 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCo: Reliable Causal Chain Reasoning via Structural Causal Recurrent Neural Networks
Dec 16, 2022Causal chain reasoning (CCR) is an essential ability for many decision-making AI systems, which requires the model to build reliable causal chains by connecting causal pairs. However, CCR suffers from two main transitive problems: threshold effect and scene drift. In other words, the causal pairs to be spliced may have a conflicting threshold boundary or scenario. To address these issues, we propose a novel Reliable Causal chain reasoning framework~(ReCo), which introduces exogenous variables to represent the threshold and scene factors of each causal pair within the causal chain, and estimates the threshold and scene contradictions across exogenous variables via structural causal recurrent neural networks~(SRNN). Experiments show that ReCo outperforms a series of strong baselines on both Chinese and English CCR datasets. Moreover, by injecting reliable causal chain knowledge distilled by ReCo, BERT can achieve better performances on four downstream causal-related tasks than BERT models enhanced by other kinds of knowledge.
Recognition and Prediction of Surgical Gestures and Trajectories Using Transformer Models in Robot-Assisted Surgery
Dec 03, 2022



Surgical activity recognition and prediction can help provide important context in many Robot-Assisted Surgery (RAS) applications, for example, surgical progress monitoring and estimation, surgical skill evaluation, and shared control strategies during teleoperation. Transformer models were first developed for Natural Language Processing (NLP) to model word sequences and soon the method gained popularity for general sequence modeling tasks. In this paper, we propose the novel use of a Transformer model for three tasks: gesture recognition, gesture prediction, and trajectory prediction during RAS. We modify the original Transformer architecture to be able to generate the current gesture sequence, future gesture sequence, and future trajectory sequence estimations using only the current kinematic data of the surgical robot end-effectors. We evaluate our proposed models on the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) and use Leave-One-User-Out (LOUO) cross-validation to ensure the generalizability of our results. Our models achieve up to 89.3\% gesture recognition accuracy, 84.6\% gesture prediction accuracy (1 second ahead) and 2.71mm trajectory prediction error (1 second ahead). Our models are comparable to and able to outperform state-of-the-art methods while using only the kinematic data channel. This approach can enable near-real time surgical activity recognition and prediction.
A Random Forest and Current Fault Texture Feature-Based Method for Current Sensor Fault Diagnosis in Three-Phase PWM VSR
Nov 08, 2022



Three-phase PWM voltage-source rectifier (VSR) systems have been widely used in various energy conversion systems, where current sensors are the key component for state monitoring and system control. The current sensor faults may bring hidden danger or damage to the whole system; therefore, this paper proposed a random forest (RF) and current fault texture feature-based method for current sensor fault diagnosis in three-phase PWM VSR systems. First, the three-phase alternating currents (ACs) of the three-phase PWM VSR are collected to extract the current fault texture features, and no additional hardware sensors are needed to avoid causing additional unstable factors. Then, the current fault texture features are adopted to train the random forest current sensor fault detection and diagnosis (CSFDD) classifier, which is a data-driven CSFDD classifier. Finally, the effectiveness of the proposed method is verified by simulation experiments. The result shows that the current sensor faults can be detected and located successfully and that it can effectively provide fault locations for maintenance personnel to keep the stable operation of the whole system.
