 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Reinforcement Learning for Audio-Visual Speech Enhancement
Mar 17, 2026In existing Audio-Visual Speech Enhancement (AVSE) methods, objectives such as Scale-Invariant Signal-to-Noise Ratio (SI-SNR) and Mean Squared Error (MSE) are widely used; however, they often correlate poorly with perceptual quality and provide limited interpretability for optimization. This work proposes a reinforcement learning-based AVSE framework with a Large Language Model (LLM)-based interpretable reward model. An audio LLM generates natural language descriptions of enhanced speech, which are converted by a sentiment analysis model into a 1-5 rating score serving as the PPO reward for fine-tuning a pretrained AVSE model. Compared with scalar metrics, LLM-generated feedback is semantically rich and explicitly describes improvements in speech quality. Experiments on the 4th COG-MHEAR AVSE Challenge (AVSEC-4) dataset show that the proposed method outperforms a supervised baseline and a DNSMOS-based RL baseline in PESQ, STOI, neural quality metrics, and subjective listening tests.
Towards Environmental Preference Based Speech Enhancement For Individualised Multi-Modal Hearing Aids
Feb 26, 2024



Since the advent of Deep Learning (DL), Speech Enhancement (SE) models have performed well under a variety of noise conditions. However, such systems may still introduce sonic artefacts, sound unnatural, and restrict the ability for a user to hear ambient sound which may be of importance. Hearing Aid (HA) users may wish to customise their SE systems to suit their personal preferences and day-to-day lifestyle. In this paper, we introduce a preference learning based SE (PLSE) model for future multi-modal HAs that can contextually exploit audio information to improve listening comfort, based upon the preferences of the user. The proposed system estimates the Signal-to-noise ratio (SNR) as a basic objective speech quality measure which quantifies the relative amount of background noise present in speech, and directly correlates to the intelligibility of the signal. Additionally, to provide contextual information we predict the acoustic scene in which the user is situated. These tasks are achieved via a multi-task DL model, which surpasses the performance of inferring the acoustic scene or SNR separately, by jointly leveraging a shared encoded feature space. These environmental inferences are exploited in a preference elicitation framework, which linearly learns a set of predictive functions to determine the target SNR of an AV (Audio-Visual) SE system. By greatly reducing noise in challenging listening conditions, and by novelly scaling the output of the SE model, we are able to provide HA users with contextually individualised SE. Preliminary results suggest an improvement over the non-individualised baseline model in some participants.
Deep Complex U-Net with Conformer for Audio-Visual Speech Enhancement
Sep 20, 2023Recent studies have increasingly acknowledged the advantages of incorporating visual data into speech enhancement (SE) systems. In this paper, we introduce a novel audio-visual SE approach, termed DCUC-Net (deep complex U-Net with conformer network). The proposed DCUC-Net leverages complex domain features and a stack of conformer blocks. The encoder and decoder of DCUC-Net are designed using a complex U-Net-based framework. The audio and visual signals are processed using a complex encoder and a ResNet-18 model, respectively. These processed signals are then fused using the conformer blocks and transformed into enhanced speech waveforms via a complex decoder. The conformer blocks consist of a combination of self-attention mechanisms and convolutional operations, enabling DCUC-Net to effectively capture both global and local audio-visual dependencies. Our experimental results demonstrate the effectiveness of DCUC-Net, as it outperforms the baseline model from the COG-MHEAR AVSE Challenge 2023 by a notable margin of 0.14 in terms of PESQ. Additionally, the proposed DCUC-Net performs comparably to a state-of-the-art model and outperforms all other compared models on the Taiwan Mandarin speech with video (TMSV) dataset.
Audio-Visual Speech Enhancement Using Self-supervised Learning to Improve Speech Intelligibility in Cochlear Implant Simulations
Jul 15, 2023



Individuals with hearing impairments face challenges in their ability to comprehend speech, particularly in noisy environments. The aim of this study is to explore the effectiveness of audio-visual speech enhancement (AVSE) in enhancing the intelligibility of vocoded speech in cochlear implant (CI) simulations. Notably, the study focuses on a challenged scenario where there is limited availability of training data for the AVSE task. To address this problem, we propose a novel deep neural network framework termed Self-Supervised Learning-based AVSE (SSL-AVSE). The proposed SSL-AVSE combines visual cues, such as lip and mouth movements, from the target speakers with corresponding audio signals. The contextually combined audio and visual data are then fed into a Transformer-based SSL AV-HuBERT model to extract features, which are further processed using a BLSTM-based SE model. The results demonstrate several key findings. Firstly, SSL-AVSE successfully overcomes the issue of limited data by leveraging the AV-HuBERT model. Secondly, by fine-tuning the AV-HuBERT model parameters for the target SE task, significant performance improvements are achieved. Specifically, there is a notable enhancement in PESQ (Perceptual Evaluation of Speech Quality) from 1.43 to 1.67 and in STOI (Short-Time Objective Intelligibility) from 0.70 to 0.74. Furthermore, the performance of the SSL-AVSE was evaluated using CI vocoded speech to assess the intelligibility for CI users. Comparative experimental outcomes reveal that in the presence of dynamic noises encountered during human conversations, SSL-AVSE exhibits a substantial improvement. The NCM (Normal Correlation Matrix) values indicate an increase of 26.5% to 87.2% compared to the noisy baseline.
Audio-Visual Speech Enhancement and Separation by Leveraging Multi-Modal Self-Supervised Embeddings
Oct 31, 2022



