MAT), where the attention layer is the average of multiple branches and each branch is an independent multi-head attention layer. We leverage two training techniques to regularize the training: drop-branch, which randomly drops individual branches during training, and proximal initialization, which uses a pre-trained Transformer model to initialize multiple branches. Experiments on machine translation, code generation and natural language understanding demonstrate that such a simple variant of Transformer brings significant improvements. Our code is available at \url{https://github.com/HA-Transformer}.
Dual Learning: Theoretical Study and an Algorithmic Extension
May 17, 2020
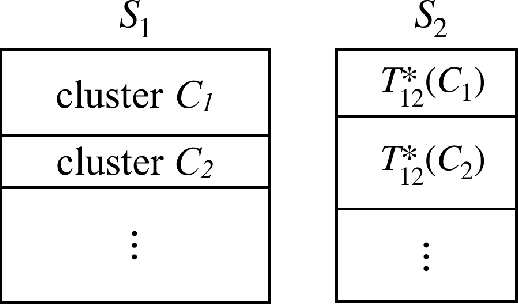
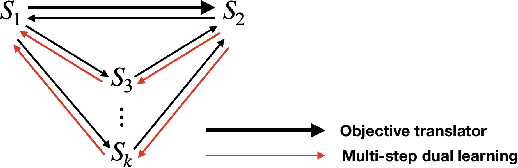
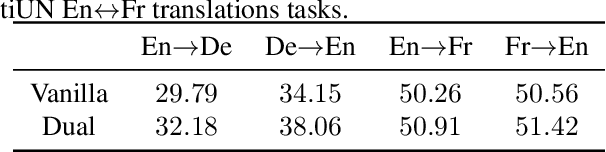
Dual learning has been successfully applied in many machine learning applications including machine translation, image-to-image transformation, etc. The high-level idea of dual learning is very intuitive: if we map an $x$ from one domain to another and then map it back, we should recover the original $x$. Although its effectiveness has been empirically verified, theoretical understanding of dual learning is still very limited. In this paper, we aim at understanding why and when dual learning works. Based on our theoretical analysis, we further extend dual learning by introducing more related mappings and propose multi-step dual learning, in which we leverage feedback signals from additional domains to improve the qualities of the mappings. We prove that multi-step dual learn-ing can boost the performance of standard dual learning under mild conditions. Experiments on WMT 14 English$\leftrightarrow$German and MultiUNEnglish$\leftrightarrow$French translations verify our theoretical findings on dual learning, and the results on the translations among English, French, and Spanish of MultiUN demonstrate the effectiveness of multi-step dual learning.
TuiGAN: Learning Versatile Image-to-Image Translation with Two Unpaired Images
Apr 09, 2020

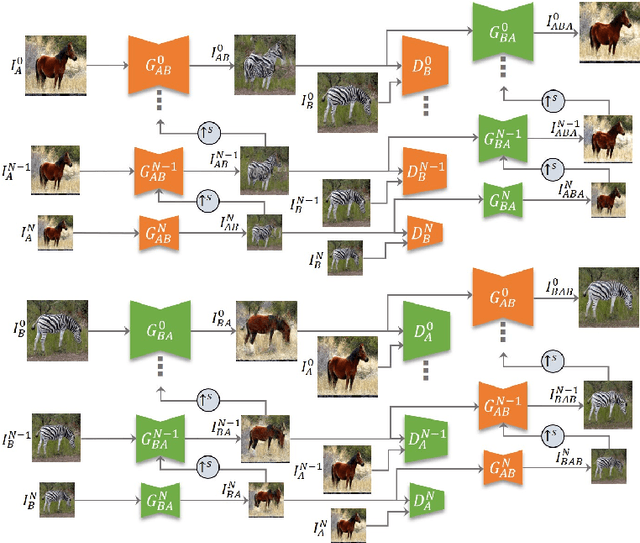
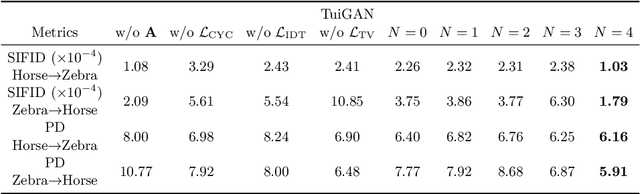
An unsupervised image-to-image translation (UI2I) task deals with learning a mapping between two domains without paired images. While existing UI2I methods usually require numerous unpaired images from different domains for training, there are many scenarios where training data is quite limited. In this paper, we argue that even if each domain contains a single image, UI2I can still be achieved. To this end, we propose TuiGAN, a generative model that is trained on only two unpaired images and amounts to one-shot unsupervised learning. With TuiGAN, an image is translated in a coarse-to-fine manner where the generated image is gradually refined from global structures to local details. We conduct extensive experiments to verify that our versatile method can outperform strong baselines on a wide variety of UI2I tasks. Moreover, TuiGAN is capable of achieving comparable performance with the state-of-the-art UI2I models trained with sufficient data.