A graph-transformer for whole slide image classification
May 19, 2022
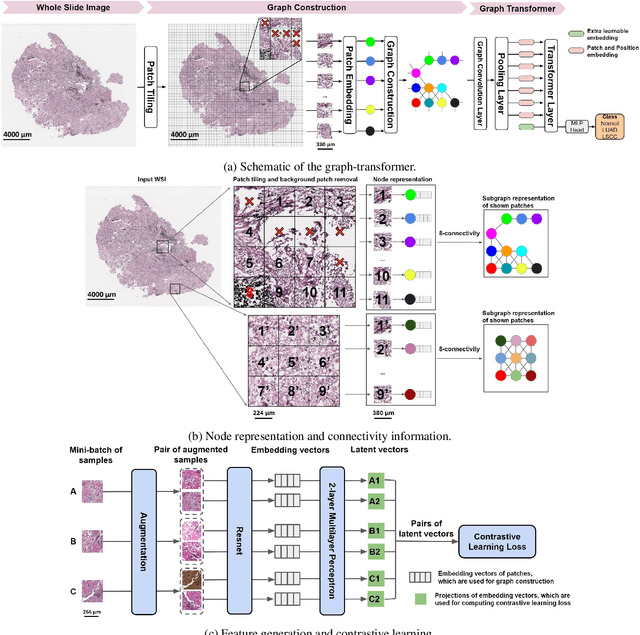
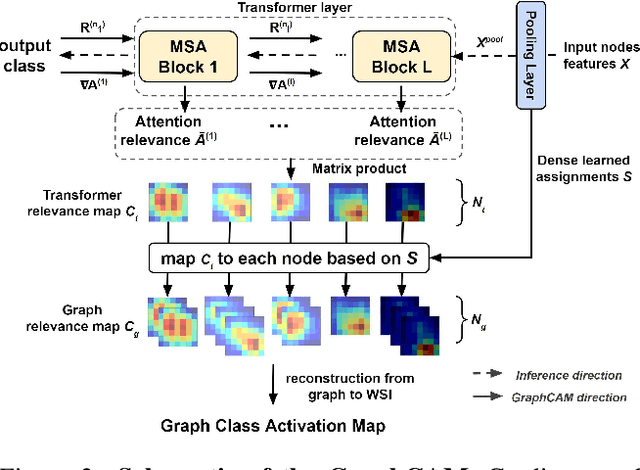
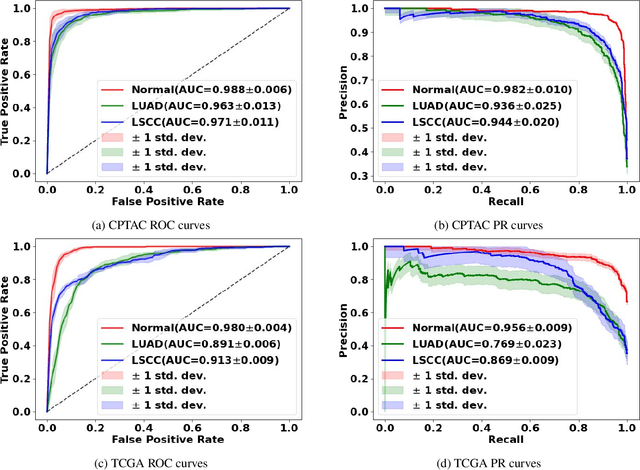
Deep learning is a powerful tool for whole slide image (WSI) analysis. Typically, when performing supervised deep learning, a WSI is divided into small patches, trained and the outcomes are aggregated to estimate disease grade. However, patch-based methods introduce label noise during training by assuming that each patch is independent with the same label as the WSI and neglect overall WSI-level information that is significant in disease grading. Here we present a Graph-Transformer (GT) that fuses a graph-based representation of an WSI and a vision transformer for processing pathology images, called GTP, to predict disease grade. We selected $4,818$ WSIs from the Clinical Proteomic Tumor Analysis Consortium (CPTAC), the National Lung Screening Trial (NLST), and The Cancer Genome Atlas (TCGA), and used GTP to distinguish adenocarcinoma (LUAD) and squamous cell carcinoma (LSCC) from adjacent non-cancerous tissue (normal). First, using NLST data, we developed a contrastive learning framework to generate a feature extractor. This allowed us to compute feature vectors of individual WSI patches, which were used to represent the nodes of the graph followed by construction of the GTP framework. Our model trained on the CPTAC data achieved consistently high performance on three-label classification (normal versus LUAD versus LSCC: mean accuracy$= 91.2$ $\pm$ $2.5\%$) based on five-fold cross-validation, and mean accuracy $= 82.3$ $\pm$ $1.0\%$ on external test data (TCGA). We also introduced a graph-based saliency mapping technique, called GraphCAM, that can identify regions that are highly associated with the class label. Our findings demonstrate GTP as an interpretable and effective deep learning framework for WSI-level classification.
Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition
Apr 18, 2022
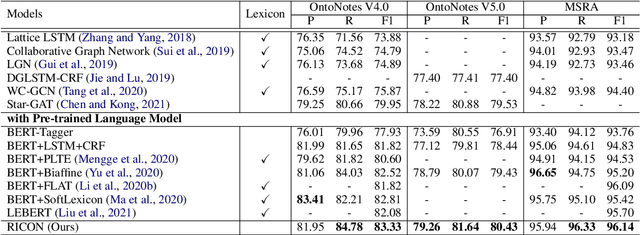
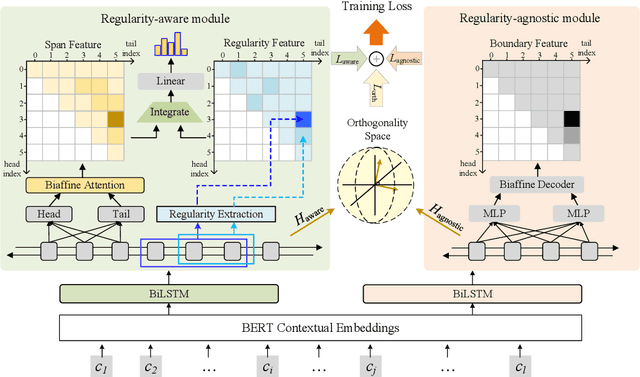
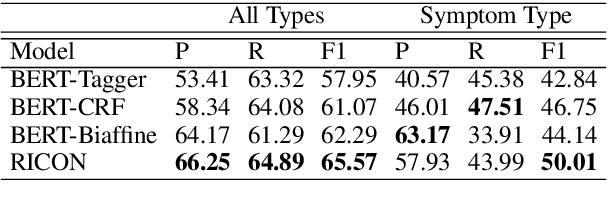
Recent years have witnessed the improving performance of Chinese Named Entity Recognition (NER) from proposing new frameworks or incorporating word lexicons. However, the inner composition of entity mentions in character-level Chinese NER has been rarely studied. Actually, most mentions of regular types have strong name regularity. For example, entities end with indicator words such as "company" or "bank" usually belong to organization. In this paper, we propose a simple but effective method for investigating the regularity of entity spans in Chinese NER, dubbed as Regularity-Inspired reCOgnition Network (RICON). Specifically, the proposed model consists of two branches: a regularity-aware module and a regularityagnostic module. The regularity-aware module captures the internal regularity of each span for better entity type prediction, while the regularity-agnostic module is employed to locate the boundary of entities and relieve the excessive attention to span regularity. An orthogonality space is further constructed to encourage two modules to extract different aspects of regularity features. To verify the effectiveness of our method, we conduct extensive experiments on three benchmark datasets and a practical medical dataset. The experimental results show that our RICON significantly outperforms previous state-of-the-art methods, including various lexicon-based methods.
Multi-Level Attention for Unsupervised Person Re-Identification
Jan 10, 2022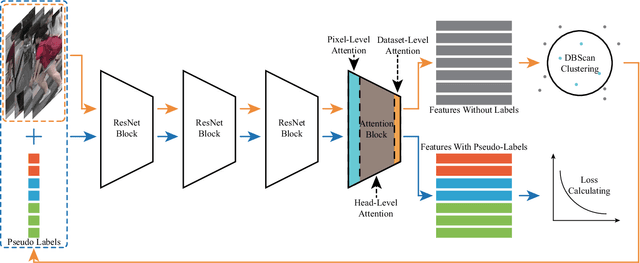

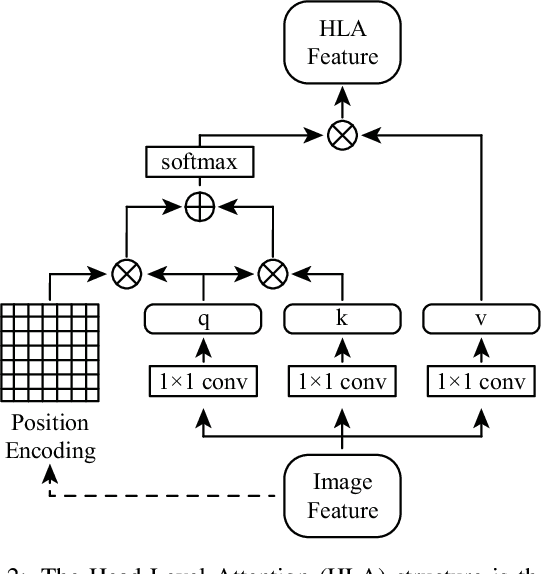
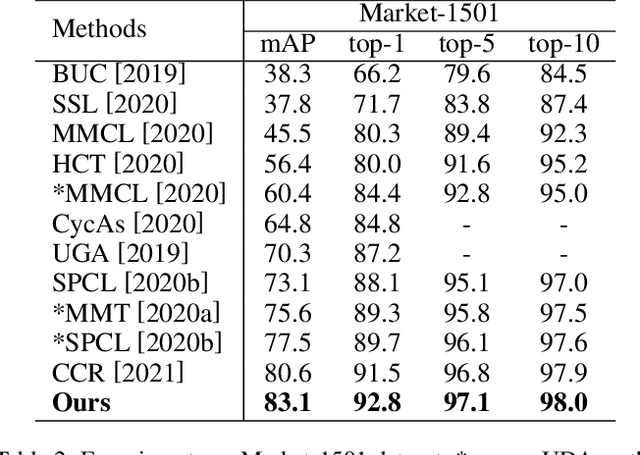
The attention mechanism is widely used in deep learning because of its excellent performance in neural networks without introducing additional information. However, in unsupervised person re-identification, the attention module represented by multi-headed self-attention suffers from attention spreading in the condition of non-ground truth. To solve this problem, we design pixel-level attention module to provide constraints for multi-headed self-attention. Meanwhile, for the trait that the identification targets of person re-identification data are all pedestrians in the samples, we design domain-level attention module to provide more comprehensive pedestrian features. We combine head-level, pixel-level and domain-level attention to propose multi-level attention block and validate its performance on for large person re-identification datasets (Market-1501, DukeMTMC-reID and MSMT17 and PersonX).
