 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiNet: A Mobile Binary Network for Image Classification
Jul 31, 2019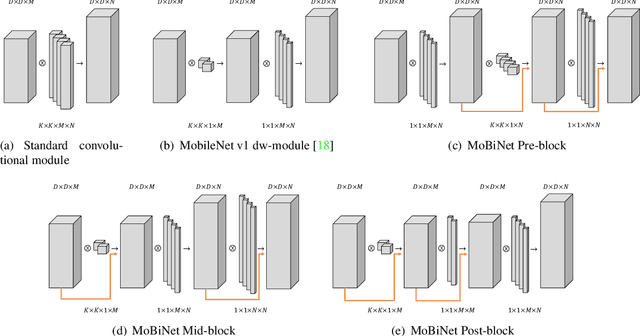

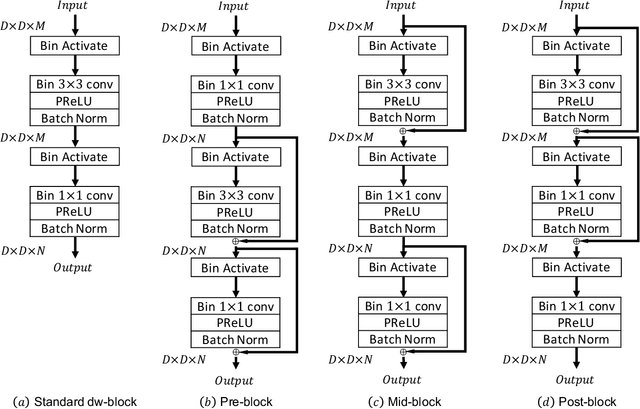
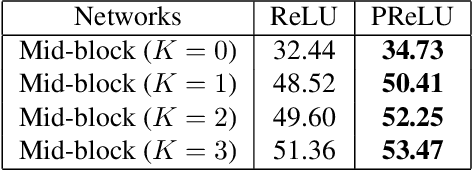
MobileNet and Binary Neural Networks are two among the most widely used techniques to construct deep learning models for performing a variety of tasks on mobile and embedded platforms.In this paper, we present a simple yet efficient scheme to exploit MobileNet binarization at activation function and model weights. However, training a binary network from scratch with separable depth-wise and point-wise convolutions in case of MobileNet is not trivial and prone to divergence. To tackle this training issue, we propose a novel neural network architecture, namely MoBiNet - Mobile Binary Network in which skip connections are manipulated to prevent information loss and vanishing gradient, thus facilitate the training process. More importantly, while existing binary neural networks often make use of cumbersome backbones such as Alex-Net, ResNet, VGG-16 with float-type pre-trained weights initialization, our MoBiNet focuses on binarizing the already-compressed neural networks like MobileNet without the need of a pre-trained model to start with. Therefore, our proposal results in an effectively small model while keeping the accuracy comparable to existing ones. Experiments on ImageNet dataset show the potential of the MoBiNet as it achieves 54.40% top-1 accuracy and dramatically reduces the computational cost with binary operators.
