 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025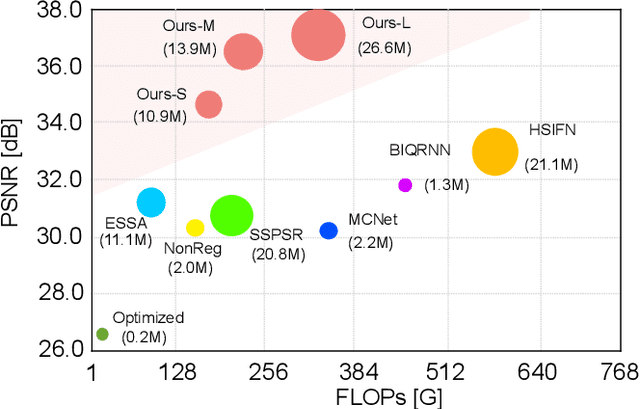
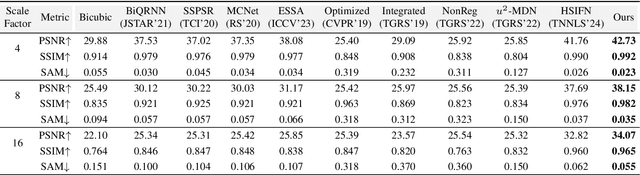
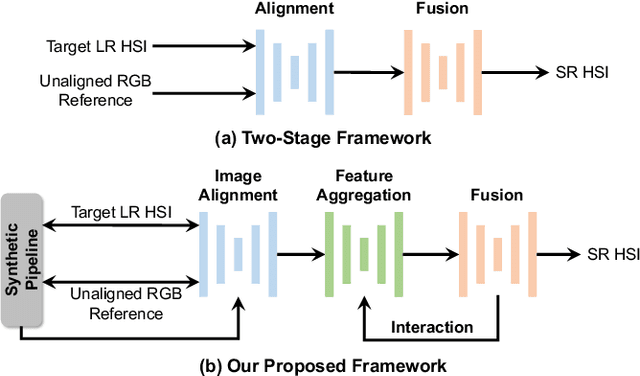
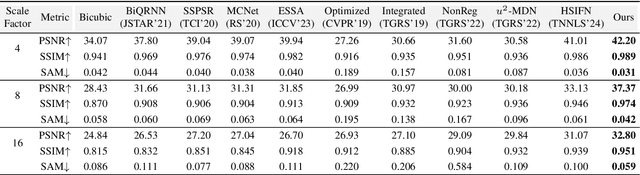
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Real-Time Animatable 2DGS-Avatars with Detail Enhancement from Monocular Videos
May 01, 2025High-quality, animatable 3D human avatar reconstruction from monocular videos offers significant potential for reducing reliance on complex hardware, making it highly practical for applications in game development, augmented reality, and social media. However, existing methods still face substantial challenges in capturing fine geometric details and maintaining animation stability, particularly under dynamic or complex poses. To address these issues, we propose a novel real-time framework for animatable human avatar reconstruction based on 2D Gaussian Splatting (2DGS). By leveraging 2DGS and global SMPL pose parameters, our framework not only aligns positional and rotational discrepancies but also enables robust and natural pose-driven animation of the reconstructed avatars. Furthermore, we introduce a Rotation Compensation Network (RCN) that learns rotation residuals by integrating local geometric features with global pose parameters. This network significantly improves the handling of non-rigid deformations and ensures smooth, artifact-free pose transitions during animation. Experimental results demonstrate that our method successfully reconstructs realistic and highly animatable human avatars from monocular videos, effectively preserving fine-grained details while ensuring stable and natural pose variation. Our approach surpasses current state-of-the-art methods in both reconstruction quality and animation robustness on public benchmarks.
Noise Calibration and Spatial-Frequency Interactive Network for STEM Image Enhancement
Apr 03, 2025



