 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanIR: Large-Scale Urban Scene Inverse Rendering from a Single Video
Jun 16, 2023



We show how to build a model that allows realistic, free-viewpoint renderings of a scene under novel lighting conditions from video. Our method -- UrbanIR: Urban Scene Inverse Rendering -- computes an inverse graphics representation from the video. UrbanIR jointly infers shape, albedo, visibility, and sun and sky illumination from a single video of unbounded outdoor scenes with unknown lighting. UrbanIR uses videos from cameras mounted on cars (in contrast to many views of the same points in typical NeRF-style estimation). As a result, standard methods produce poor geometry estimates (for example, roofs), and there are numerous ''floaters''. Errors in inverse graphics inference can result in strong rendering artifacts. UrbanIR uses novel losses to control these and other sources of error. UrbanIR uses a novel loss to make very good estimates of shadow volumes in the original scene. The resulting representations facilitate controllable editing, delivering photorealistic free-viewpoint renderings of relit scenes and inserted objects. Qualitative evaluation demonstrates strong improvements over the state-of-the-art.
CLR-GAM: Contrastive Point Cloud Learning with Guided Augmentation and Feature Mapping
Feb 28, 2023



Point cloud data plays an essential role in robotics and self-driving applications. Yet, annotating point cloud data is time-consuming and nontrivial while they enable learning discriminative 3D representations that empower downstream tasks, such as classification and segmentation. Recently, contrastive learning-based frameworks have shown promising results for learning 3D representations in a self-supervised manner. However, existing contrastive learning methods cannot precisely encode and associate structural features and search the higher dimensional augmentation space efficiently. In this paper, we present CLR-GAM, a novel contrastive learning-based framework with Guided Augmentation (GA) for efficient dynamic exploration strategy and Guided Feature Mapping (GFM) for similar structural feature association between augmented point clouds. We empirically demonstrate that the proposed approach achieves state-of-the-art performance on both simulated and real-world 3D point cloud datasets for three different downstream tasks, i.e., 3D point cloud classification, few-shot learning, and object part segmentation.
Shape-aware Text-driven Layered Video Editing
Jan 30, 2023



Temporal consistency is essential for video editing applications. Existing work on layered representation of videos allows propagating edits consistently to each frame. These methods, however, can only edit object appearance rather than object shape changes due to the limitation of using a fixed UV mapping field for texture atlas. We present a shape-aware, text-driven video editing method to tackle this challenge. To handle shape changes in video editing, we first propagate the deformation field between the input and edited keyframe to all frames. We then leverage a pre-trained text-conditioned diffusion model as guidance for refining shape distortion and completing unseen regions. The experimental results demonstrate that our method can achieve shape-aware consistent video editing and compare favorably with the state-of-the-art.
Learning Road Scene-level Representations via Semantic Region Prediction
Jan 02, 2023



In this work, we tackle two vital tasks in automated driving systems, i.e., driver intent prediction and risk object identification from egocentric images. Mainly, we investigate the question: what would be good road scene-level representations for these two tasks? We contend that a scene-level representation must capture higher-level semantic and geometric representations of traffic scenes around ego-vehicle while performing actions to their destinations. To this end, we introduce the representation of semantic regions, which are areas where ego-vehicles visit while taking an afforded action (e.g., left-turn at 4-way intersections). We propose to learn scene-level representations via a novel semantic region prediction task and an automatic semantic region labeling algorithm. Extensive evaluations are conducted on the HDD and nuScenes datasets, and the learned representations lead to state-of-the-art performance for driver intention prediction and risk object identification.
Audio-Visual Speech Enhancement and Separation by Leveraging Multi-Modal Self-Supervised Embeddings
Oct 31, 2022



