 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamiltonian Descent Methods
Sep 13, 2018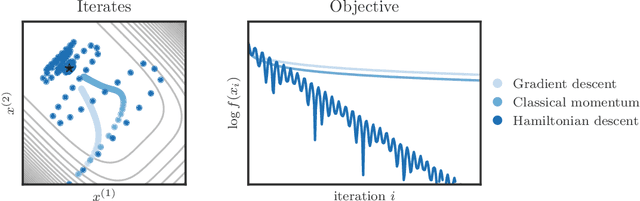

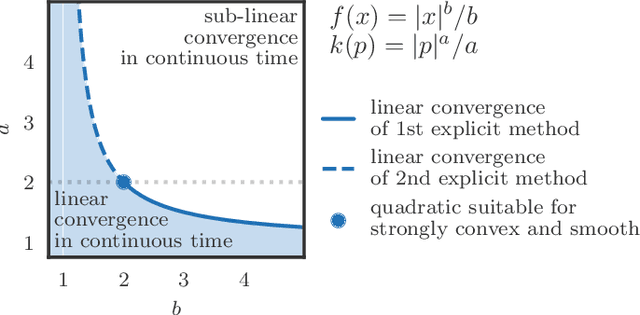
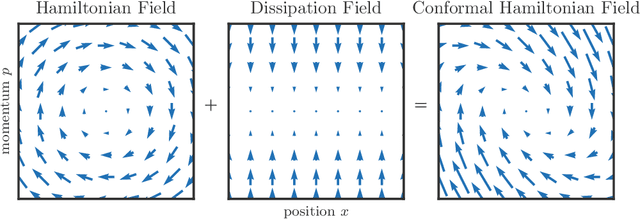
We propose a family of optimization methods that achieve linear convergence using first-order gradient information and constant step sizes on a class of convex functions much larger than the smooth and strongly convex ones. This larger class includes functions whose second derivatives may be singular or unbounded at their minima. Our methods are discretizations of conformal Hamiltonian dynamics, which generalize the classical momentum method to model the motion of a particle with non-standard kinetic energy exposed to a dissipative force and the gradient field of the function of interest. They are first-order in the sense that they require only gradient computation. Yet, crucially the kinetic gradient map can be designed to incorporate information about the convex conjugate in a fashion that allows for linear convergence on convex functions that may be non-smooth or non-strongly convex. We study in detail one implicit and two explicit methods. For one explicit method, we provide conditions under which it converges to stationary points of non-convex functions. For all, we provide conditions on the convex function and kinetic energy pair that guarantee linear convergence, and show that these conditions can be satisfied by functions with power growth. In sum, these methods expand the class of convex functions on which linear convergence is possible with first-order computation.
Sampling and Inference for Beta Neutral-to-the-Left Models of Sparse Networks
Jul 09, 2018
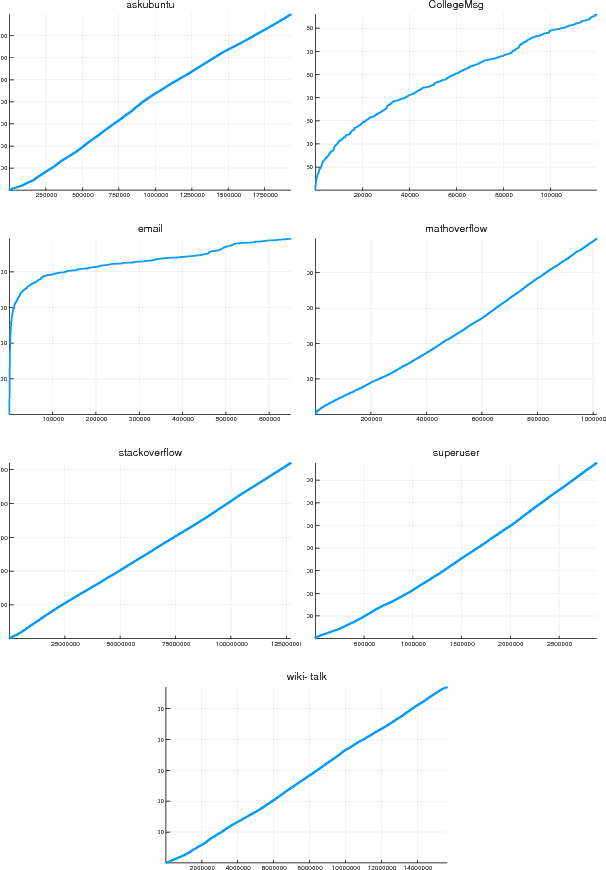


Empirical evidence suggests that heavy-tailed degree distributions occurring in many real networks are well-approximated by power laws with exponents $\eta$ that may take values either less than and greater than two. Models based on various forms of exchangeability are able to capture power laws with $\eta < 2$, and admit tractable inference algorithms; we draw on previous results to show that $\eta > 2$ cannot be generated by the forms of exchangeability used in existing random graph models. Preferential attachment models generate power law exponents greater than two, but have been of limited use as statistical models due to the inherent difficulty of performing inference in non-exchangeable models. Motivated by this gap, we design and implement inference algorithms for a recently proposed class of models that generates $\eta$ of all possible values. We show that although they are not exchangeable, these models have probabilistic structure amenable to inference. Our methods make a large class of previously intractable models useful for statistical inference.