Incorporating BERT into Neural Machine Translation
Feb 17, 2020
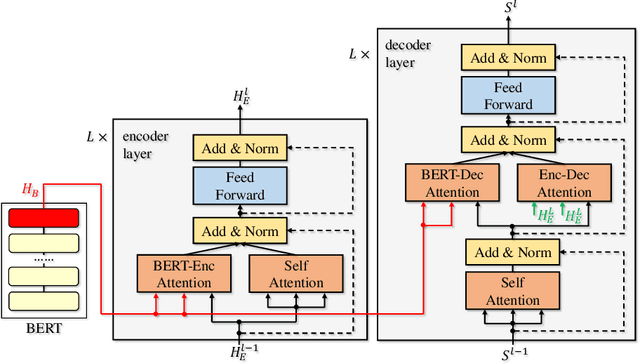
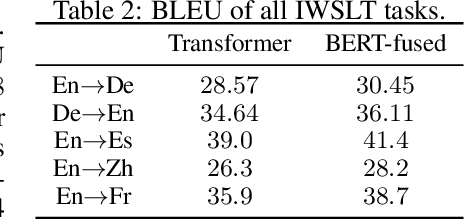
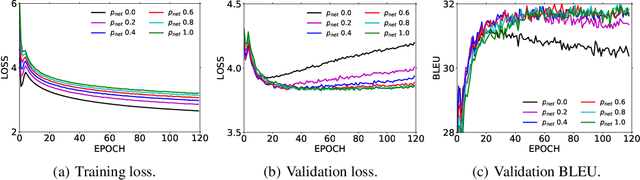
The recently proposed BERT has shown great power on a variety of natural language understanding tasks, such as text classification, reading comprehension, etc. However, how to effectively apply BERT to neural machine translation (NMT) lacks enough exploration. While BERT is more commonly used as fine-tuning instead of contextual embedding for downstream language understanding tasks, in NMT, our preliminary exploration of using BERT as contextual embedding is better than using for fine-tuning. This motivates us to think how to better leverage BERT for NMT along this direction. We propose a new algorithm named BERT-fused model, in which we first use BERT to extract representations for an input sequence, and then the representations are fused with each layer of the encoder and decoder of the NMT model through attention mechanisms. We conduct experiments on supervised (including sentence-level and document-level translations), semi-supervised and unsupervised machine translation, and achieve state-of-the-art results on seven benchmark datasets. Our code is available at \url{https://github.com/bert-nmt/bert-nmt}.
Microsoft Research Asia's Systems for WMT19
Nov 07, 2019

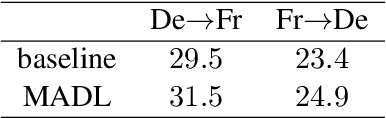
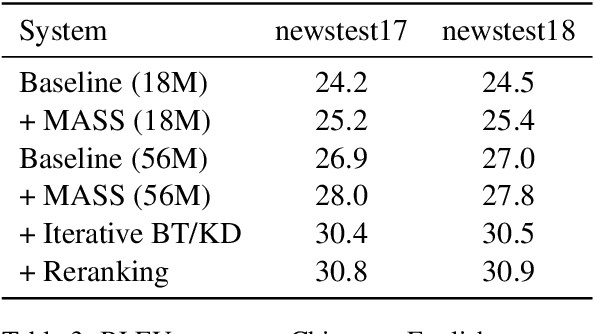
We Microsoft Research Asia made submissions to 11 language directions in the WMT19 news translation tasks. We won the first place for 8 of the 11 directions and the second place for the other three. Our basic systems are built on Transformer, back translation and knowledge distillation. We integrate several of our rececent techniques to enhance the baseline systems: multi-agent dual learning (MADL), masked sequence-to-sequence pre-training (MASS), neural architecture optimization (NAO), and soft contextual data augmentation (SCA).