AV-HuBERT, a multi-modal self-supervised learning model, has been shown to be effective for categorical problems such as automatic speech recognition and lip-reading. This suggests that useful audio-visual speech representations can be obtained via utilizing multi-modal self-supervised embeddings. Nevertheless, it is unclear if such representations can be generalized to solve real-world multi-modal AV regression tasks, such as audio-visual speech enhancement (AVSE) and audio-visual speech separation (AVSS). In this study, we leveraged the pre-trained AV-HuBERT model followed by an SE module for AVSE and AVSS. Comparative experimental results demonstrate that our proposed model performs better than the state-of-the-art AVSE and traditional audio-only SE models. In summary, our results confirm the effectiveness of our proposed model for the AVSS task with proper fine-tuning strategies, demonstrating that multi-modal self-supervised embeddings obtained from AV-HUBERT can be generalized to audio-visual regression tasks.
Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Sep 27, 2022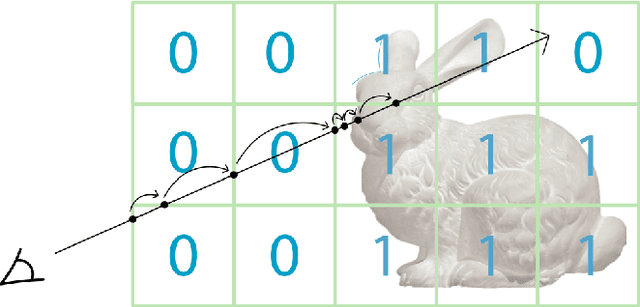
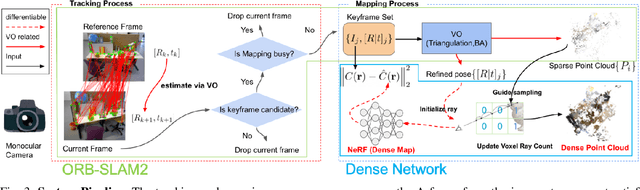
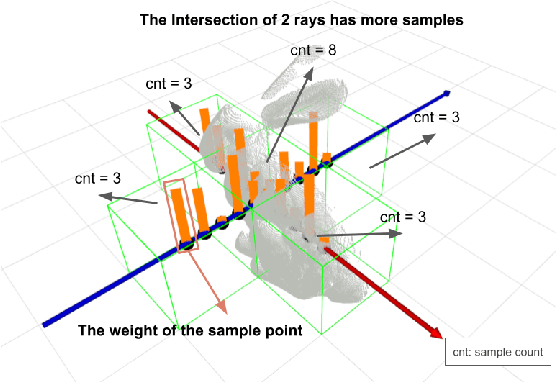

A spatial AI that can perform complex tasks through visual signals and cooperate with humans is highly anticipated. To achieve this, we need a visual SLAM that easily adapts to new scenes without pre-training and generates dense maps for downstream tasks in real-time. None of the previous learning-based and non-learning-based visual SLAMs satisfy all needs due to the intrinsic limitations of their components. In this work, we develop a visual SLAM named Orbeez-SLAM, which successfully collaborates with implicit neural representation (NeRF) and visual odometry to achieve our goals. Moreover, Orbeez-SLAM can work with the monocular camera since it only needs RGB inputs, making it widely applicable to the real world. We validate its effectiveness on various challenging benchmarks. Results show that our SLAM is up to 800x faster than the strong baseline with superior rendering outcomes.
MetaDIP: Accelerating Deep Image Prior with Meta Learning
Sep 18, 2022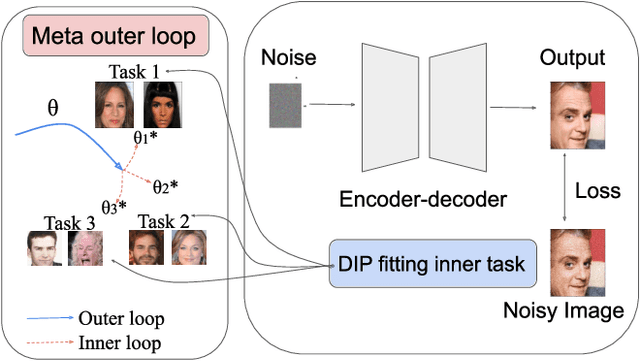
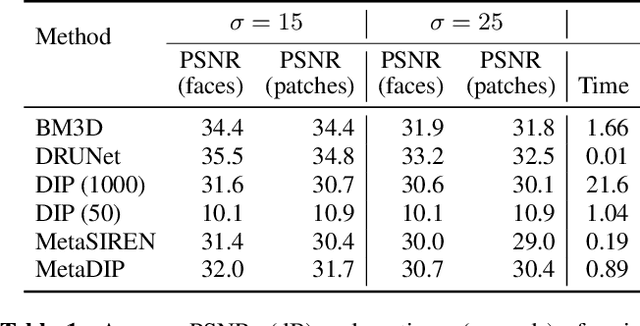
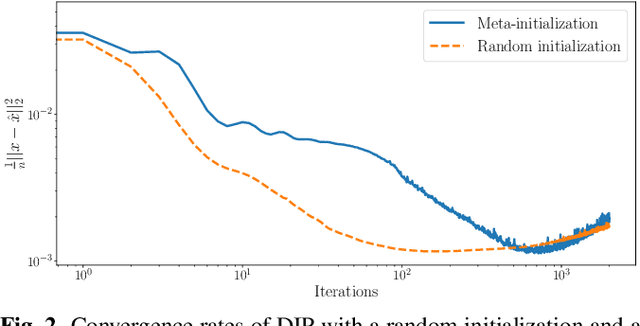
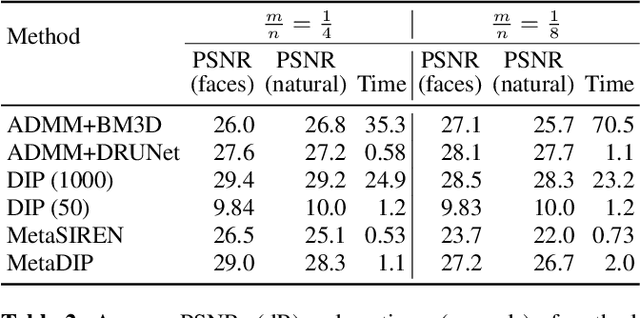
Deep image prior (DIP) is a recently proposed technique for solving imaging inverse problems by fitting the reconstructed images to the output of an untrained convolutional neural network. Unlike pretrained feedforward neural networks, the same DIP can generalize to arbitrary inverse problems, from denoising to phase retrieval, while offering competitive performance at each task. The central disadvantage of DIP is that, while feedforward neural networks can reconstruct an image in a single pass, DIP must gradually update its weights over hundreds to thousands of iterations, at a significant computational cost. In this work we use meta-learning to massively accelerate DIP-based reconstructions. By learning a proper initialization for the DIP weights, we demonstrate a 10x improvement in runtimes across a range of inverse imaging tasks. Moreover, we demonstrate that a network trained to quickly reconstruct faces also generalizes to reconstructing natural image patches.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022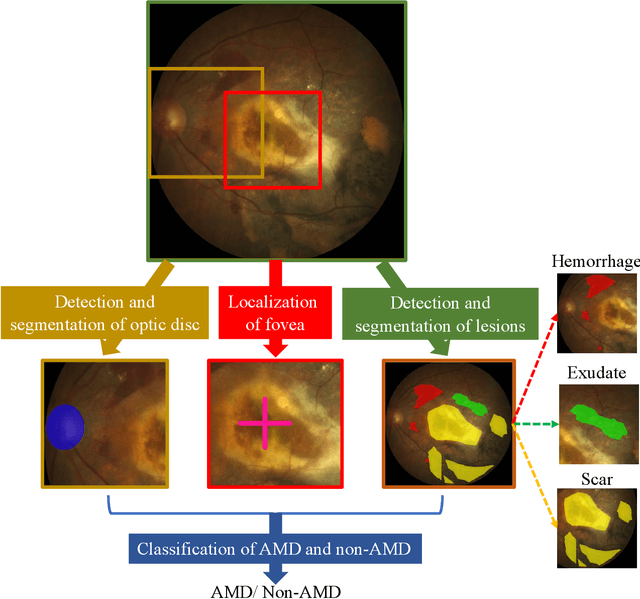

