 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin for O-RAN Towards 6G
Oct 03, 2024In future wireless systems of beyond 5G and 6G, addressing diverse applications with varying quality requirements is essential. Open Radio Access Network (O-RAN) architectures offer the potential for dynamic resource adaptation based on traffic demands. However, achieving real-time resource orchestration remains a challenge. Simultaneously, Digital Twin (DT) technology holds promise for testing and analysing complex systems, offering a unique platform for addressing dynamic operation and automation in O-RAN architectures. Yet, developing DTs for complex 5G/6G networks poses challenges, including data exchanges, ML model training data availability, network dynamics, processing power limitations, interdisciplinary collaboration needs, and a lack of standardized methodologies. This paper provides an overview of Open RAN architecture, trend and challenges, proposing the DT concepts for O-RAN with solution examples showcasing its integration into the framework.
Firefly Algorithm for Movable Antenna Arrays
Sep 06, 2024



This letter addresses a multivariate optimization problem for linear movable antenna arrays (MAAs). Particularly, the position and beamforming vectors of the under-investigated MAA are optimized simultaneously to maximize the minimum beamforming gain across several intended directions, while ensuring interference levels at various unintended directions remain below specified thresholds. To this end, a swarm-intelligence-based firefly algorithm (FA) is introduced to acquire an effective solution to the optimization problem. Simulation results reveal the superior performance of the proposed FA approach compared to the state-of-the-art approach employing alternating optimization and successive convex approximation. This is attributed to the FA's effectiveness in handling non-convex multivariate and multimodal optimization problems without resorting approximations.
Arena 3.0: Advancing Social Navigation in Collaborative and Highly Dynamic Environments
Jun 02, 2024



Building upon our previous contributions, this paper introduces Arena 3.0, an extension of Arena-Bench, Arena 1.0, and Arena 2.0. Arena 3.0 is a comprehensive software stack containing multiple modules and simulation environments focusing on the development, simulation, and benchmarking of social navigation approaches in collaborative environments. We significantly enhance the realism of human behavior simulation by incorporating a diverse array of new social force models and interaction patterns, encompassing both human-human and human-robot dynamics. The platform provides a comprehensive set of new task modes, designed for extensive benchmarking and testing and is capable of generating realistic and human-centric environments dynamically, catering to a broad spectrum of social navigation scenarios. In addition, the platform's functionalities have been abstracted across three widely used simulators, each tailored for specific training and testing purposes. The platform's efficacy has been validated through an extensive benchmark and user evaluations of the platform by a global community of researchers and students, which noted the substantial improvement compared to previous versions and expressed interests to utilize the platform for future research and development. Arena 3.0 is openly available at https://github.com/Arena-Rosnav.
* 11 pages, 6 figures
Robust Inverse Graphics via Probabilistic Inference
Feb 02, 2024



How do we infer a 3D scene from a single image in the presence of corruptions like rain, snow or fog? Straightforward domain randomization relies on knowing the family of corruptions ahead of time. Here, we propose a Bayesian approach-dubbed robust inverse graphics (RIG)-that relies on a strong scene prior and an uninformative uniform corruption prior, making it applicable to a wide range of corruptions. Given a single image, RIG performs posterior inference jointly over the scene and the corruption. We demonstrate this idea by training a neural radiance field (NeRF) scene prior and using a secondary NeRF to represent the corruptions over which we place an uninformative prior. RIG, trained only on clean data, outperforms depth estimators and alternative NeRF approaches that perform point estimation instead of full inference. The results hold for a number of scene prior architectures based on normalizing flows and diffusion models. For the latter, we develop reconstruction-guidance with auxiliary latents (ReGAL)-a diffusion conditioning algorithm that is applicable in the presence of auxiliary latent variables such as the corruption. RIG demonstrates how scene priors can be used beyond generation tasks.
Training Chain-of-Thought via Latent-Variable Inference
Nov 28, 2023