Implicit Neural Deformation for Multi-View Face Reconstruction
Dec 05, 2021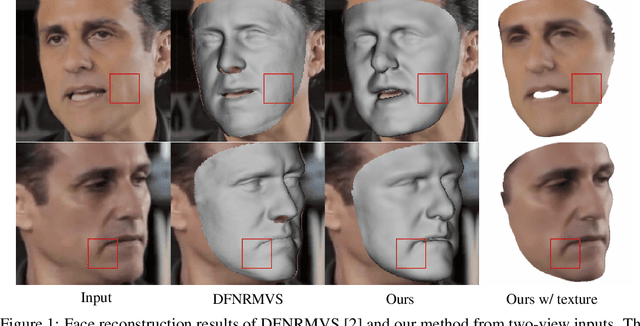
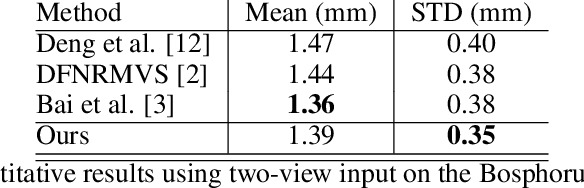

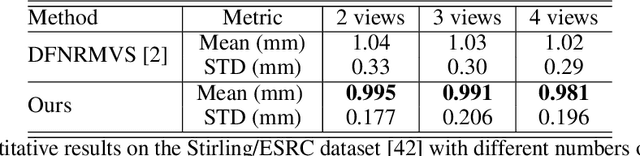
In this work, we present a new method for 3D face reconstruction from multi-view RGB images. Unlike previous methods which are built upon 3D morphable models (3DMMs) with limited details, our method leverages an implicit representation to encode rich geometric features. Our overall pipeline consists of two major components, including a geometry network, which learns a deformable neural signed distance function (SDF) as the 3D face representation, and a rendering network, which learns to render on-surface points of the neural SDF to match the input images via self-supervised optimization. To handle in-the-wild sparse-view input of the same target with different expressions at test time, we further propose residual latent code to effectively expand the shape space of the learned implicit face representation, as well as a novel view-switch loss to enforce consistency among different views. Our experimental results on several benchmark datasets demonstrate that our approach outperforms alternative baselines and achieves superior face reconstruction results compared to state-of-the-art methods.
Scene Synthesis via Uncertainty-Driven Attribute Synchronization
Sep 01, 2021
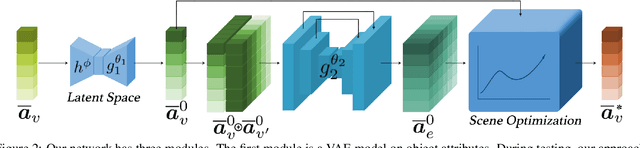


Developing deep neural networks to generate 3D scenes is a fundamental problem in neural synthesis with immediate applications in architectural CAD, computer graphics, as well as in generating virtual robot training environments. This task is challenging because 3D scenes exhibit diverse patterns, ranging from continuous ones, such as object sizes and the relative poses between pairs of shapes, to discrete patterns, such as occurrence and co-occurrence of objects with symmetrical relationships. This paper introduces a novel neural scene synthesis approach that can capture diverse feature patterns of 3D scenes. Our method combines the strength of both neural network-based and conventional scene synthesis approaches. We use the parametric prior distributions learned from training data, which provide uncertainties of object attributes and relative attributes, to regularize the outputs of feed-forward neural models. Moreover, instead of merely predicting a scene layout, our approach predicts an over-complete set of attributes. This methodology allows us to utilize the underlying consistency constraints among the predicted attributes to prune infeasible predictions. Experimental results show that our approach outperforms existing methods considerably. The generated 3D scenes interpolate the training data faithfully while preserving both continuous and discrete feature patterns.