AV-HuBERT, a multi-modal self-supervised learning model, has been shown to be effective for categorical problems such as automatic speech recognition and lip-reading. This suggests that useful audio-visual speech representations can be obtained via utilizing multi-modal self-supervised embeddings. Nevertheless, it is unclear if such representations can be generalized to solve real-world multi-modal AV regression tasks, such as audio-visual speech enhancement (AVSE) and audio-visual speech separation (AVSS). In this study, we leveraged the pre-trained AV-HuBERT model followed by an SE module for AVSE and AVSS. Comparative experimental results demonstrate that our proposed model performs better than the state-of-the-art AVSE and traditional audio-only SE models. In summary, our results confirm the effectiveness of our proposed model for the AVSS task with proper fine-tuning strategies, demonstrating that multi-modal self-supervised embeddings obtained from AV-HUBERT can be generalized to audio-visual regression tasks.
Audio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks
Jan 24, 2018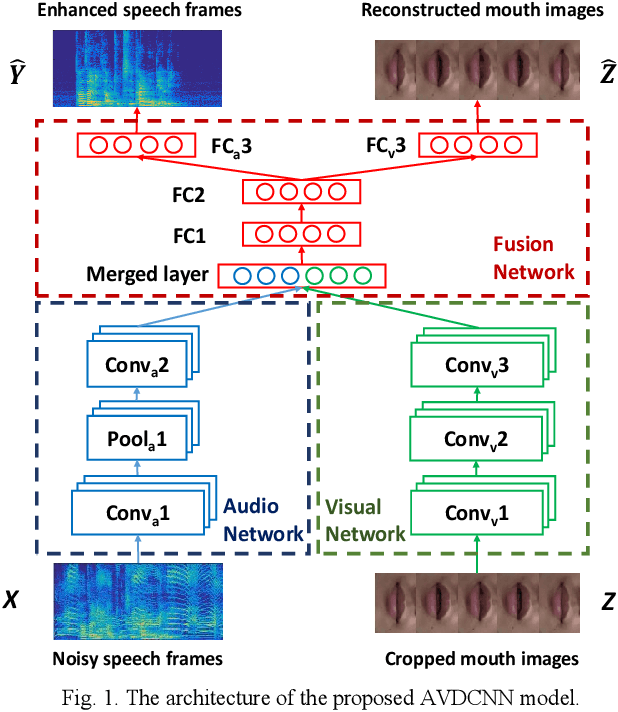
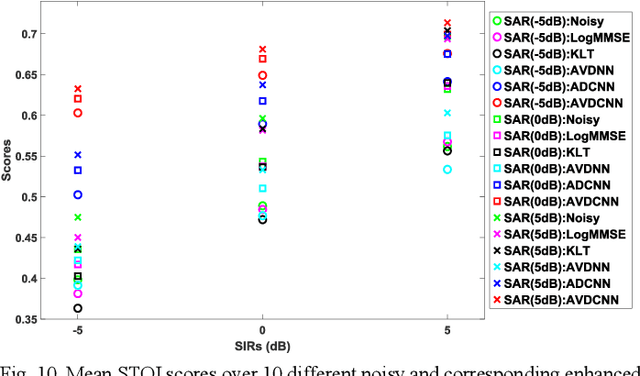
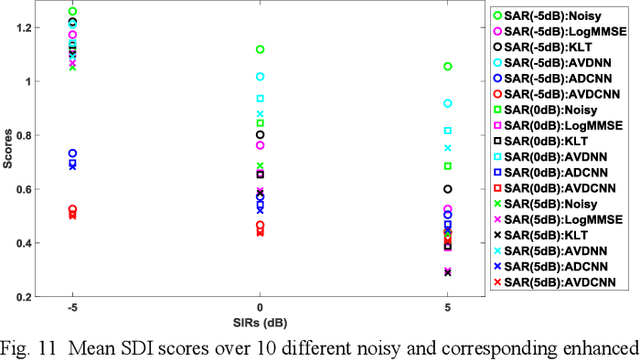
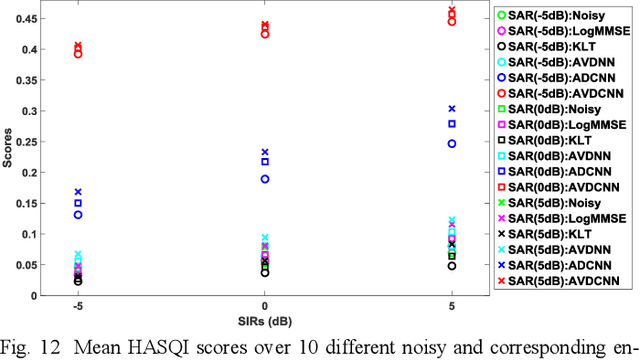
Speech enhancement (SE) aims to reduce noise in speech signals. Most SE techniques focus only on addressing audio information. In this work, inspired by multimodal learning, which utilizes data from different modalities, and the recent success of convolutional neural networks (CNNs) in SE, we propose an audio-visual deep CNNs (AVDCNN) SE model, which incorporates audio and visual streams into a unified network model. We also propose a multi-task learning framework for reconstructing audio and visual signals at the output layer. Precisely speaking, the proposed AVDCNN model is structured as an audio-visual encoder-decoder network, in which audio and visual data are first processed using individual CNNs, and then fused into a joint network to generate enhanced speech (the primary task) and reconstructed images (the secondary task) at the output layer. The model is trained in an end-to-end manner, and parameters are jointly learned through back-propagation. We evaluate enhanced speech using five instrumental criteria. Results show that the AVDCNN model yields a notably superior performance compared with an audio-only CNN-based SE model and two conventional SE approaches, confirming the effectiveness of integrating visual information into the SE process. In addition, the AVDCNN model also outperforms an existing audio-visual SE model, confirming its capability of effectively combining audio and visual information in SE.