Neural Processes
Jul 04, 2018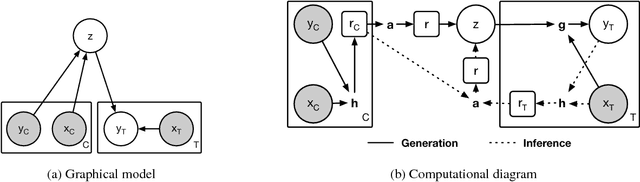

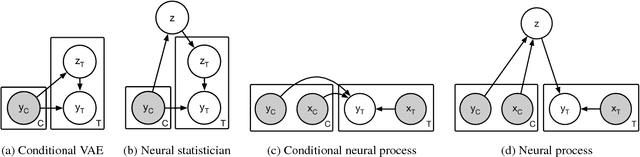
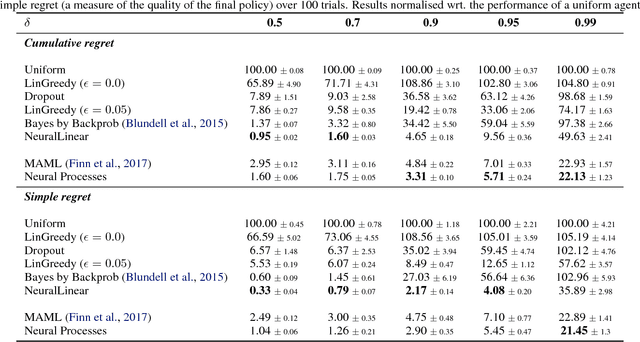
A neural network (NN) is a parameterised function that can be tuned via gradient descent to approximate a labelled collection of data with high precision. A Gaussian process (GP), on the other hand, is a probabilistic model that defines a distribution over possible functions, and is updated in light of data via the rules of probabilistic inference. GPs are probabilistic, data-efficient and flexible, however they are also computationally intensive and thus limited in their applicability. We introduce a class of neural latent variable models which we call Neural Processes (NPs), combining the best of both worlds. Like GPs, NPs define distributions over functions, are capable of rapid adaptation to new observations, and can estimate the uncertainty in their predictions. Like NNs, NPs are computationally efficient during training and evaluation but also learn to adapt their priors to data. We demonstrate the performance of NPs on a range of learning tasks, including regression and optimisation, and compare and contrast with related models in the literature.
Conditional Neural Processes
Jul 04, 2018



Deep neural networks excel at function approximation, yet they are typically trained from scratch for each new function. On the other hand, Bayesian methods, such as Gaussian Processes (GPs), exploit prior knowledge to quickly infer the shape of a new function at test time. Yet GPs are computationally expensive, and it can be hard to design appropriate priors. In this paper we propose a family of neural models, Conditional Neural Processes (CNPs), that combine the benefits of both. CNPs are inspired by the flexibility of stochastic processes such as GPs, but are structured as neural networks and trained via gradient descent. CNPs make accurate predictions after observing only a handful of training data points, yet scale to complex functions and large datasets. We demonstrate the performance and versatility of the approach on a range of canonical machine learning tasks, including regression, classification and image completion.