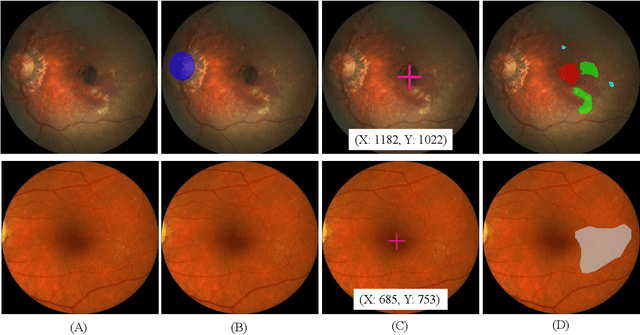
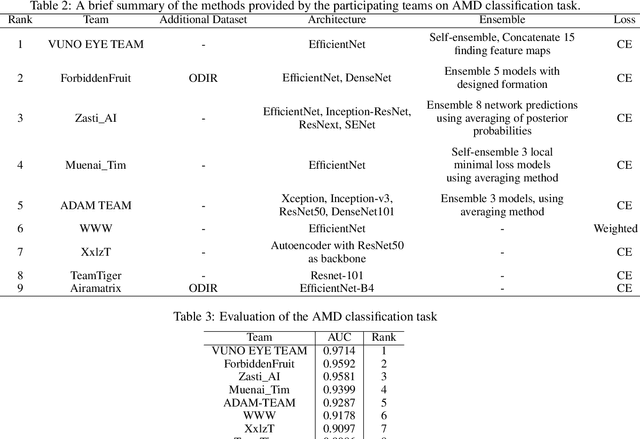
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Semi-supervised 3D Object Detection via Temporal Graph Neural Networks
Feb 01, 2022

