 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarger language models do in-context learning differently
Mar 08, 2023



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Feb 14, 2023



We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at https://github.com/google-research/FLAN/tree/main/flan/v2.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
DSI++: Updating Transformer Memory with New Documents
Dec 19, 2022



Differentiable Search Indices (DSIs) encode a corpus of documents in the parameters of a model and use the same model to map queries directly to relevant document identifiers. Despite the strong performance of DSI models, deploying them in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model. In this work, we introduce DSI++, a continual learning challenge for DSI to incrementally index new documents while being able to answer queries related to both previously and newly indexed documents. Across different model scales and document identifier representations, we show that continual indexing of new documents leads to considerable forgetting of previously indexed documents. We also hypothesize and verify that the model experiences forgetting events during training, leading to unstable learning. To mitigate these issues, we investigate two approaches. The first focuses on modifying the training dynamics. Flatter minima implicitly alleviate forgetting, so we optimize for flatter loss basins and show that the model stably memorizes more documents (+12\%). Next, we introduce a generative memory to sample pseudo-queries for documents and supplement them during continual indexing to prevent forgetting for the retrieval task. Extensive experiments on novel continual indexing benchmarks based on Natural Questions (NQ) and MS MARCO demonstrate that our proposed solution mitigates forgetting by a significant margin. Concretely, it improves the average Hits@10 by $+21.1\%$ over competitive baselines for NQ and requires $6$ times fewer model updates compared to re-training the DSI model for incrementally indexing five corpora in a sequence.
Dense Feature Memory Augmented Transformers for COVID-19 Vaccination Search Classification
Dec 16, 2022



With the devastating outbreak of COVID-19, vaccines are one of the crucial lines of defense against mass infection in this global pandemic. Given the protection they provide, vaccines are becoming mandatory in certain social and professional settings. This paper presents a classification model for detecting COVID-19 vaccination related search queries, a machine learning model that is used to generate search insights for COVID-19 vaccinations. The proposed method combines and leverages advancements from modern state-of-the-art (SOTA) natural language understanding (NLU) techniques such as pretrained Transformers with traditional dense features. We propose a novel approach of considering dense features as memory tokens that the model can attend to. We show that this new modeling approach enables a significant improvement to the Vaccine Search Insights (VSI) task, improving a strong well-established gradient-boosting baseline by relative +15% improvement in F1 score and +14% in precision.
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
Dec 09, 2022



Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
Inverse scaling can become U-shaped
Nov 14, 2022Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 (McKensie et al., 2022) identified four "inverse scaling" tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute. This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, two out of the four tasks exhibit what we call "U-shaped scaling" -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a "true task" and a "distractor task". Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models. Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022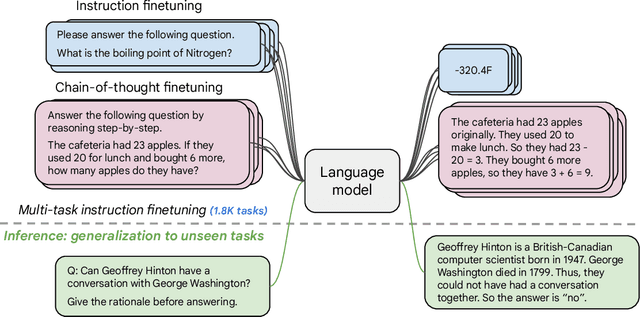