Progress & Compress: A scalable framework for continual learning
Jul 02, 2018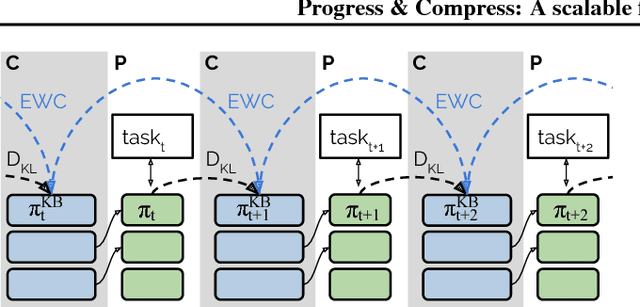
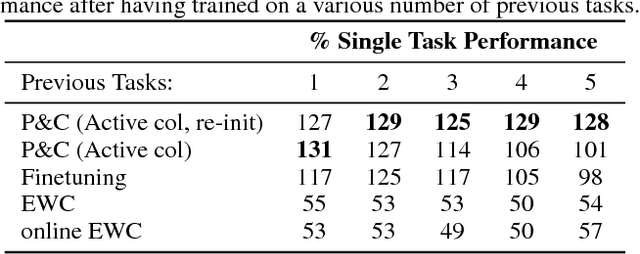
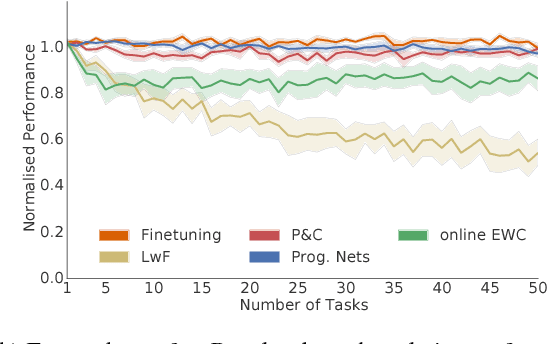
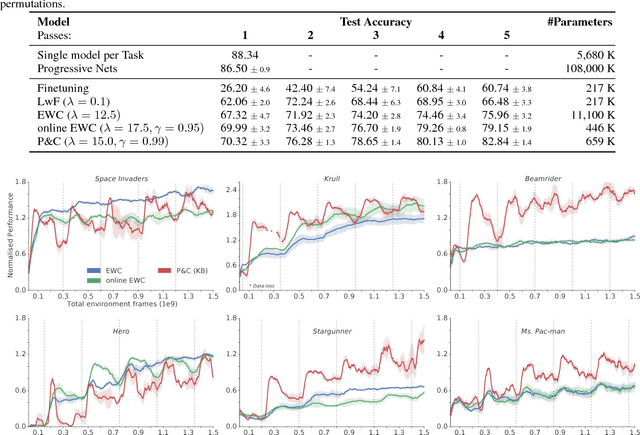
We introduce a conceptually simple and scalable framework for continual learning domains where tasks are learned sequentially. Our method is constant in the number of parameters and is designed to preserve performance on previously encountered tasks while accelerating learning progress on subsequent problems. This is achieved by training a network with two components: A knowledge base, capable of solving previously encountered problems, which is connected to an active column that is employed to efficiently learn the current task. After learning a new task, the active column is distilled into the knowledge base, taking care to protect any previously acquired skills. This cycle of active learning (progression) followed by consolidation (compression) requires no architecture growth, no access to or storing of previous data or tasks, and no task-specific parameters. We demonstrate the progress & compress approach on sequential classification of handwritten alphabets as well as two reinforcement learning domains: Atari games and 3D maze navigation.
