 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastDiagnosis: Enhancing Interpretability in Lung Nodule Diagnosis Using Contrastive Learning
Mar 08, 2024With the ongoing development of deep learning, an increasing number of AI models have surpassed the performance levels of human clinical practitioners. However, the prevalence of AI diagnostic products in actual clinical practice remains significantly lower than desired. One crucial reason for this gap is the so-called `black box' nature of AI models. Clinicians' distrust of black box models has directly hindered the clinical deployment of AI products. To address this challenge, we propose ContrastDiagnosis, a straightforward yet effective interpretable diagnosis framework. This framework is designed to introduce inherent transparency and provide extensive post-hoc explainability for deep learning model, making them more suitable for clinical medical diagnosis. ContrastDiagnosis incorporates a contrastive learning mechanism to provide a case-based reasoning diagnostic rationale, enhancing the model's transparency and also offers post-hoc interpretability by highlighting similar areas. High diagnostic accuracy was achieved with AUC of 0.977 while maintain a high transparency and explainability.
DynaPipe: Optimizing Multi-task Training through Dynamic Pipelines
Nov 17, 2023



Multi-task model training has been adopted to enable a single deep neural network model (often a large language model) to handle multiple tasks (e.g., question answering and text summarization). Multi-task training commonly receives input sequences of highly different lengths due to the diverse contexts of different tasks. Padding (to the same sequence length) or packing (short examples into long sequences of the same length) is usually adopted to prepare input samples for model training, which is nonetheless not space or computation efficient. This paper proposes a dynamic micro-batching approach to tackle sequence length variation and enable efficient multi-task model training. We advocate pipeline-parallel training of the large model with variable-length micro-batches, each of which potentially comprises a different number of samples. We optimize micro-batch construction using a dynamic programming-based approach, and handle micro-batch execution time variation through dynamic pipeline and communication scheduling, enabling highly efficient pipeline training. Extensive evaluation on the FLANv2 dataset demonstrates up to 4.39x higher training throughput when training T5, and 3.25x when training GPT, as compared with packing-based baselines. DynaPipe's source code is publicly available at https://github.com/awslabs/optimizing-multitask-training-through-dynamic-pipelines.
Serving Deep Learning Model in Relational Databases
Oct 10, 2023



Serving deep learning (DL) models on relational data has become a critical requirement across diverse commercial and scientific domains, sparking growing interest recently. In this visionary paper, we embark on a comprehensive exploration of representative architectures to address the requirement. We highlight three pivotal paradigms: The state-of-the-artDL-Centricarchitecture offloadsDL computations to dedicated DL frameworks. The potential UDF-Centric architecture encapsulates one or more tensor computations into User Defined Functions (UDFs) within the database system. The potentialRelation-Centricarchitecture aims to represent a large-scale tensor computation through relational operators. While each of these architectures demonstrates promise in specific use scenarios, we identify urgent requirements for seamless integration of these architectures and the middle ground between these architectures. We delve into the gaps that impede the integration and explore innovative strategies to close them. We present a pathway to establish a novel database system for enabling a broad class of data-intensive DL inference applications.
Target-independent XLA optimization using Reinforcement Learning
Aug 28, 2023An important challenge in Machine Learning compilers like XLA is multi-pass optimization and analysis. There has been recent interest chiefly in XLA target-dependent optimization on the graph-level, subgraph-level, and kernel-level phases. We specifically focus on target-independent optimization XLA HLO pass ordering: our approach aims at finding the optimal sequence of compiler optimization passes, which is decoupled from target-dependent optimization. However, there is little domain specific study in pass ordering for XLA HLO. To this end, we propose introducing deep Reinforcement Learning (RL) based search for optimal XLA HLO pass ordering. We also propose enhancements to the deep RL algorithms to further improve optimal search performance and open the research direction for domain-specific guidance for RL. We create an XLA Gym experimentation framework as a tool to enable RL algorithms to interact with the compiler for passing optimizations and thereby train agents. Overall, in our experimentation we observe an average of $13.3\%$ improvement in operation count reduction on a benchmark of GPT-2 training graphs and $10.4\%$ improvement on a diverse benchmark including GPT-2, BERT, and ResNet graphs using the proposed approach over the compiler's default phase ordering.
$\mathrm{SAM^{Med}}$: A medical image annotation framework based on large vision model
Jul 11, 2023



