 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe're Afraid Language Models Aren't Modeling Ambiguity
Apr 27, 2023Ambiguity is an intrinsic feature of natural language. Managing ambiguity is a key part of human language understanding, allowing us to anticipate misunderstanding as communicators and revise our interpretations as listeners. As language models (LMs) are increasingly employed as dialogue interfaces and writing aids, handling ambiguous language is critical to their success. We characterize ambiguity in a sentence by its effect on entailment relations with another sentence, and collect AmbiEnt, a linguist-annotated benchmark of 1,645 examples with diverse kinds of ambiguity. We design a suite of tests based on AmbiEnt, presenting the first evaluation of pretrained LMs to recognize ambiguity and disentangle possible meanings. We find that the task remains extremely challenging, including for the recent GPT-4, whose generated disambiguations are considered correct only 32% of the time in human evaluation, compared to 90% for disambiguations in our dataset. Finally, to illustrate the value of ambiguity-sensitive tools, we show that a multilabel NLI model can flag political claims in the wild that are misleading due to ambiguity. We encourage the field to rediscover the importance of ambiguity for NLP.
Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved With Text
Apr 14, 2023In-context vision and language models like Flamingo support arbitrarily interleaved sequences of images and text as input. This format not only enables few-shot learning via interleaving independent supervised (image, text) examples, but also, more complex prompts involving interaction between images, e.g., "What do image A and image B have in common?" To support this interface, pretraining occurs over web corpora that similarly contain interleaved images+text. To date, however, large-scale data of this form have not been publicly available. We release Multimodal C4 (mmc4), an augmentation of the popular text-only c4 corpus with images interleaved. We use a linear assignment algorithm to place images into longer bodies of text using CLIP features, a process that we show outperforms alternatives. mmc4 spans everyday topics like cooking, travel, technology, etc. A manual inspection of a random sample of documents shows that a vast majority (90%) of images are topically relevant, and that linear assignment frequently selects individual sentences specifically well-aligned with each image (78%). After filtering NSFW images, ads, etc., the corpus contains 103M documents containing 585M images interleaved with 43B English tokens.
CHAMPAGNE: Learning Real-world Conversation from Large-Scale Web Videos
Mar 17, 2023Visual information is central to conversation: body gestures and facial expressions, for example, contribute to meaning that transcends words alone. To date, however, most neural conversational models are limited to just text. We introduce CHAMPAGNE, a generative model of conversations that can account for visual contexts. To train CHAMPAGNE, we collect and release YTD-18M, a large-scale corpus of 18M video-based dialogues. YTD-18M is constructed from web videos: crucial to our data collection pipeline is a pretrained language model that converts error-prone automatic transcripts to a cleaner dialogue format while maintaining meaning. Human evaluation reveals that YTD-18M is more sensible and specific than prior resources (MMDialog, 1M dialogues), while maintaining visual-groundedness. Experiments demonstrate that 1) CHAMPAGNE learns to conduct conversation from YTD-18M; and 2) when fine-tuned, it achieves state-of-the-art results on four vision-language tasks focused on real-world conversations. We release data, models, and code at https://seungjuhan.me/champagne.
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Jan 28, 2023Reinforcement learning (RL) agents typically learn tabula rasa, without prior knowledge of the world, which makes learning complex tasks with sparse rewards difficult. If initialized with knowledge of high-level subgoals and transitions between subgoals, RL agents could utilize this Abstract World Model (AWM) for planning and exploration. We propose using few-shot large language models (LLMs) to hypothesize an AWM, that is tested and verified during exploration, to improve sample efficiency in embodied RL agents. Our DECKARD agent applies LLM-guided exploration to item crafting in Minecraft in two phases: (1) the Dream phase where the agent uses an LLM to decompose a task into a sequence of subgoals, the hypothesized AWM; and (2) the Wake phase where the agent learns a modular policy for each subgoal and verifies or corrects the hypothesized AWM on the basis of its experiences. Our method of hypothesizing an AWM with LLMs and then verifying the AWM based on agent experience not only increases sample efficiency over contemporary methods by an order of magnitude but is also robust to and corrects errors in the LLM, successfully blending noisy internet-scale information from LLMs with knowledge grounded in environment dynamics.
MAUVE Scores for Generative Models: Theory and Practice
Dec 30, 2022
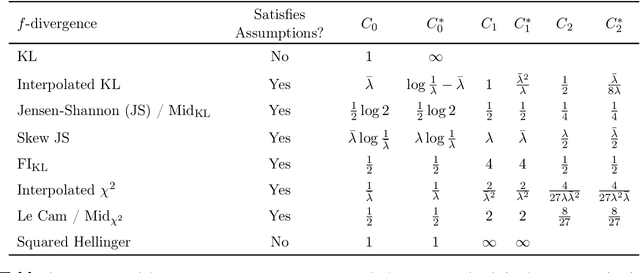
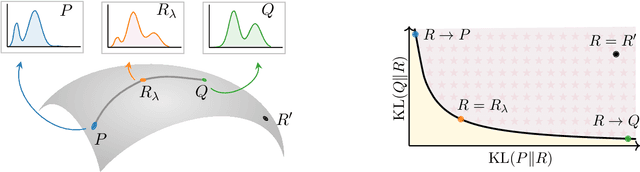