Prediction-Tracking-Segmentation
Apr 05, 2019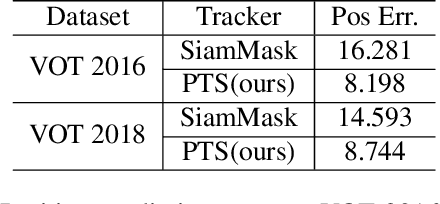
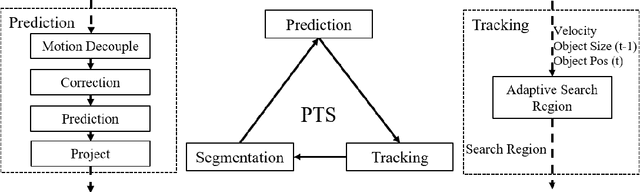
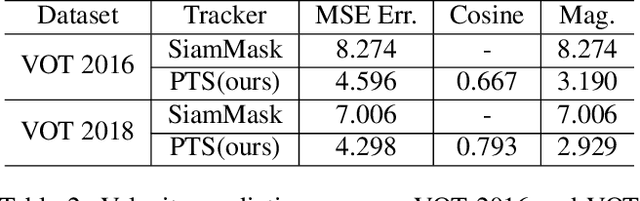

We introduce a prediction driven method for visual tracking and segmentation in videos. Instead of solely relying on matching with appearance cues for tracking, we build a predictive model which guides finding more accurate tracking regions efficiently. With the proposed prediction mechanism, we improve the model robustness against distractions and occlusions during tracking. We demonstrate significant improvements over state-of-the-art methods not only on visual tracking tasks (VOT 2016 and VOT 2018) but also on video segmentation datasets (DAVIS 2016 and DAVIS 2017).
Feature Selective Anchor-Free Module for Single-Shot Object Detection
Mar 02, 2019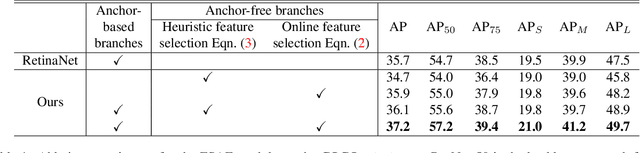
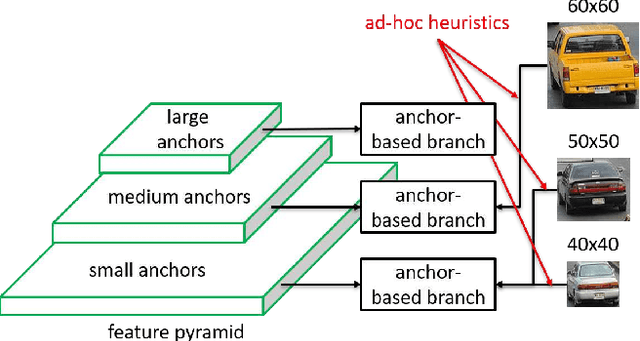
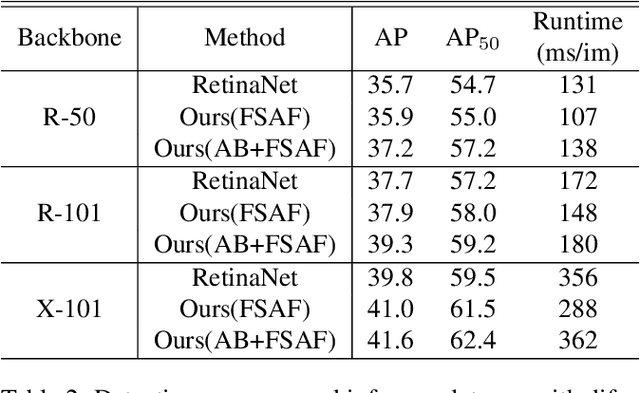
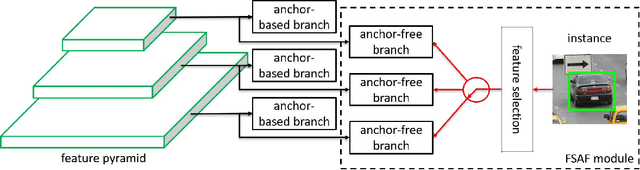
We motivate and present feature selective anchor-free (FSAF) module, a simple and effective building block for single-shot object detectors. It can be plugged into single-shot detectors with feature pyramid structure. The FSAF module addresses two limitations brought up by the conventional anchor-based detection: 1) heuristic-guided feature selection; 2) overlap-based anchor sampling. The general concept of the FSAF module is online feature selection applied to the training of multi-level anchor-free branches. Specifically, an anchor-free branch is attached to each level of the feature pyramid, allowing box encoding and decoding in the anchor-free manner at an arbitrary level. During training, we dynamically assign each instance to the most suitable feature level. At the time of inference, the FSAF module can work jointly with anchor-based branches by outputting predictions in parallel. We instantiate this concept with simple implementations of anchor-free branches and online feature selection strategy. Experimental results on the COCO detection track show that our FSAF module performs better than anchor-based counterparts while being faster. When working jointly with anchor-based branches, the FSAF module robustly improves the baseline RetinaNet by a large margin under various settings, while introducing nearly free inference overhead. And the resulting best model can achieve a state-of-the-art 44.6% mAP, outperforming all existing single-shot detectors on COCO.
