 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Constrained Decoding with Token Space Compression
May 28, 2026To guarantee that an LLM's outputs conform to a specified structure, context-free grammar (CFG) decoding engines force the selection of next tokens that produce strings that conform to a given CFG. While current CFG-constrained decoding engines are highly optimized, the inherent costs arising from the massive per-step search space -- i.e. the entire token vocabulary -- result in intractably high overhead for more complex CFGs: precisely the situation where CFG engines are most useful. In this paper, we introduce CFGzip, an offline technique for compressing the token search space, which massively reduces CFG engine overhead. In experiments, we report latency reduction of up to two orders of magnitude when CFGzip is used with a SoTA grammar engine, yielding an up to 7.5x speedup in total constrained generation time: with CFGzip, constrained decoding is now feasible at scale for complex CFGs.
Barriers to Universal Reasoning With Transformers (And How to Overcome Them)
Apr 28, 2026Chain-of-Thought (CoT) has been shown to empirically improve Transformers' performance, and theoretically increase their expressivity to Turing completeness. However, whether Transformers can learn to generalize to CoT traces longer than those seen during training is understudied. We use recent theoretical frameworks for Transformer length generalization and find that -- under standard positional encodings and a finite alphabet -- Transformers with CoT cannot solve problems beyond $TC^0$, i.e. the expressivity benefits do not hold under the stricter requirement of length-generalizable learnability. However, if we allow the vocabulary to grow with problem size, we attain a length-generalizable simulation of Turing machines where the CoT trace length is linear in the simulated runtime up to a constant. Our construction overcomes two core obstacles to reliable length generalization: repeated copying and last-occurrence retrieval. We assign each tape position a unique signpost token, and log only value changes to enable recovery of the current tape symbol through counts circumventing both barriers. Further, we empirically show that the use of such signpost tokens and value change encodings provide actionable guidance to improve length generalization on hard problems.
AuthorMix: Modular Authorship Style Transfer via Layer-wise Adapter Mixing
Mar 24, 2026The task of authorship style transfer involves rewriting text in the style of a target author while preserving the meaning of the original text. Existing style transfer methods train a single model on large corpora to model all target styles at once: this high-cost approach offers limited flexibility for target-specific adaptation, and often sacrifices meaning preservation for style transfer. In this paper, we propose AuthorMix: a lightweight, modular, and interpretable style transfer framework. We train individual, style-specific LoRA adapters on a small set of high-resource authors, allowing the rapid training of specialized adaptation models for each new target via learned, layer-wise adapter mixing, using only a handful of target style training examples. AuthorMix outperforms existing, SoTA style-transfer baselines -- as well as GPT-5.1 -- for low-resource targets, achieving the highest overall score and substantially improving meaning preservation.
On the Ability of Transformers to Verify Plans
Mar 20, 2026Transformers have shown inconsistent success in AI planning tasks, and theoretical understanding of when generalization should be expected has been limited. We take important steps towards addressing this gap by analyzing the ability of decoder-only models to verify whether a given plan correctly solves a given planning instance. To analyse the general setting where the number of objects -- and thus the effective input alphabet -- grows at test time, we introduce C*-RASP, an extension of C-RASP designed to establish length generalization guarantees for transformers under the simultaneous growth in sequence length and vocabulary size. Our results identify a large class of classical planning domains for which transformers can provably learn to verify long plans, and structural properties that significantly affects the learnability of length generalizable solutions. Empirical experiments corroborate our theory.
Positional Biases Shift as Inputs Approach Context Window Limits
Aug 10, 2025


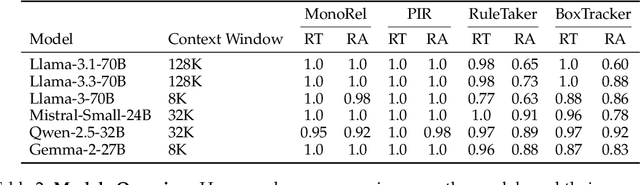
Large Language Models (LLMs) often struggle to use information across long inputs effectively. Prior work has identified positional biases, such as the Lost in the Middle (LiM) effect, where models perform better when information appears at the beginning (primacy bias) or end (recency bias) of the input, rather than in the middle. However, long-context studies have not consistently replicated these effects, raising questions about their intensity and the conditions under which they manifest. To address this, we conducted a comprehensive analysis using relative rather than absolute input lengths, defined with respect to each model's context window. Our findings reveal that the LiM effect is strongest when inputs occupy up to 50% of a model's context window. Beyond that, the primacy bias weakens, while recency bias remains relatively stable. This effectively eliminates the LiM effect; instead, we observe a distance-based bias, where model performance is better when relevant information is closer to the end of the input. Furthermore, our results suggest that successful retrieval is a prerequisite for reasoning in LLMs, and that the observed positional biases in reasoning are largely inherited from retrieval. These insights have implications for long-context tasks, the design of future LLM benchmarks, and evaluation methodologies for LLMs handling extended inputs.
Language models can learn implicit multi-hop reasoning, but only if they have lots of training data
May 23, 2025



Implicit reasoning is the ability of a language model to solve multi-hop reasoning tasks in a single forward pass, without chain of thought. We investigate this capability using GPT2-style language models trained from scratch on controlled $k$-hop reasoning datasets ($k = 2, 3, 4$). We show that while such models can indeed learn implicit $k$-hop reasoning, the required training data grows exponentially in $k$, and the required number of transformer layers grows linearly in $k$. We offer a theoretical explanation for why this depth growth is necessary. We further find that the data requirement can be mitigated, but not eliminated, through curriculum learning.
Collaborative Problem-Solving in an Optimization Game
May 21, 2025



Dialogue agents that support human users in solving complex tasks have received much attention recently. Many such tasks are NP-hard optimization problems that require careful collaborative exploration of the solution space. We introduce a novel dialogue game in which the agents collaboratively solve a two-player Traveling Salesman problem, along with an agent that combines LLM prompting with symbolic mechanisms for state tracking and grounding. Our best agent solves 45% of games optimally in self-play. It also demonstrates an ability to collaborate successfully with human users and generalize to unfamiliar graphs.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025



Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
LLMs syntactically adapt their language use to their conversational partner
Mar 10, 2025



It has been frequently observed that human speakers align their language use with each other during conversations. In this paper, we study empirically whether large language models (LLMs) exhibit the same behavior of conversational adaptation. We construct a corpus of conversations between LLMs and find that two LLM agents end up making more similar syntactic choices as conversations go on, confirming that modern LLMs adapt their language use to their conversational partners in at least a rudimentary way.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025



We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.