Large language models (LLMs) solve problems more accurately and interpretably when instructed to work out the answer step by step using a ``chain-of-thought'' (CoT) prompt. One can also improve LLMs' performance on a specific task by supervised fine-tuning, i.e., by using gradient ascent on some tunable parameters to maximize the average log-likelihood of correct answers from a labeled training set. Naively combining CoT with supervised tuning requires supervision not just of the correct answers, but also of detailed rationales that lead to those answers; these rationales are expensive to produce by hand. Instead, we propose a fine-tuning strategy that tries to maximize the \emph{marginal} log-likelihood of generating a correct answer using CoT prompting, approximately averaging over all possible rationales. The core challenge is sampling from the posterior over rationales conditioned on the correct answer; we address it using a simple Markov-chain Monte Carlo (MCMC) expectation-maximization (EM) algorithm inspired by the self-taught reasoner (STaR), memoized wake-sleep, Markovian score climbing, and persistent contrastive divergence. This algorithm also admits a novel control-variate technique that drives the variance of our gradient estimates to zero as the model improves. Applying our technique to GSM8K and the tasks in BIG-Bench Hard, we find that this MCMC-EM fine-tuning technique typically improves the model's accuracy on held-out examples more than STaR or prompt-tuning with or without CoT.
Generalized Firefly Algorithm for Optimal Transmit Beamforming
Oct 27, 2023



This paper proposes a generalized Firefly Algorithm (FA) to solve an optimization framework having objective function and constraints as multivariate functions of independent optimization variables. Four representative examples of how the proposed generalized FA can be adopted to solve downlink beamforming problems are shown for a classic transmit beamforming, cognitive beamforming, reconfigurable-intelligent-surfaces-aided (RIS-aided) transmit beamforming, and RIS-aided wireless power transfer (WPT). Complexity analyzes indicate that in large-antenna regimes the proposed FA approaches require less computational complexity than their corresponding interior point methods (IPMs) do, yet demand a higher complexity than the iterative and the successive convex approximation (SCA) approaches do. Simulation results reveal that the proposed FA attains the same global optimal solution as that of the IPM for an optimization problem in cognitive beamforming. On the other hand, the proposed FA approaches outperform the iterative, IPM and SCA in terms of obtaining better solution for optimization problems, respectively, for a classic transmit beamforming, RIS-aided transmit beamforming and RIS-aided WPT.
Neural Amortized Inference for Nested Multi-agent Reasoning
Aug 21, 2023



Multi-agent interactions, such as communication, teaching, and bluffing, often rely on higher-order social inference, i.e., understanding how others infer oneself. Such intricate reasoning can be effectively modeled through nested multi-agent reasoning. Nonetheless, the computational complexity escalates exponentially with each level of reasoning, posing a significant challenge. However, humans effortlessly perform complex social inferences as part of their daily lives. To bridge the gap between human-like inference capabilities and computational limitations, we propose a novel approach: leveraging neural networks to amortize high-order social inference, thereby expediting nested multi-agent reasoning. We evaluate our method in two challenging multi-agent interaction domains. The experimental results demonstrate that our method is computationally efficient while exhibiting minimal degradation in accuracy.
Arena-Rosnav 2.0: A Development and Benchmarking Platform for Robot Navigation in Highly Dynamic Environments
Feb 20, 2023Following up on our previous works, in this paper, we present Arena-Rosnav 2.0 an extension to our previous works Arena-Bench and Arena-Rosnav, which adds a variety of additional modules for developing and benchmarking robotic navigation approaches. The platform is fundamentally restructured and provides unified APIs to add additional functionalities such as planning algorithms, simulators, or evaluation functionalities. We have included more realistic simulation and pedestrian behavior and provide a profound documentation to lower the entry barrier. We evaluated our system by first, conducting a user study in which we asked experienced researchers as well as new practitioners and students to test our system. The feedback was mostly positive and a high number of participants are utilizing our system for other research endeavors. Finally, we demonstrate the feasibility of our system by integrating two new simulators and a variety of state of the art navigation approaches and benchmark them against one another. The platform is openly available at https://github.com/Arena-Rosnav.
ProbNeRF: Uncertainty-Aware Inference of 3D Shapes from 2D Images
Oct 27, 2022