Efficient Bidirectional Neural Machine Translation
Aug 25, 2019
The encoder-decoder based neural machine translation usually generates a target sequence token by token from left to right. Due to error propagation, the tokens in the right side of the generated sequence are usually of poorer quality than those in the left side. In this paper, we propose an efficient method to generate a sequence in both left-to-right and right-to-left manners using a single encoder and decoder, combining the advantages of both generation directions. Experiments on three translation tasks show that our method achieves significant improvements over conventional unidirectional approach. Compared with ensemble methods that train and combine two models with different generation directions, our method saves 50% model parameters and about 40% training time, and also improve inference speed.
Multilingual Neural Machine Translation with Language Clustering
Aug 25, 2019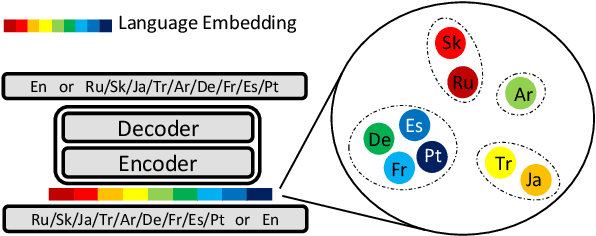
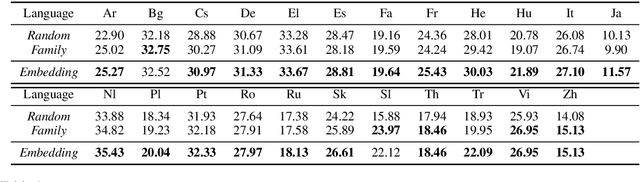
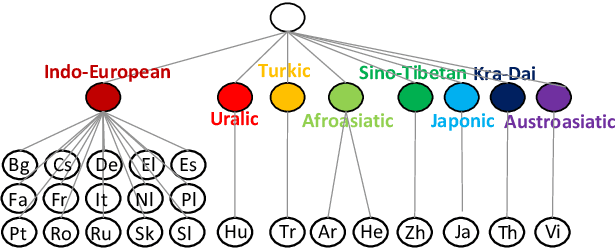
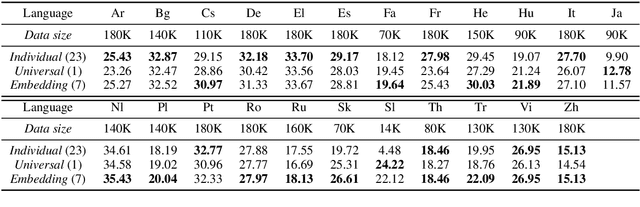
Multilingual neural machine translation (NMT), which translates multiple languages using a single model, is of great practical importance due to its advantages in simplifying the training process, reducing online maintenance costs, and enhancing low-resource and zero-shot translation. Given there are thousands of languages in the world and some of them are very different, it is extremely burdensome to handle them all in a single model or use a separate model for each language pair. Therefore, given a fixed resource budget, e.g., the number of models, how to determine which languages should be supported by one model is critical to multilingual NMT, which, unfortunately, has been ignored by previous work. In this work, we develop a framework that clusters languages into different groups and trains one multilingual model for each cluster. We study two methods for language clustering: (1) using prior knowledge, where we cluster languages according to language family, and (2) using language embedding, in