Tighter Variational Bounds are Not Necessarily Better
Jun 25, 2018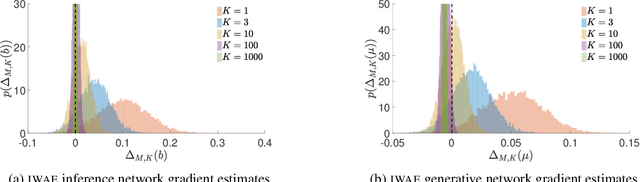

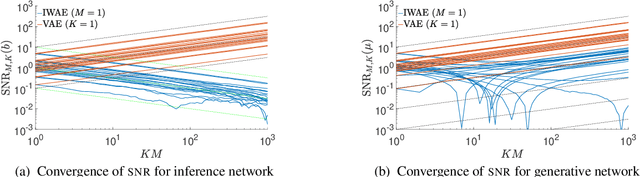
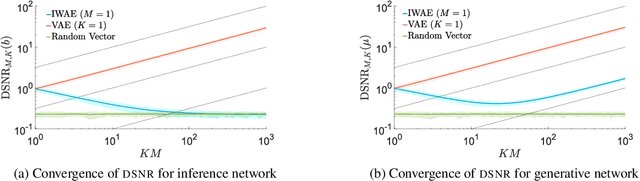
We provide theoretical and empirical evidence that using tighter evidence lower bounds (ELBOs) can be detrimental to the process of learning an inference network by reducing the signal-to-noise ratio of the gradient estimator. Our results call into question common implicit assumptions that tighter ELBOs are better variational objectives for simultaneous model learning and inference amortization schemes. Based on our insights, we introduce three new algorithms: the partially importance weighted auto-encoder (PIWAE), the multiply importance weighted auto-encoder (MIWAE), and the combination importance weighted auto-encoder (CIWAE), each of which includes the standard importance weighted auto-encoder (IWAE) as a special case. We show that each can deliver improvements over IWAE, even when performance is measured by the IWAE target itself. Furthermore, our results suggest that PIWAE may be able to deliver simultaneous improvements in the training of both the inference and generative networks.
Inference Trees: Adaptive Inference with Exploration
Jun 25, 2018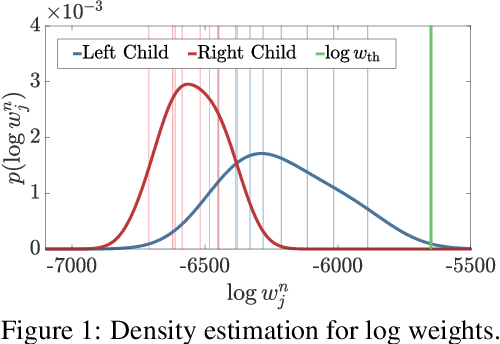
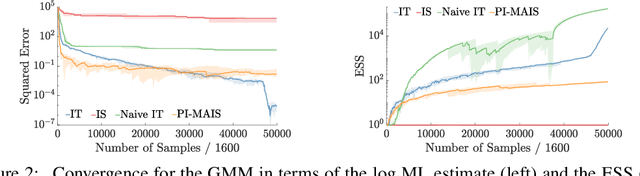
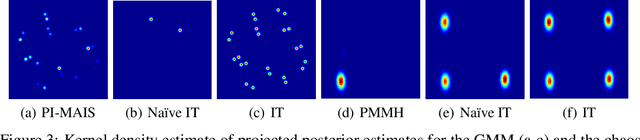
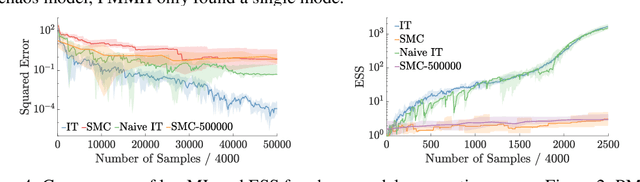
We introduce inference trees (ITs), a new class of inference methods that build on ideas from Monte Carlo tree search to perform adaptive sampling in a manner that balances exploration with exploitation, ensures consistency, and alleviates pathologies in existing adaptive methods. ITs adaptively sample from hierarchical partitions of the parameter space, while simultaneously learning these partitions in an online manner. This enables ITs to not only identify regions of high posterior mass, but also maintain uncertainty estimates to track regions where significant posterior mass may have been missed. ITs can be based on any inference method that provides a consistent estimate of the marginal likelihood. They are particularly effective when combined with sequential Monte Carlo, where they capture long-range dependencies and yield improvements beyond proposal adaptation alone.