Scanning Transmission Electron Microscopy (STEM) enables the observation of atomic arrangements at sub-angstrom resolution, allowing for atomically resolved analysis of the physical and chemical properties of materials. However, due to the effects of noise, electron beam damage, sample thickness, etc, obtaining satisfactory atomic-level images is often challenging. Enhancing STEM images can reveal clearer structural details of materials. Nonetheless, existing STEM image enhancement methods usually overlook unique features in the frequency domain, and existing datasets lack realism and generality. To resolve these issues, in this paper, we develop noise calibration, data synthesis, and enhancement methods for STEM images. We first present a STEM noise calibration method, which is used to synthesize more realistic STEM images. The parameters of background noise, scan noise, and pointwise noise are obtained by statistical analysis and fitting of real STEM images containing atoms. Then we use these parameters to develop a more general dataset that considers both regular and random atomic arrangements and includes both HAADF and BF mode images. Finally, we design a spatial-frequency interactive network for STEM image enhancement, which can explore the information in the frequency domain formed by the periodicity of atomic arrangement. Experimental results show that our data is closer to real STEM images and achieves better enhancement performances together with our network. Code will be available at https://github.com/HeasonLee/SFIN}{https://github.com/HeasonLee/SFIN.
Frequency Dynamic Convolution for Dense Image Prediction
Mar 25, 2025While Dynamic Convolution (DY-Conv) has shown promising performance by enabling adaptive weight selection through multiple parallel weights combined with an attention mechanism, the frequency response of these weights tends to exhibit high similarity, resulting in high parameter costs but limited adaptability. In this work, we introduce Frequency Dynamic Convolution (FDConv), a novel approach that mitigates these limitations by learning a fixed parameter budget in the Fourier domain. FDConv divides this budget into frequency-based groups with disjoint Fourier indices, enabling the construction of frequency-diverse weights without increasing the parameter cost. To further enhance adaptability, we propose Kernel Spatial Modulation (KSM) and Frequency Band Modulation (FBM). KSM dynamically adjusts the frequency response of each filter at the spatial level, while FBM decomposes weights into distinct frequency bands in the frequency domain and modulates them dynamically based on local content. Extensive experiments on object detection, segmentation, and classification validate the effectiveness of FDConv. We demonstrate that when applied to ResNet-50, FDConv achieves superior performance with a modest increase of +3.6M parameters, outperforming previous methods that require substantial increases in parameter budgets (e.g., CondConv +90M, KW +76.5M). Moreover, FDConv seamlessly integrates into a variety of architectures, including ConvNeXt, Swin-Transformer, offering a flexible and efficient solution for modern vision tasks. The code is made publicly available at https://github.com/Linwei-Chen/FDConv.
FCaS: Fine-grained Cardiac Image Synthesis based on 3D Template Conditional Diffusion Model
Mar 12, 2025Solving medical imaging data scarcity through semantic image generation has attracted significant attention in recent years. However, existing methods primarily focus on generating whole-organ or large-tissue structures, showing limited effectiveness for organs with fine-grained structure. Due to stringent topological consistency, fragile coronary features, and complex 3D morphological heterogeneity in cardiac imaging, accurately reconstructing fine-grained anatomical details of the heart remains a great challenge. To address this problem, in this paper, we propose the Fine-grained Cardiac image Synthesis(FCaS) framework, established on 3D template conditional diffusion model. FCaS achieves precise cardiac structure generation using Template-guided Conditional Diffusion Model (TCDM) through bidirectional mechanisms, which provides the fine-grained topological structure information of target image through the guidance of template. Meanwhile, we design a deformable Mask Generation Module (MGM) to mitigate the scarcity of high-quality and diverse reference mask in the generation process. Furthermore, to alleviate the confusion caused by imprecise synthetic images, we propose a Confidence-aware Adaptive Learning (CAL) strategy to facilitate the pre-training of downstream segmentation tasks. Specifically, we introduce the Skip-Sampling Variance (SSV) estimation to obtain confidence maps, which are subsequently employed to rectify the pre-training on downstream tasks. Experimental results demonstrate that images generated from FCaS achieves state-of-the-art performance in topological consistency and visual quality, which significantly facilitates the downstream tasks as well. Code will be released in the future.
Relation-Guided Adversarial Learning for Data-free Knowledge Transfer
Dec 16, 2024Data-free knowledge distillation transfers knowledge by recovering training data from a pre-trained model. Despite the recent success of seeking global data diversity, the diversity within each class and the similarity among different classes are largely overlooked, resulting in data homogeneity and limited performance. In this paper, we introduce a novel Relation-Guided Adversarial Learning method with triplet losses, which solves the homogeneity problem from two aspects. To be specific, our method aims to promote both intra-class diversity and inter-class confusion of the generated samples. To this end, we design two phases, an image synthesis phase and a student training phase. In the image synthesis phase, we construct an optimization process to push away samples with the same labels and pull close samples with different labels, leading to intra-class diversity and inter-class confusion, respectively. Then, in the student training phase, we perform an opposite optimization, which adversarially attempts to reduce the distance of samples of the same classes and enlarge the distance of samples of different classes. To mitigate the conflict of seeking high global diversity and keeping inter-class confusing, we propose a focal weighted sampling strategy by selecting the negative in the triplets unevenly within a finite range of distance. RGAL shows significant improvement over previous state-of-the-art methods in accuracy and data efficiency. Besides, RGAL can be inserted into state-of-the-art methods on various data-free knowledge transfer applications. Experiments on various benchmarks demonstrate the effectiveness and generalizability of our proposed method on various tasks, specially data-free knowledge distillation, data-free quantization, and non-exemplar incremental learning. Our code is available at https://github.com/Sharpiless/RGAL.
Deep Learning Models for Colloidal Nanocrystal Synthesis
Dec 14, 2024