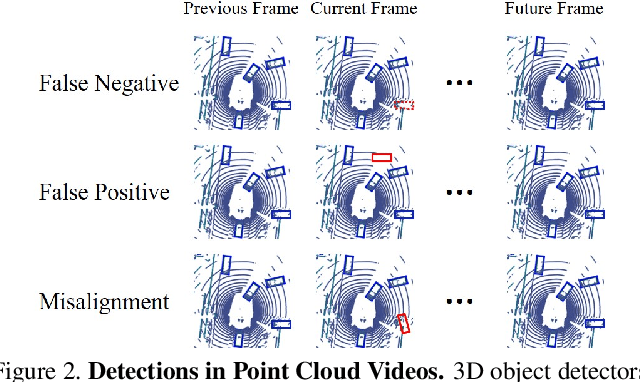
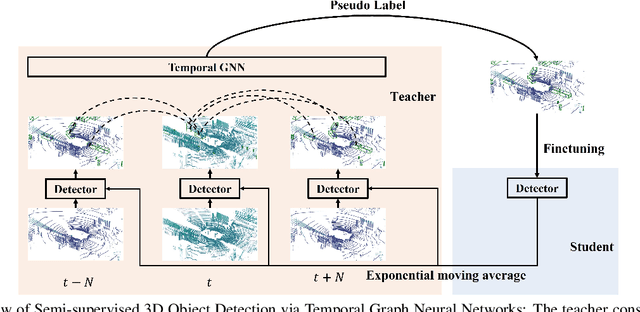
3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames. After semi-supervised learning, our method achieves state-of-the-art detection performance on the challenging nuScenes and H3D benchmarks, compared to baselines trained on the same amount of labeled data. Project and code are released at https://www.jianrenw.com/SOD-TGNN/.
Stage Conscious Attention Network (SCAN) : A Demonstration-Conditioned Policy for Few-Shot Imitation
Dec 04, 2021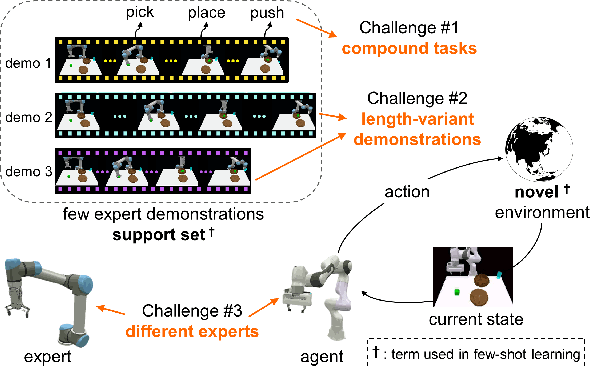
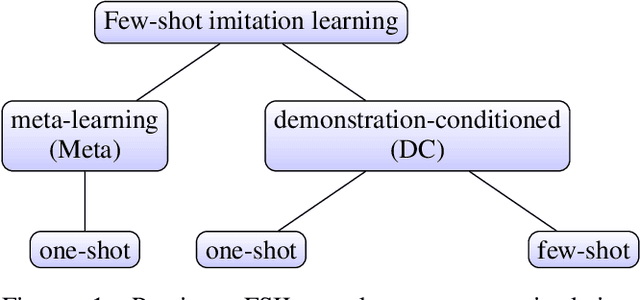

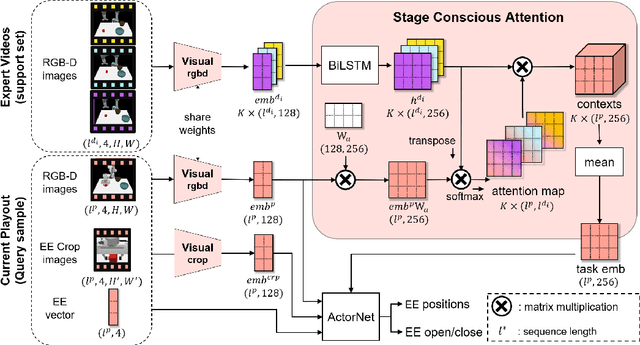
In few-shot imitation learning (FSIL), using behavioral cloning (BC) to solve unseen tasks with few expert demonstrations becomes a popular research direction. The following capabilities are essential in robotics applications: (1) Behaving in compound tasks that contain multiple stages. (2) Retrieving knowledge from few length-variant and misalignment demonstrations. (3) Learning from a different expert. No previous work can achieve these abilities at the same time. In this work, we conduct FSIL problem under the union of above settings and introduce a novel stage conscious attention network (SCAN) to retrieve knowledge from few demonstrations simultaneously. SCAN uses an attention module to identify each stage in length-variant demonstrations. Moreover, it is designed under demonstration-conditioned policy that learns the relationship between experts and agents. Experiment results show that SCAN can learn from different experts without fine-tuning and outperform baselines in complicated compound tasks with explainable visualization.