Recently, large vision model, Segment Anything Model (SAM), has revolutionized the computer vision field, especially for image segmentation. SAM presented a new promptable segmentation paradigm that exhibit its remarkable zero-shot generalization ability. An extensive researches have explore the potential and limits of SAM in various downstream tasks. In this study, we presents $\mathrm{SAM^{Med}}$, an enhanced framework for medical image annotation that leverages the capabilities of SAM. $\mathrm{SAM^{Med}}$ framework consisted of two submodules, namely $\mathrm{SAM^{assist}}$ and $\mathrm{SAM^{auto}}$. The $\mathrm{SAM^{assist}}$ demonstrates the generalization ability of SAM to the downstream medical segmentation task using the prompt-learning approach. Results show a significant improvement in segmentation accuracy with only approximately 5 input points. The $\mathrm{SAM^{auto}}$ model aims to accelerate the annotation process by automatically generating input prompts. The proposed SAP-Net model achieves superior segmentation performance with only five annotated slices, achieving an average Dice coefficient of 0.80 and 0.82 for kidney and liver segmentation, respectively. Overall, $\mathrm{SAM^{Med}}$ demonstrates promising results in medical image annotation. These findings highlight the potential of leveraging large-scale vision models in medical image annotation tasks.
RAF: Holistic Compilation for Deep Learning Model Training
Mar 08, 2023



As deep learning is pervasive in modern applications, many deep learning frameworks are presented for deep learning practitioners to develop and train DNN models rapidly. Meanwhile, as training large deep learning models becomes a trend in recent years, the training throughput and memory footprint are getting crucial. Accordingly, optimizing training workloads with compiler optimizations is inevitable and getting more and more attentions. However, existing deep learning compilers (DLCs) mainly target inference and do not incorporate holistic optimizations, such as automatic differentiation and automatic mixed precision, in training workloads. In this paper, we present RAF, a deep learning compiler for training. Unlike existing DLCs, RAF accepts a forward model and in-house generates a training graph. Accordingly, RAF is able to systematically consolidate graph optimizations for performance, memory and distributed training. In addition, to catch up to the state-of-the-art performance with hand-crafted kernel libraries as well as tensor compilers, RAF proposes an operator dialect mechanism to seamlessly integrate all possible kernel implementations. We demonstrate that by in-house training graph generation and operator dialect mechanism, we are able to perform holistic optimizations and achieve either better training throughput or larger batch size against PyTorch (eager and torchscript mode), XLA, and DeepSpeed for popular transformer models on GPUs.
Decoupled Model Schedule for Deep Learning Training
Feb 16, 2023Recent years have seen an increase in the development of large deep learning (DL) models, which makes training efficiency crucial. Common practice is struggling with the trade-off between usability and performance. On one hand, DL frameworks such as PyTorch use dynamic graphs to facilitate model developers at a price of sub-optimal model training performance. On the other hand, practitioners propose various approaches to improving the training efficiency by sacrificing some of the flexibility, ranging from making the graph static for more thorough optimization (e.g., XLA) to customizing optimization towards large-scale distributed training (e.g., DeepSpeed and Megatron-LM). In this paper, we aim to address the tension between usability and training efficiency through separation of concerns. Inspired by DL compilers that decouple the platform-specific optimizations of a tensor-level operator from its arithmetic definition, this paper proposes a schedule language to decouple model execution from definition. Specifically, the schedule works on a PyTorch model and uses a set of schedule primitives to convert the model for common model training optimizations such as high-performance kernels, effective 3D parallelism, and efficient activation checkpointing. Compared to existing optimization solutions, we optimize the model as-needed through high-level primitives, and thus preserving programmability and debuggability for users to a large extent. Our evaluation results show that by scheduling the existing hand-crafted optimizations in a systematic way, we are able to improve training throughput by up to 3.35x on a single machine with 8 NVIDIA V100 GPUs, and by up to 1.32x on multiple machines with up to 64 GPUs, when compared to the out-of-the-box performance of DeepSpeed and Megatron-LM.
Lidar Upsampling with Sliced Wasserstein Distance
Jan 31, 2023