An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Dec 21, 2018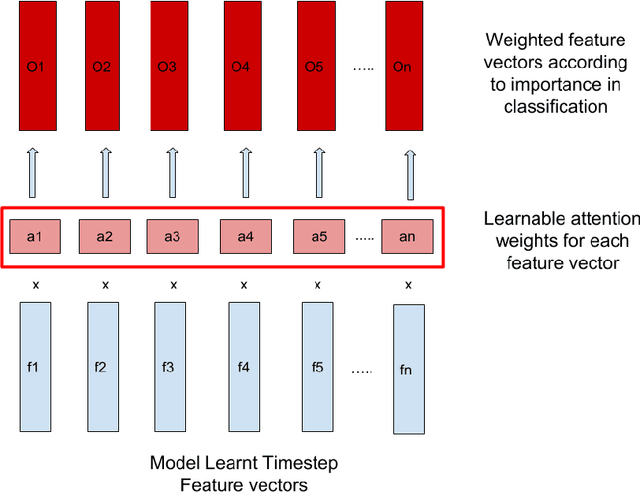

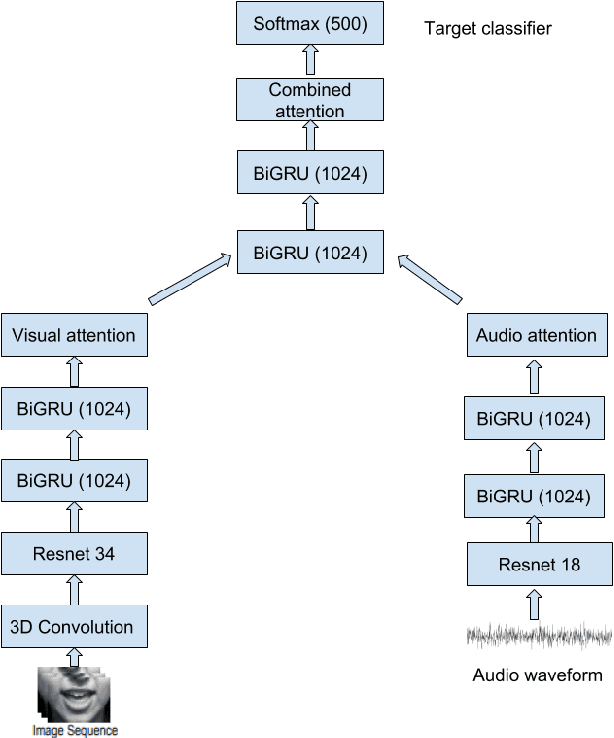
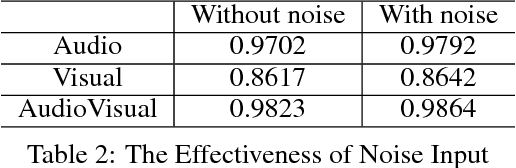
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
Shift-based Primitives for Efficient Convolutional Neural Networks
Sep 25, 2018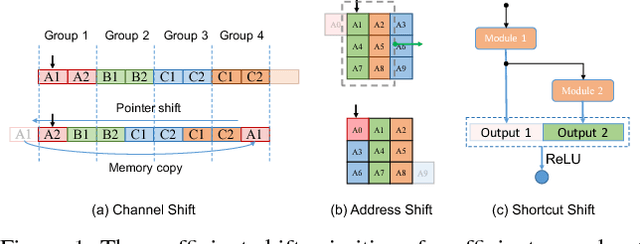

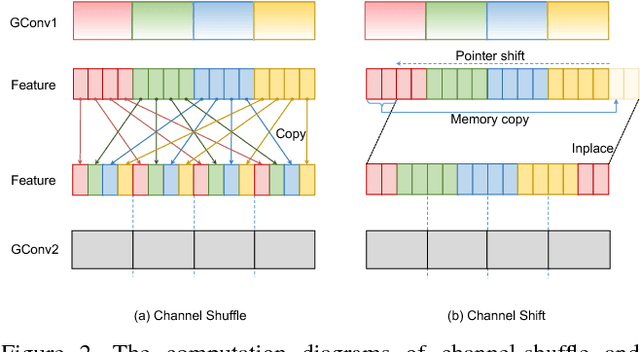

We propose a collection of three shift-based primitives for building efficient compact CNN-based networks. These three primitives (channel shift, address shift, shortcut shift) can reduce the inference time on GPU while maintains the prediction accuracy. These shift-based primitives only moves the pointer but avoids memory copy, thus very fast. For example, the channel shift operation is 12.7x faster compared to channel shuffle in ShuffleNet but achieves the same accuracy. The address shift and channel shift can be merged into the point-wise group convolution and invokes only a single kernel call, taking little time to perform spatial convolution and channel shift. Shortcut shift requires no time to realize residual connection through allocating space in advance. We blend these shift-based primitives with point-wise group convolution and built two inference-efficient CNN architectures named AddressNet and Enhanced AddressNet. Experiments on CIFAR100 and ImageNet datasets show that our models are faster and achieve comparable or better accuracy.
Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection
Sep 23, 2018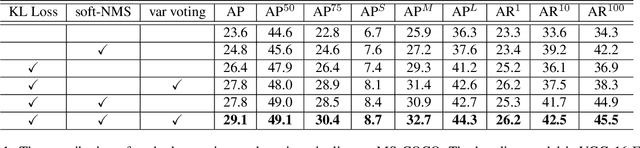
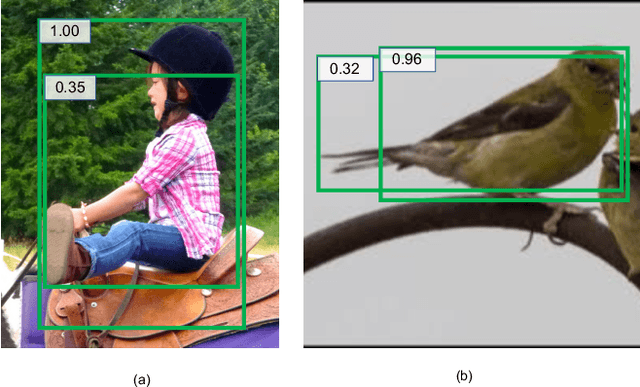
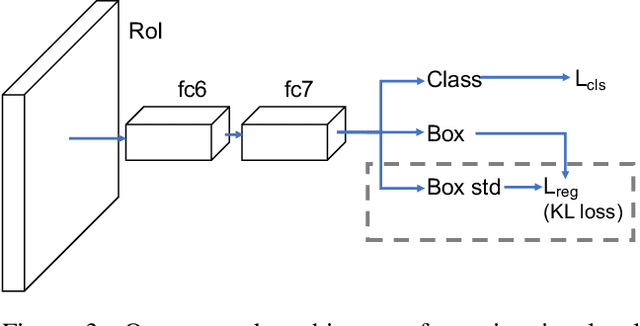
Non-maximum suppression (NMS) is essential for state-of-the-art object detectors to localize object from a set of candidate locations. However, accurate candidate location sometimes is not associated with a high classification score, which leads to object localization failure during NMS. In this paper, we introduce a novel bounding box regression loss for learning bounding box transformation and localization variance together. The resulting localization variance exhibits a strong connection to localization accuracy, which is then utilized in our new non-maximum suppression method to improve localization accuracy for object detection. On MS-COCO, we boost the AP of VGG-16 faster R-CNN from 23.6% to 29.1% with a single model and nearly no additional computational overhead. More importantly, our method is able to improve the AP of ResNet-50 FPN fast R-CNN from 36.8% to 37.8%, which achieves state-of-the-art bounding box refinement result.