Controllable Semantic Image Inpainting
Jun 15, 2018
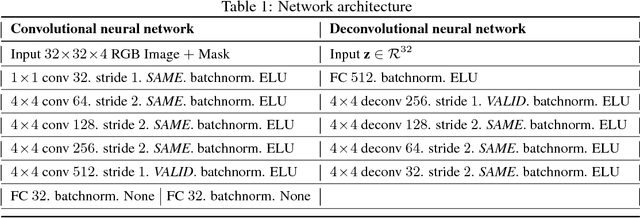
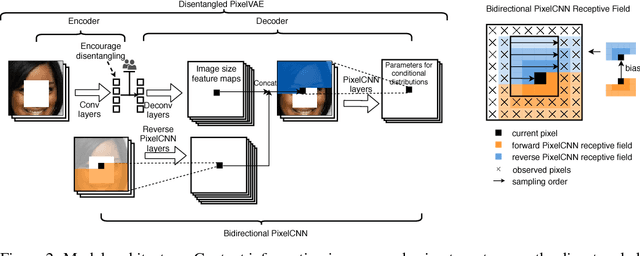

We develop a method for user-controllable semantic image inpainting: Given an arbitrary set of observed pixels, the unobserved pixels can be imputed in a user-controllable range of possibilities, each of which is semantically coherent and locally consistent with the observed pixels. We achieve this using a deep generative model bringing together: an encoder which can encode an arbitrary set of observed pixels, latent variables which are trained to represent disentangled factors of variations, and a bidirectional PixelCNN model. We experimentally demonstrate that our method can generate plausible inpainting results matching the user-specified semantics, but is still coherent with observed pixels. We justify our choices of architecture and training regime through more experiments.
Sequential Attend, Infer, Repeat: Generative Modelling of Moving Objects
Jun 05, 2018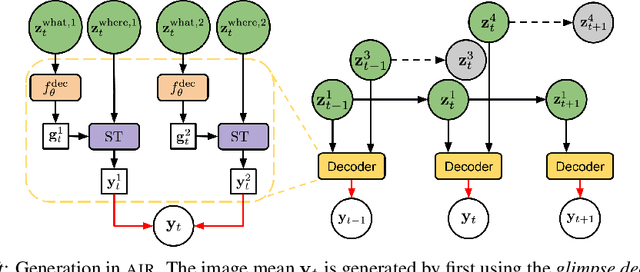
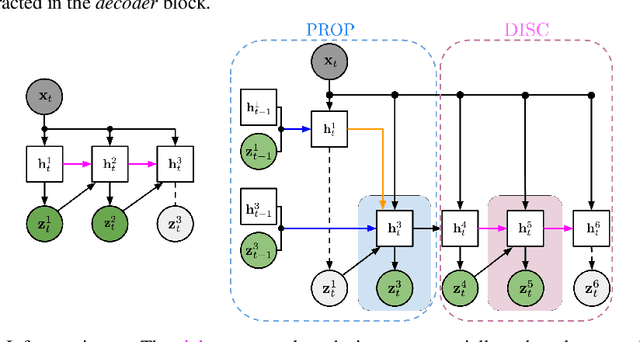
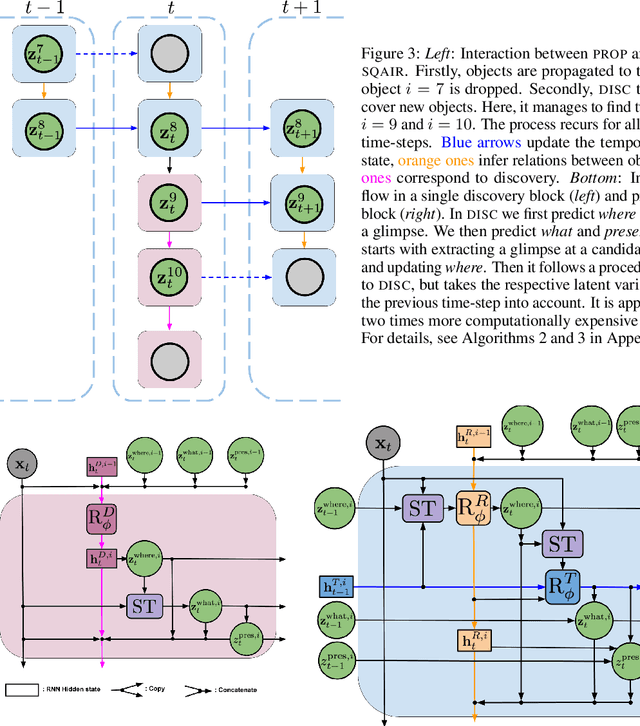

We present Sequential Attend, Infer, Repeat (SQAIR), an interpretable deep generative model for videos of moving objects. It can reliably discover and track objects throughout the sequence of frames, and can also generate future frames conditioning on the current frame, thereby simulating expected motion of objects. This is achieved by explicitly encoding object presence, locations and appearances in the latent variables of the model. SQAIR retains all strengths of its predecessor, Attend, Infer, Repeat (AIR, Eslami et. al., 2016), including learning in an unsupervised manner, and addresses its shortcomings. We use a moving multi-MNIST dataset to show limitations of AIR in detecting overlapping or partially occluded objects, and show how SQAIR overcomes them by leveraging temporal consistency of objects. Finally, we also apply SQAIR to real-world pedestrian CCTV data, where it learns to reliably detect, track and generate walking pedestrians with no supervision.