Lidar became an important component of the perception systems in autonomous driving. But challenges of training data acquisition and annotation made emphasized the role of the sensor to sensor domain adaptation. In this work, we address the problem of lidar upsampling. Learning on lidar point clouds is rather a challenging task due to their irregular and sparse structure. Here we propose a method for lidar point cloud upsampling which can reconstruct fine-grained lidar scan patterns. The key idea is to utilize edge-aware dense convolutions for both feature extraction and feature expansion. Additionally applying a more accurate Sliced Wasserstein Distance facilitates learning of the fine lidar sweep structures. This in turn enables our method to employ a one-stage upsampling paradigm without the need for coarse and fine reconstruction. We conduct several experiments to evaluate our method and demonstrate that it provides better upsampling.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022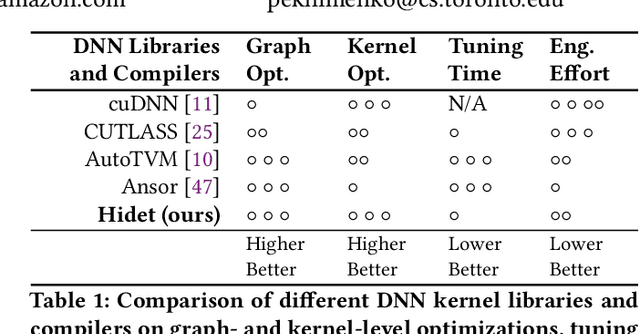
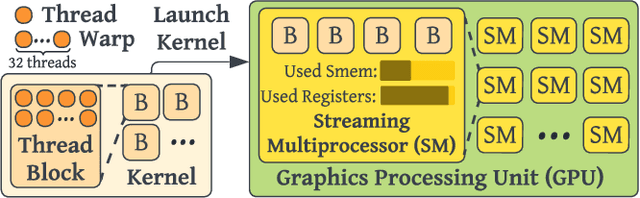

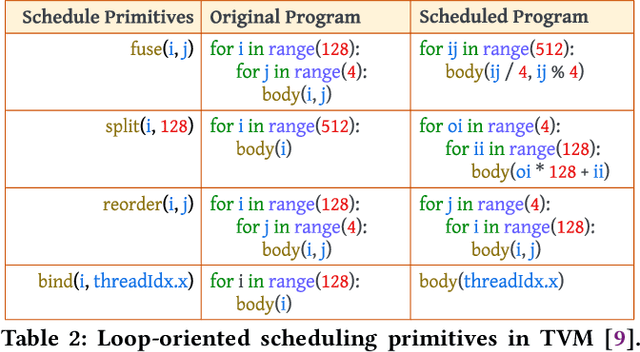
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
SoftPool++: An Encoder-Decoder Network for Point Cloud Completion
May 08, 2022
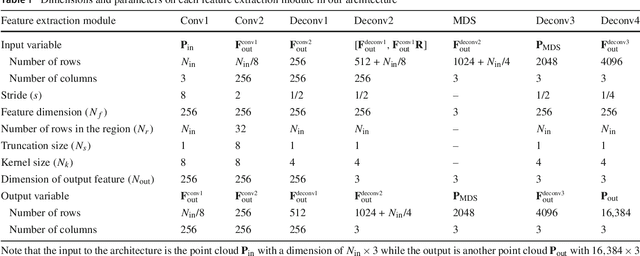
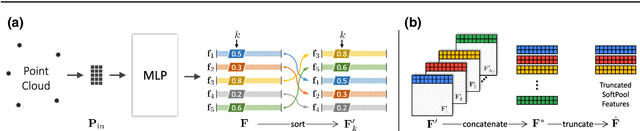
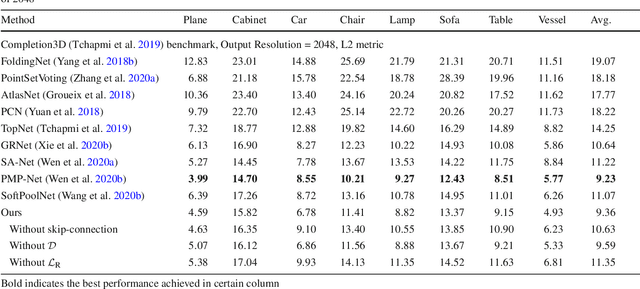
We propose a novel convolutional operator for the task of point cloud completion. One striking characteristic of our approach is that, conversely to related work it does not require any max-pooling or voxelization operation. Instead, the proposed operator used to learn the point cloud embedding in the encoder extracts permutation-invariant features from the point cloud via a soft-pooling of feature activations, which are able to preserve fine-grained geometric details. These features are then passed on to a decoder architecture. Due to the compression in the encoder, a typical limitation of this type of architectures is that they tend to lose parts of the input shape structure. We propose to overcome this limitation by using skip connections specifically devised for point clouds, where links between corresponding layers in the encoder and the decoder are established. As part of these connections, we introduce a transformation matrix that projects the features from the encoder to the decoder and vice-versa. The quantitative and qualitative results on the task of object completion from partial scans on the ShapeNet dataset show that incorporating our approach achieves state-of-the-art performance in shape completion both at low and high resolutions.
* Accepted in International Journal of Computer Vision