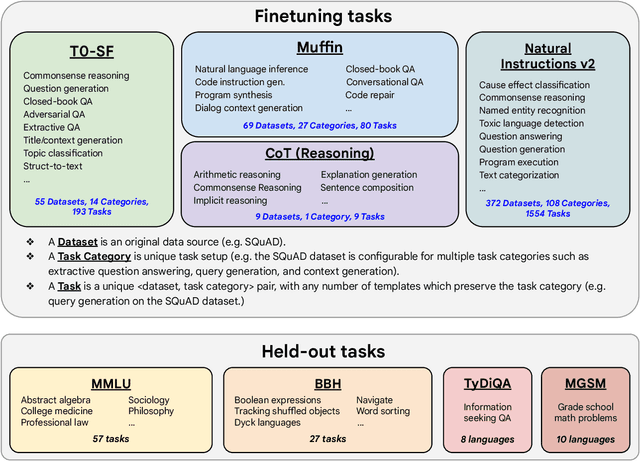

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022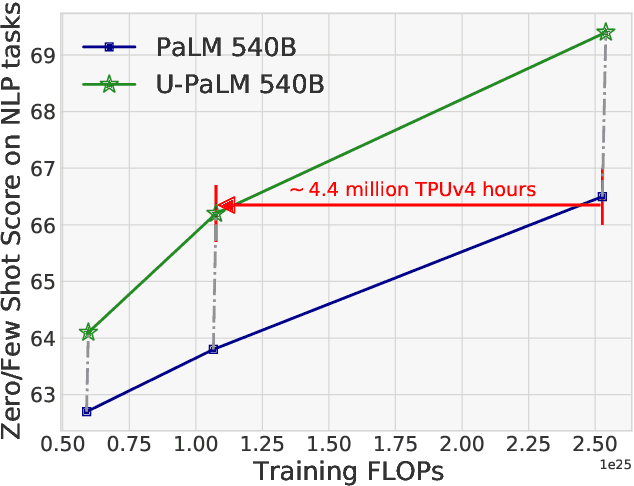
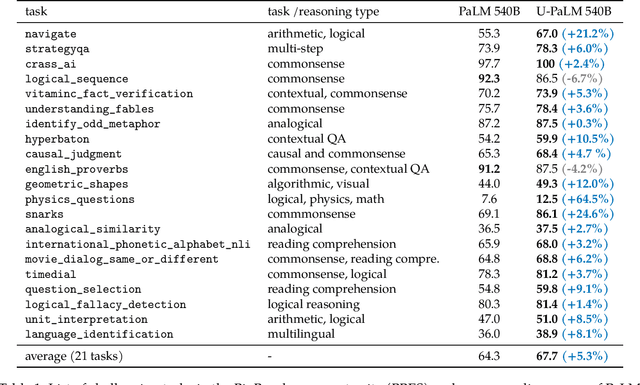
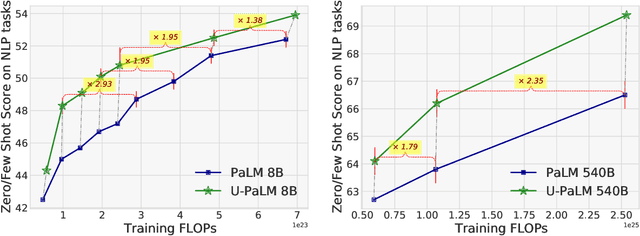
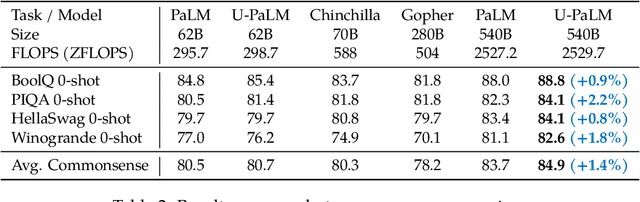
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Oct 17, 2022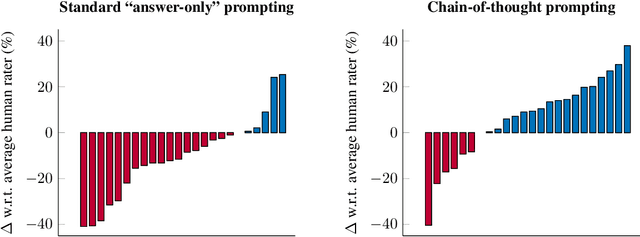

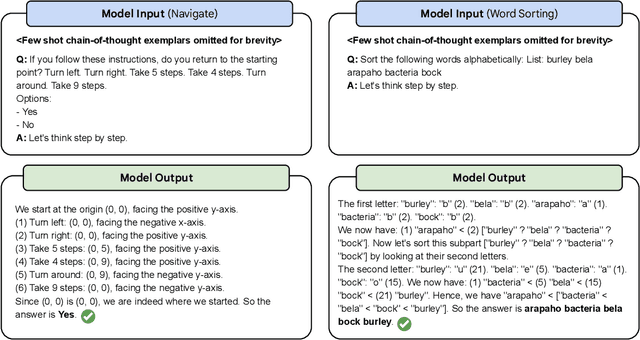
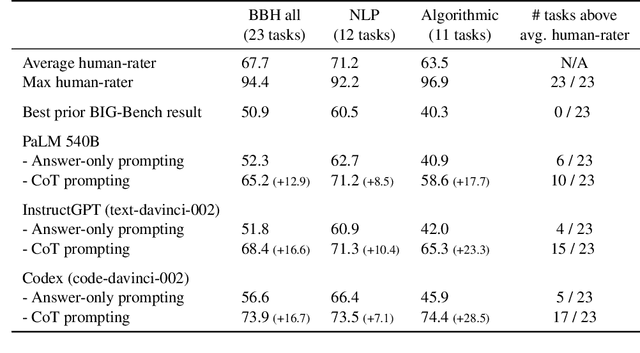
BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.