A Game-Theoretic Taxonomy of Visual Concepts in DNNs
Jun 21, 2021
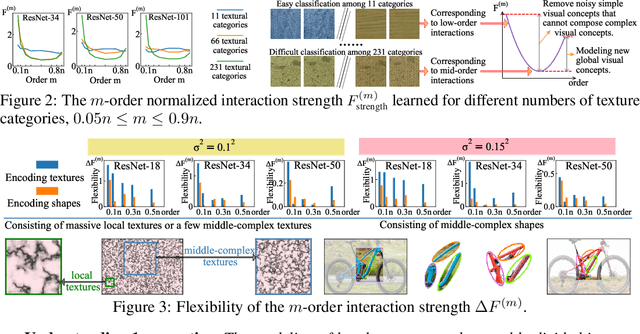
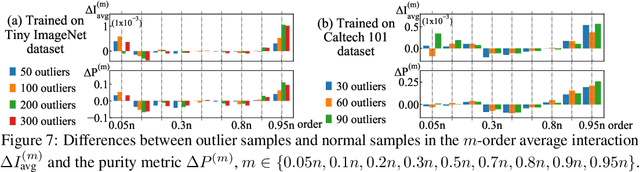
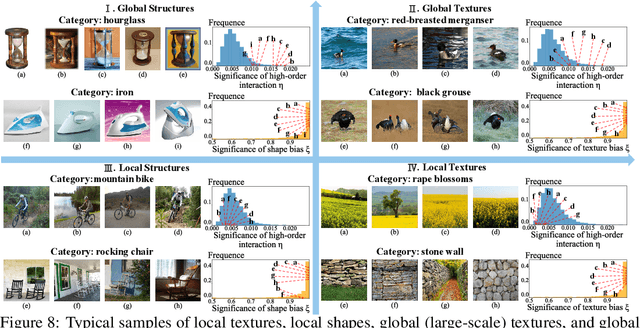
In this paper, we rethink how a DNN encodes visual concepts of different complexities from a new perspective, i.e. the game-theoretic multi-order interactions between pixels in an image. Beyond the categorical taxonomy of objects and the cognitive taxonomy of textures and shapes, we provide a new taxonomy of visual concepts, which helps us interpret the encoding of shapes and textures, in terms of concept complexities. In this way, based on multi-order interactions, we find three distinctive signal-processing behaviors of DNNs encoding textures. Besides, we also discover the flexibility for a DNN to encode shapes is lower than the flexibility of encoding textures. Furthermore, we analyze how DNNs encode outlier samples, and explore the impacts of network architectures on interactions. Additionally, we clarify the crucial role of the multi-order interactions in real-world applications. The code will be released when the paper is accepted.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021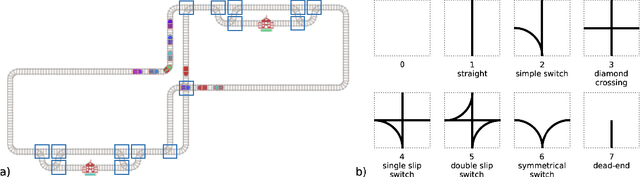
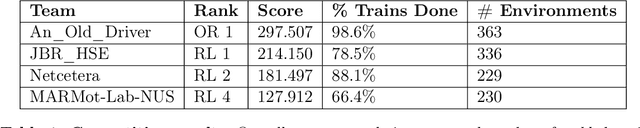
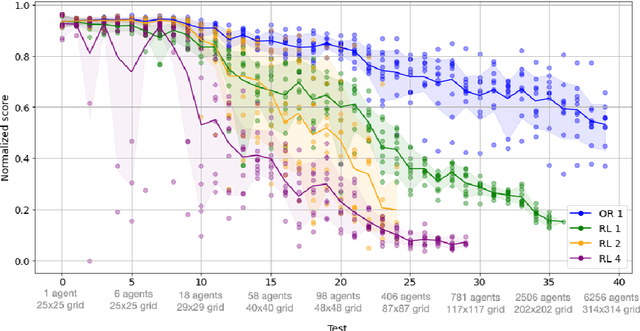
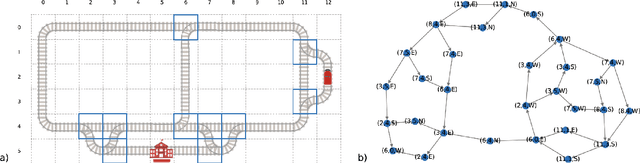
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.