Generative AI has matured to a point where large-scale models can generate text that seems indistinguishable from human-written text and remarkably photorealistic images. Automatically measuring how close the distribution of generated data is to the target real data distribution is a key step in diagnosing existing models and developing better models. We present MAUVE, a family of comparison measures between pairs of distributions such as those encountered in the generative modeling of text or images. These scores are statistical summaries of divergence frontiers capturing two types of errors in generative modeling. We explore four approaches to statistically estimate these scores: vector quantization, non-parametric estimation, classifier-based estimation, and parametric Gaussian approximations. We provide statistical bounds for the vector quantization approach. Empirically, we find that the proposed scores paired with a range of $f$-divergences and statistical estimation methods can quantify the gaps between the distributions of human-written text and those of modern neural language models by correlating with human judgments and identifying known properties of the generated texts. We conclude the paper by demonstrating its applications to other AI domains and discussing practical recommendations.
Detoxifying Text with MaRCo: Controllable Revision with Experts and Anti-Experts
Dec 20, 2022



Text detoxification has the potential to mitigate the harms of toxicity by rephrasing text to remove offensive meaning, but subtle toxicity remains challenging to tackle. We introduce MaRCo, a detoxification algorithm that combines controllable generation and text rewriting methods using a Product of Experts with autoencoder language models (LMs). MaRCo uses likelihoods under a non-toxic LM (expert) and a toxic LM (anti-expert) to find candidate words to mask and potentially replace. We evaluate our method on several subtle toxicity and microaggressions datasets, and show that it not only outperforms baselines on automatic metrics, but MaRCo's rewrites are preferred 2.1 $\times$ more in human evaluation. Its applicability to instances of subtle toxicity is especially promising, demonstrating a path forward for addressing increasingly elusive online hate.
SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
Dec 20, 2022



We present SODA: the first publicly available, million-scale high-quality social dialogue dataset. Using SODA, we train COSMO: a generalizable conversation agent outperforming previous best-performing agents on both in- and out-of-domain datasets. In contrast to most existing crowdsourced, small-scale dialogue corpora, we distill 1.5M socially-grounded dialogues from a pre-trained language model (InstructGPT; Ouyang et al., 2022). Dialogues are distilled by contextualizing social commonsense knowledge from a knowledge graph (Atomic10x; West et al., 2022). Human evaluation shows that dialogues in SODA are more consistent, specific, and (surprisingly) natural than prior human-authored datasets - e.g., DailyDialog (Li et al., 2017), BlendedSkillTalk (Smith et al., 2020). In addition, extensive evaluations show that COSMO is significantly more natural and consistent on unseen datasets than best-performing dialogue models - e.g., GODEL (Peng et al., 2022), BlenderBot (Roller et al., 2021), DialoGPT (Zhang et al., 2020). Furthermore, it is sometimes even preferred to the original human-written gold responses. We make our data, models, and code public.
Reinforced Clarification Question Generation with Defeasibility Rewards for Disambiguating Social and Moral Situations
Dec 20, 2022



Context is vital for commonsense moral reasoning. "Lying to a friend" is wrong if it is meant to deceive them, but may be morally okay if it is intended to protect them. Such nuanced but salient contextual information can potentially flip the moral judgment of an action. Thus, we present ClarifyDelphi, an interactive system that elicits missing contexts of a moral situation by generating clarification questions such as "Why did you lie to your friend?". Our approach is inspired by the observation that questions whose potential answers lead to diverging moral judgments are the most informative. We learn to generate questions using Reinforcement Learning, by maximizing the divergence between moral judgements of hypothetical answers to a question. Human evaluation shows that our system generates more relevant, informative and defeasible questions compared to other question generation baselines. ClarifyDelphi assists informed moral reasoning processes by seeking additional morally consequential context to disambiguate social and moral situations.
An AI Dungeon Master's Guide: Learning to Converse and Guide with Intents and Theory-of-Mind in Dungeons and Dragons
Dec 20, 2022We propose a novel task, G4C (Goal-driven Guidance Generation in Grounded Communication), for studying goal-driven and grounded natural language interactions. Specifically, we choose Dungeons and Dragons (D&D) -- a role-playing game consisting of multiple player characters and a Dungeon Master (DM) who collaborate to achieve a set of goals that are beneficial to the players -- as a testbed for this task. Here, each of the player characters is a student, with their own personas and abilities, and the DM is the teacher, an arbitrator of the rules of the world and responsible for assisting and guiding the students towards a global goal. We propose a theory-of-mind-inspired methodology for training such a DM with reinforcement learning (RL), where a DM: (1) learns to predict how the players will react to its utterances using a dataset of D&D dialogue transcripts; and (2) uses this prediction as a reward function providing feedback on how effective these utterances are at guiding the players towards a goal. Human and automated evaluations show that a DM trained with RL to generate guidance by incorporating a theory-of-mind of the players significantly improves the players' ability to achieve goals grounded in their shared world.
I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
Dec 19, 2022


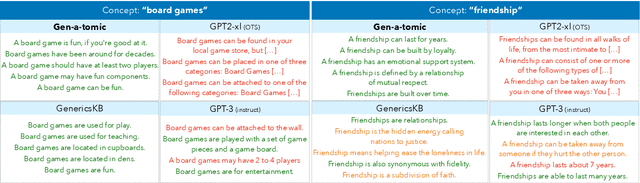
Pre-trained language models, despite their rapid advancements powered by scale, still fall short of robust commonsense capabilities. And yet, scale appears to be the winning recipe; after all, the largest models seem to have acquired the largest amount of commonsense capabilities. Or is it? In this paper, we investigate the possibility of a seemingly impossible match: can smaller language models with dismal commonsense capabilities (i.e., GPT-2), ever win over models that are orders of magnitude larger and better (i.e., GPT-3), if the smaller models are powered with novel commonsense distillation algorithms? The key intellectual question we ask here is whether it is possible, if at all, to design a learning algorithm that does not benefit from scale, yet leads to a competitive level of commonsense acquisition. In this work, we study the generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly. We introduce a novel commonsense distillation framework, I2D2, that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale models as the teacher model by two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-Tomic, that is of the largest and highest quality available to date.