which we represent each language by an embedding vector and cluster them in the embedding space. In particular, we obtain the embedding vectors of all the languages by training a universal neural machine translation model. Our experiments on 23 languages show that the first clustering method is simple and easy to understand but leading to suboptimal translation accuracy, while the second method sufficiently captures the relationship among languages well and improves the translation accuracy for almost all the languages over baseline methods
Depth Growing for Neural Machine Translation
Jul 03, 2019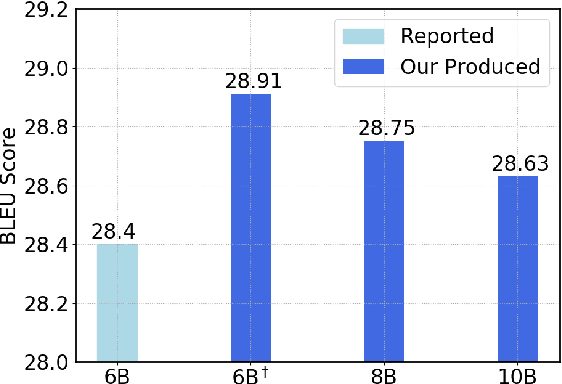
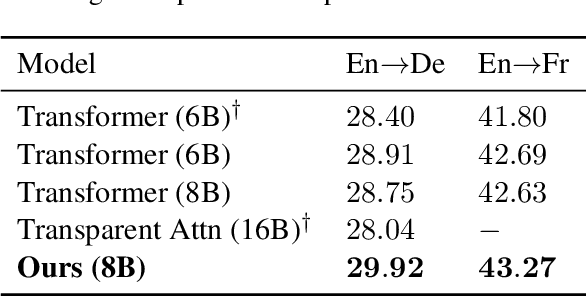
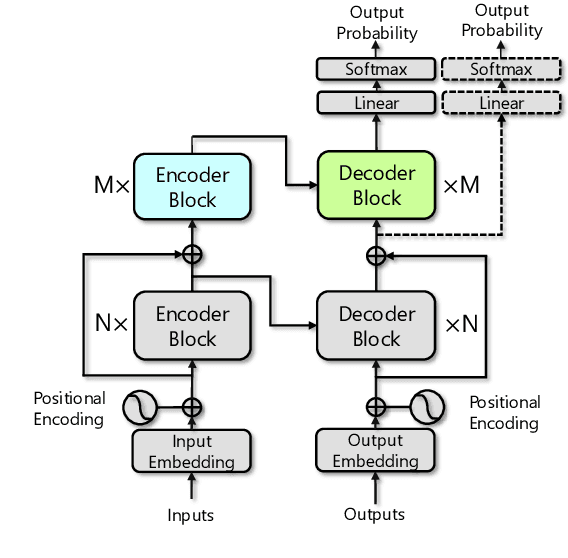
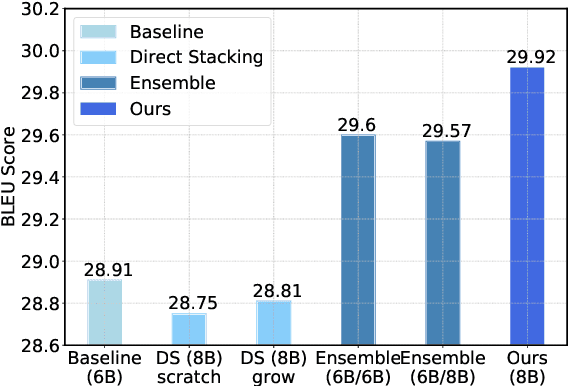
While very deep neural networks have shown effectiveness for computer vision and text classification applications, how to increase the network depth of neural machine translation (NMT) models for better translation quality remains a challenging problem. Directly stacking more blocks to the NMT model results in no improvement and even reduces performance. In this work, we propose an effective two-stage approach with three specially designed components to construct deeper NMT models, which result in significant improvements over the strong Transformer baselines on WMT$14$ English$\to$German and English$\to$French translation tasks\footnote{Our code is available at \url{https://github.com/apeterswu/Depth_Growing_NMT}}.
ZstGAN: An Adversarial Approach for Unsupervised Zero-Shot Image-to-Image Translation
Jun 01, 2019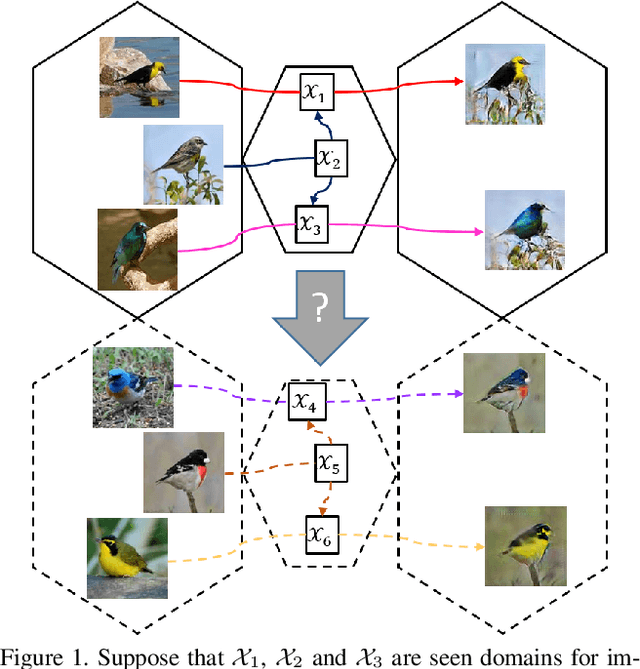
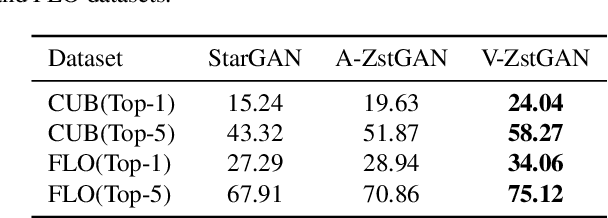
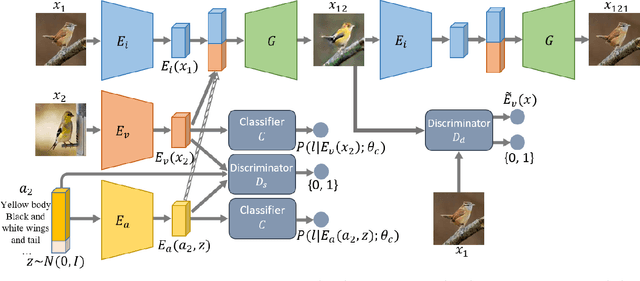
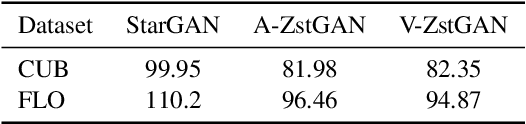
Image-to-image translation models have shown remarkable ability on transferring images among different domains. Most of existing work follows the setting that the source domain and target domain keep the same at training and inference phases, which cannot be generalized to the scenarios for translating an image from an unseen domain to an another unseen domain. In this work, we