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
Aug 26, 2018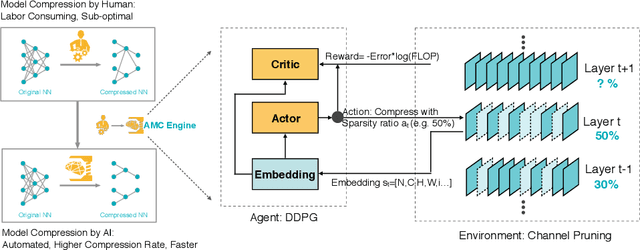

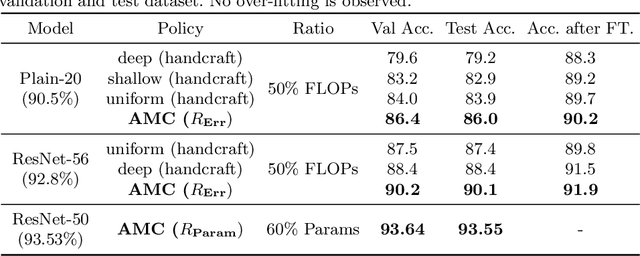
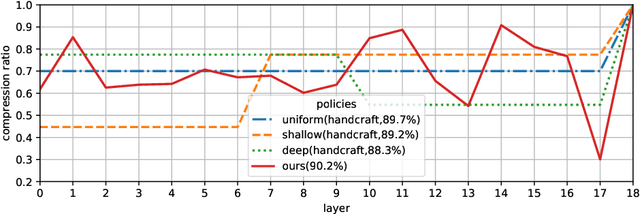
Model compression is a critical technique to efficiently deploy neural network models on mobile devices which have limited computation resources and tight power budgets. Conventional model compression techniques rely on hand-crafted heuristics and rule-based policies that require domain experts to explore the large design space trading off among model size, speed, and accuracy, which is usually sub-optimal and time-consuming. In this paper, we propose AutoML for Model Compression (AMC) which leverage reinforcement learning to provide the model compression policy. This learning-based compression policy outperforms conventional rule-based compression policy by having higher compression ratio, better preserving the accuracy and freeing human labor. Under 4x FLOPs reduction, we achieved 2.7% better accuracy than the hand- crafted model compression policy for VGG-16 on ImageNet. We applied this automated, push-the-button compression pipeline to MobileNet and achieved 1.81x speedup of measured inference latency on an Android phone and 1.43x speedup on the Titan XP GPU, with only 0.1% loss of ImageNet Top-1 accuracy.