The problem of inferring object shape from a single 2D image is underconstrained. Prior knowledge about what objects are plausible can help, but even given such prior knowledge there may still be uncertainty about the shapes of occluded parts of objects. Recently, conditional neural radiance field (NeRF) models have been developed that can learn to infer good point estimates of 3D models from single 2D images. The problem of inferring uncertainty estimates for these models has received less attention. In this work, we propose probabilistic NeRF (ProbNeRF), a model and inference strategy for learning probabilistic generative models of 3D objects' shapes and appearances, and for doing posterior inference to recover those properties from 2D images. ProbNeRF is trained as a variational autoencoder, but at test time we use Hamiltonian Monte Carlo (HMC) for inference. Given one or a few 2D images of an object (which may be partially occluded), ProbNeRF is able not only to accurately model the parts it sees, but also to propose realistic and diverse hypotheses about the parts it does not see. We show that key to the success of ProbNeRF are (i) a deterministic rendering scheme, (ii) an annealed-HMC strategy, (iii) a hypernetwork-based decoder architecture, and (iv) doing inference over a full set of NeRF weights, rather than just a low-dimensional code.
Arena-Bench: A Benchmarking Suite for Obstacle Avoidance Approaches in Highly Dynamic Environments
Jun 12, 2022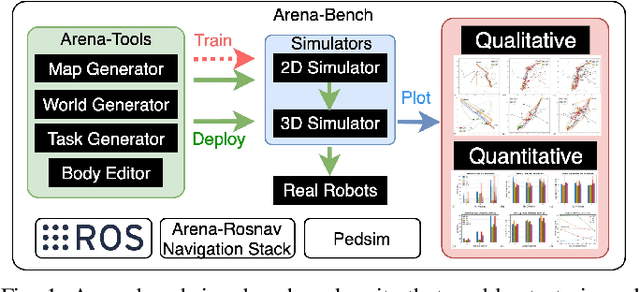
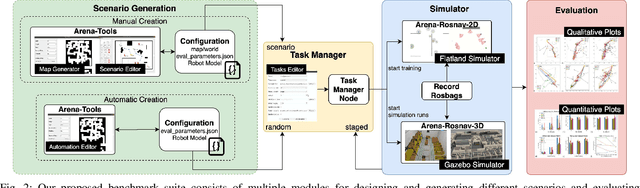
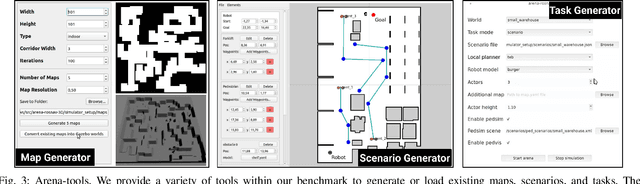
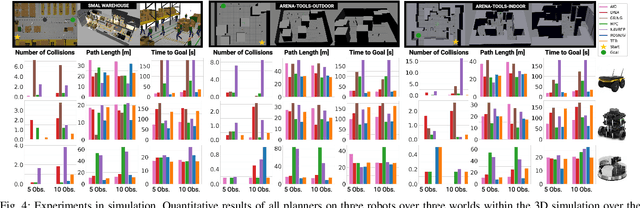
The ability to autonomously navigate safely, especially within dynamic environments, is paramount for mobile robotics. In recent years, DRL approaches have shown superior performance in dynamic obstacle avoidance. However, these learning-based approaches are often developed in specially designed simulation environments and are hard to test against conventional planning approaches. Furthermore, the integration and deployment of these approaches into real robotic platforms are not yet completely solved. In this paper, we present Arena-bench, a benchmark suite to train, test, and evaluate navigation planners on different robotic platforms within 3D environments. It provides tools to design and generate highly dynamic evaluation worlds, scenarios, and tasks for autonomous navigation and is fully integrated into the robot operating system. To demonstrate the functionalities of our suite, we trained a DRL agent on our platform and compared it against a variety of existing different model-based and learning-based navigation approaches on a variety of relevant metrics. Finally, we deployed the approaches towards real robots and demonstrated the reproducibility of the results. The code is publicly available at github.com/ignc-research/arena-bench.