Colloidal synthesis of nanocrystals usually includes complex chemical reactions and multi-step crystallization processes. Despite the great success in the past 30 years, it remains challenging to clarify the correlations between synthetic parameters of chemical reaction and physical properties of nanocrystals. Here, we developed a deep learning-based nanocrystal synthesis model that correlates synthetic parameters with the final size and shape of target nanocrystals, using a dataset of 3500 recipes covering 348 distinct nanocrystal compositions. The size and shape labels were obtained from transmission electron microscope images using a segmentation model trained with a semi-supervised algorithm on a dataset comprising 1.2 million nanocrystals. By applying the reaction intermediate-based data augmentation method and elaborated descriptors, the synthesis model was able to predict nanocrystal's size with a mean absolute error of 1.39 nm, while reaching an 89% average accuracy for shape classification. The synthesis model shows knowledge transfer capabilities across different nanocrystals with inputs of new recipes. With that, the influence of chemicals on the final size of nanocrystals was further evaluated, revealing the importance order of nanocrystal composition, precursor or ligand, and solvent. Overall, the deep learning-based nanocrystal synthesis model offers a powerful tool to expedite the development of high-quality nanocrystals.
Multi-Granularity Class Prototype Topology Distillation for Class-Incremental Source-Free Unsupervised Domain Adaptation
Nov 25, 2024



This paper explores the Class-Incremental Source-Free Unsupervised Domain Adaptation (CI-SFUDA) problem, where the unlabeled target data come incrementally without access to labeled source instances. This problem poses two challenges, the disturbances of similar source-class knowledge to target-class representation learning and the new target knowledge to old ones. To address them, we propose the Multi-Granularity Class Prototype Topology Distillation (GROTO) algorithm, which effectively transfers the source knowledge to the unlabeled class-incremental target domain. Concretely, we design the multi-granularity class prototype self-organization module and prototype topology distillation module. Firstly, the positive classes are mined by modeling two accumulation distributions. Then, we generate reliable pseudo-labels by introducing multi-granularity class prototypes, and use them to promote the positive-class target feature self-organization. Secondly, the positive-class prototypes are leveraged to construct the topological structures of source and target feature spaces. Then, we perform the topology distillation to continually mitigate the interferences of new target knowledge to old ones. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performances on three public datasets.
Mono2Stereo: Monocular Knowledge Transfer for Enhanced Stereo Matching
Nov 14, 2024



The generalization and performance of stereo matching networks are limited due to the domain gap of the existing synthetic datasets and the sparseness of GT labels in the real datasets. In contrast, monocular depth estimation has achieved significant advancements, benefiting from large-scale depth datasets and self-supervised strategies. To bridge the performance gap between monocular depth estimation and stereo matching, we propose leveraging monocular knowledge transfer to enhance stereo matching, namely Mono2Stereo. We introduce knowledge transfer with a two-stage training process, comprising synthetic data pre-training and real-world data fine-tuning. In the pre-training stage, we design a data generation pipeline that synthesizes stereo training data from monocular images. This pipeline utilizes monocular depth for warping and novel view synthesis and employs our proposed Edge-Aware (EA) inpainting module to fill in missing contents in the generated images. In the fine-tuning stage, we introduce a Sparse-to-Dense Knowledge Distillation (S2DKD) strategy encouraging the distributions of predictions to align with dense monocular depths. This strategy mitigates issues with edge blurring in sparse real-world labels and enhances overall consistency. Experimental results demonstrate that our pre-trained model exhibits strong zero-shot generalization capabilities. Furthermore, domain-specific fine-tuning using our pre-trained model and S2DKD strategy significantly increments in-domain performance. The code will be made available soon.
LMHaze: Intensity-aware Image Dehazing with a Large-scale Multi-intensity Real Haze Dataset
Oct 21, 2024



Image dehazing has drawn a significant attention in recent years. Learning-based methods usually require paired hazy and corresponding ground truth (haze-free) images for training. However, it is difficult to collect real-world image pairs, which prevents developments of existing methods. Although several works partially alleviate this issue by using synthetic datasets or small-scale real datasets. The haze intensity distribution bias and scene homogeneity in existing datasets limit the generalization ability of these methods, particularly when encountering images with previously unseen haze intensities. In this work, we present LMHaze, a large-scale, high-quality real-world dataset. LMHaze comprises paired hazy and haze-free images captured in diverse indoor and outdoor environments, spanning multiple scenarios and haze intensities. It contains over 5K high-resolution image pairs, surpassing the size of the biggest existing real-world dehazing dataset by over 25 times. Meanwhile, to better handle images with different haze intensities, we propose a mixture-of-experts model based on Mamba (MoE-Mamba) for dehazing, which dynamically adjusts the model parameters according to the haze intensity. Moreover, with our proposed dataset, we conduct a new large multimodal model (LMM)-based benchmark study to simulate human perception for evaluating dehazed images. Experiments demonstrate that LMHaze dataset improves the dehazing performance in real scenarios and our dehazing method provides better results compared to state-of-the-art methods.