Vehicle Traffic Driven Camera Placement for Better Metropolis Security Surveillance
Aug 20, 2018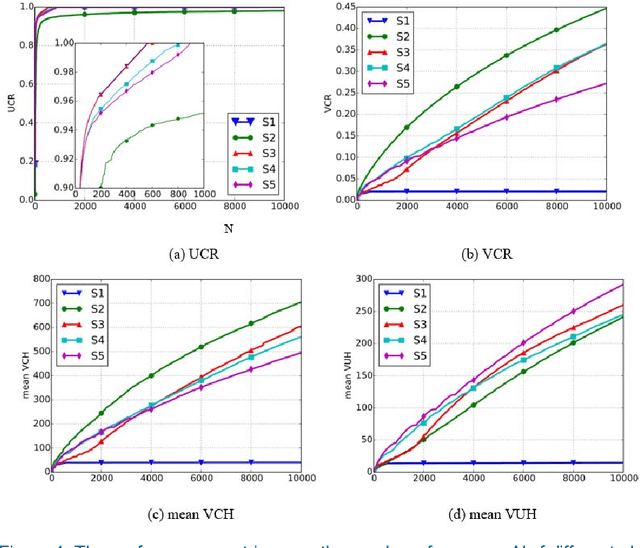
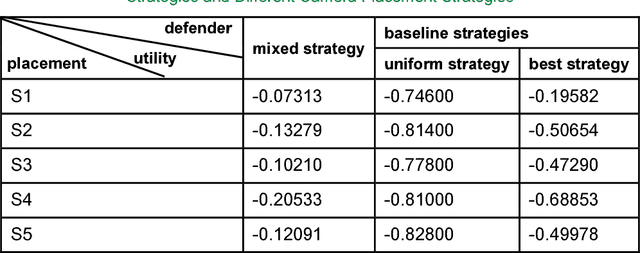

Security surveillance is one of the most important issues in smart cities, especially in an era of terrorism. Deploying a number of (video) cameras is a common surveillance approach. Given the never-ending power offered by vehicles to metropolises, exploiting vehicle traffic to design camera placement strategies could potentially facilitate security surveillance. This article constitutes the first effort toward building the linkage between vehicle traffic and security surveillance, which is a critical problem for smart cities. We expect our study could influence the decision making of surveillance camera placement, and foster more research of principled ways of security surveillance beneficial to our physical-world life. Code has been made publicly available.
Single Image Super-resolution via a Lightweight Residual Convolutional Neural Network
Dec 06, 2017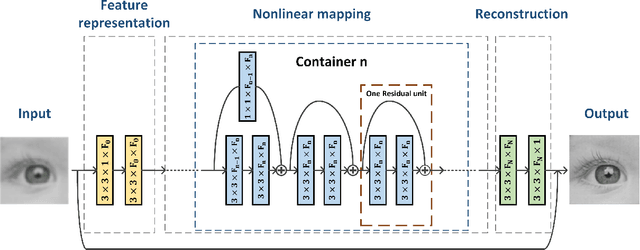
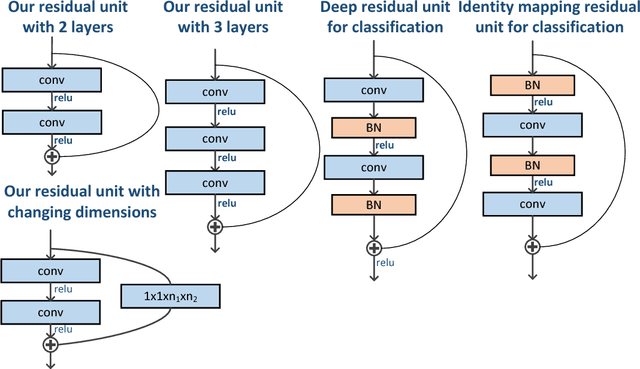
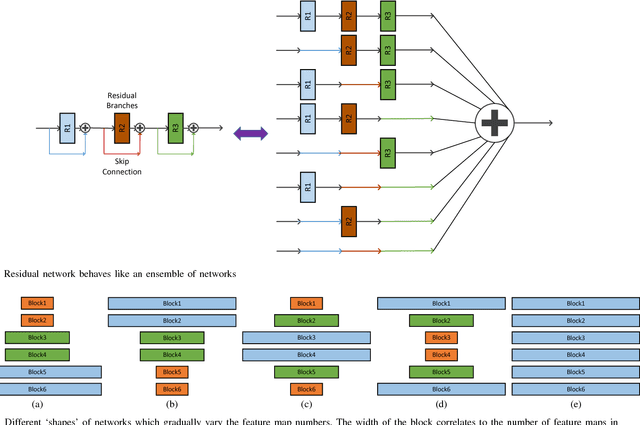
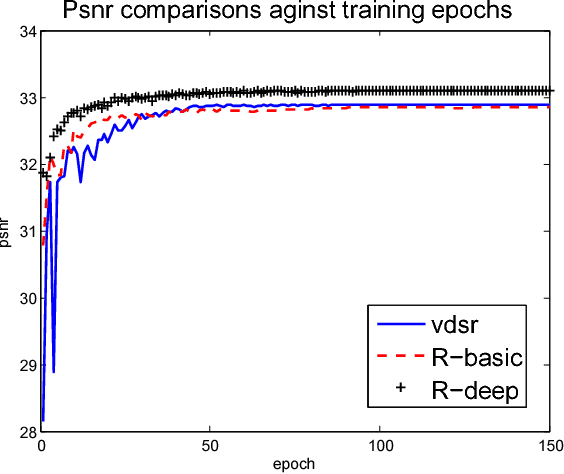
Recent years have witnessed great success of convolutional neural network (CNN) for various problems both in low and high level visions. Especially noteworthy is the residual network which was originally proposed to handle high-level vision problems and enjoys several merits. This paper aims to extend the merits of residual network, such as skip connection induced fast training, for a typical low-level vision problem, i.e., single image super-resolution. In general, the two main challenges of existing deep CNN for supper-resolution lie in the gradient exploding/vanishing problem and large numbers of parameters or computational cost as CNN goes deeper. Correspondingly, the skip connections or identity mapping shortcuts are utilized to avoid gradient exploding/vanishing problem. In