Mix&Match - Agent Curricula for Reinforcement Learning
Jun 05, 2018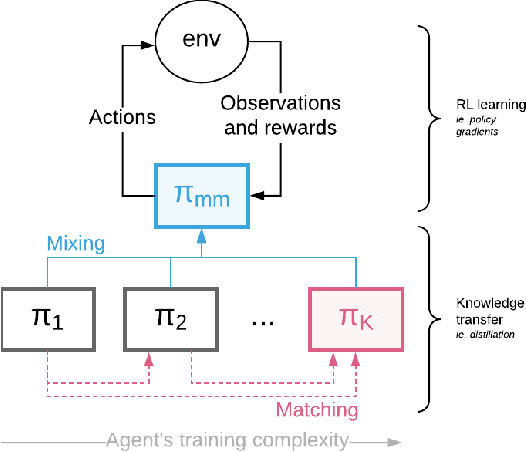
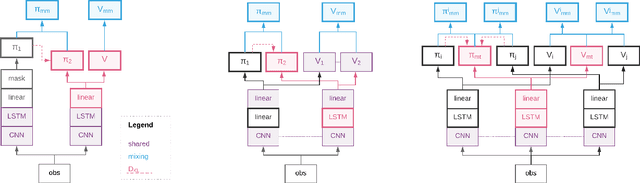
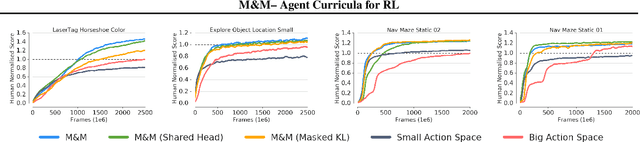
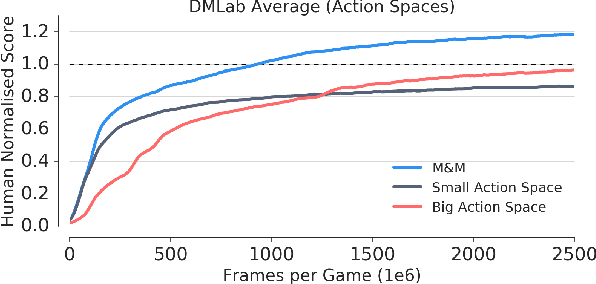
We introduce Mix&Match (M&M) - a training framework designed to facilitate rapid and effective learning in RL agents, especially those that would be too slow or too challenging to train otherwise. The key innovation is a procedure that allows us to automatically form a curriculum over agents. Through such a curriculum we can progressively train more complex agents by, effectively, bootstrapping from solutions found by simpler agents. In contradistinction to typical curriculum learning approaches, we do not gradually modify the tasks or environments presented, but instead use a process to gradually alter how the policy is represented internally. We show the broad applicability of our method by demonstrating significant performance gains in three different experimental setups: (1) We train an agent able to control more than 700 actions in a challenging 3D first-person task; using our method to progress through an action-space curriculum we achieve both faster training and better final performance than one obtains using traditional methods. (2) We further show that M&M can be used successfully to progress through a curriculum of architectural variants defining an agents internal state. (3) Finally, we illustrate how a variant of our method can be used to improve agent performance in a multitask setting.