propose the Unsupervised Zero-Shot Image-to-image Translation (UZSIT) problem, which aims to learn a model that can transfer translation knowledge from seen domains to unseen domains. Accordingly, we propose a framework called ZstGAN: By introducing an adversarial training scheme, ZstGAN learns to model each domain with domain-specific feature distribution that is semantically consistent on vision and attribute modalities. Then the domain-invariant features are disentangled with an shared encoder for image generation. We carry out extensive experiments on CUB and FLO datasets, and the results demonstrate the effectiveness of proposed method on UZSIT task. Moreover, ZstGAN shows significant accuracy improvements over state-of-the-art zero-shot learning methods on CUB and FLO.
Learning to Transfer: Unsupervised Meta Domain Translation
Jun 01, 2019
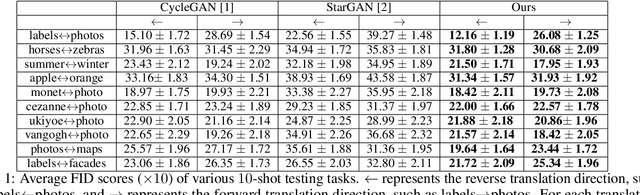
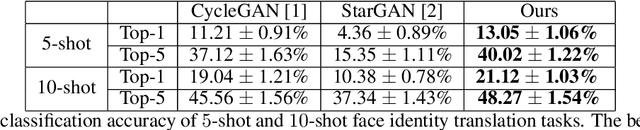
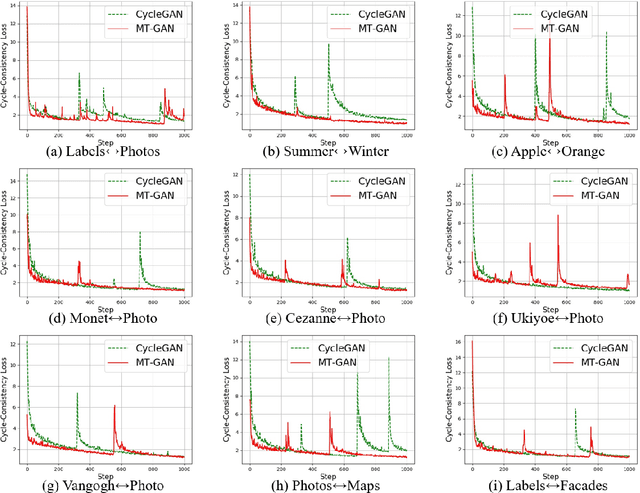
Unsupervised domain translation has recently achieved impressive performance with rapidly developed generative adversarial network (GAN) and availability of sufficient training data. However, existing domain translation frameworks form in a disposable way where the learning experiences are ignored. In this work, we take this research direction toward unsupervised meta domain translation problem. We propose a meta translation model called MT-GAN to find parameter initialization of a conditional GAN, which can quickly adapt for a new domain translation task with limited training samples. In the meta-training procedure, MT-GAN is explicitly fine-tuned with a primary translation task and a synthesized dual translation task. Then we design a meta-optimization objective to require the fine-tuned MT-GAN to produce good generalization performance. We demonstrate effectiveness of our model on ten diverse two-domain translation tasks and multiple face identity translation tasks. We show that our proposed approach significantly outperforms the existing domain translation methods when using no more than $10$ training samples in each image domain.