addition, the skip connections have naturally centered the activation which led to better performance. To tackle with the second problem, a lightweight CNN architecture which has carefully designed width, depth and skip connections was proposed. In particular, a strategy of gradually varying the shape of network has been proposed for residual network. Different residual architectures for image super-resolution have also been compared. Experimental results have demonstrated that the proposed CNN model can not only achieve state-of-the-art PSNR and SSIM results for single image super-resolution but also produce visually pleasant results. This paper has extended the mmm 2017 oral conference paper with a considerable new analyses and more experiments especially from the perspective of centering activations and ensemble behaviors of residual network.
Estimated Depth Map Helps Image Classification
Sep 20, 2017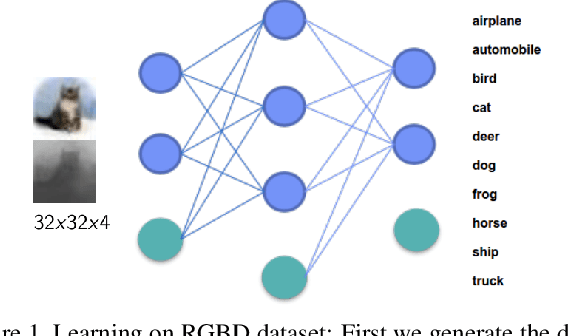
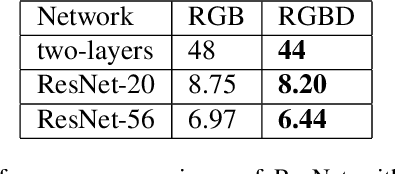


We consider image classification with estimated depth. This problem falls into the domain of transfer learning, since we are using a model trained on a set of depth images to generate depth maps (additional features) for use in another classification problem using another disjoint set of images. It's challenging as no direct depth information is provided. Though depth estimation has been well studied, none have attempted to aid image classification with estimated depth. Therefore, we present a way of transferring domain knowledge on depth estimation to a separate image classification task over a disjoint set of train, and test data. We build a RGBD dataset based on RGB dataset and do image classification on it. Then evaluation the performance of neural networks on the RGBD dataset compared to the RGB dataset. From our experiments, the benefit is significant with shallow and deep networks. It improves ResNet-20 by 0.55% and ResNet-56 by 0.53%. Our code and dataset are available publicly.