 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaritime Communication in Evaporation Duct Environment with Ship Trajectory Optimization
Oct 08, 2025In maritime wireless networks, the evaporation duct effect has been known as a preferable condition for long-range transmissions. However, how to effectively utilize the duct effect for efficient communication design is still open for investigation. In this paper, we consider a typical scenario of ship-to-shore data transmission, where a ship collects data from multiple oceanographic buoys, sails from one to another, and transmits the collected data back to a terrestrial base station during its voyage. A novel framework, which exploits priori information of the channel gain map in the presence of evaporation duct, is proposed to minimize the data transmission time and the sailing time by optimizing the ship's trajectory. To this end, a multi-objective optimization problem is formulated and is further solved by a dynamic population PSO-integrated NSGA-II algorithm. Through simulations, it is demonstrated that, compared to the benchmark scheme which ignores useful information of the evaporation duct, the proposed scheme can effectively reduce both the data transmission time and the sailing time.
Design and Control of a Perching Drone Inspired by the Prey-Capturing Mechanism of Venus Flytrap
Sep 16, 2025
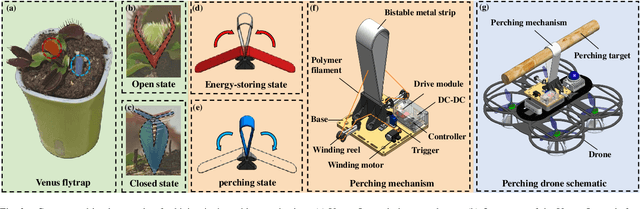
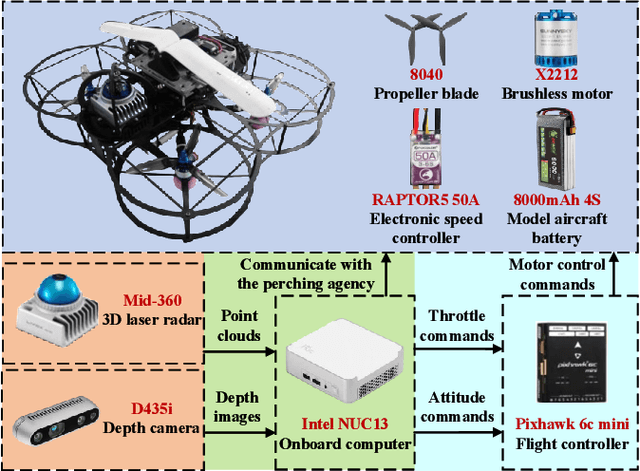
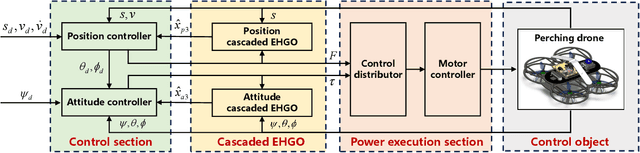
The endurance and energy efficiency of drones remain critical challenges in their design and operation. To extend mission duration, numerous studies explored perching mechanisms that enable drones to conserve energy by temporarily suspending flight. This paper presents a new perching drone that utilizes an active flexible perching mechanism inspired by the rapid predation mechanism of the Venus flytrap, achieving perching in less than 100 ms. The proposed system is designed for high-speed adaptability to the perching targets. The overall drone design is outlined, followed by the development and validation of the biomimetic perching structure. To enhance the system stability, a cascade extended high-gain observer (EHGO) based control method is developed, which can estimate and compensate for the external disturbance in real time. The experimental results demonstrate the adaptability of the perching structure and the superiority of the cascaded EHGO in resisting wind and perching disturbances.
ArgusCogito: Chain-of-Thought for Cross-Modal Synergy and Omnidirectional Reasoning in Camouflaged Object Segmentation
Aug 25, 2025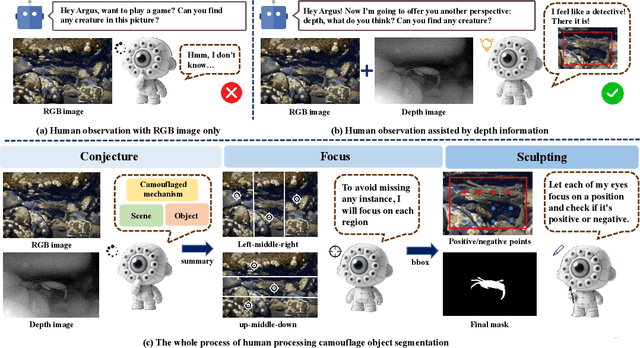
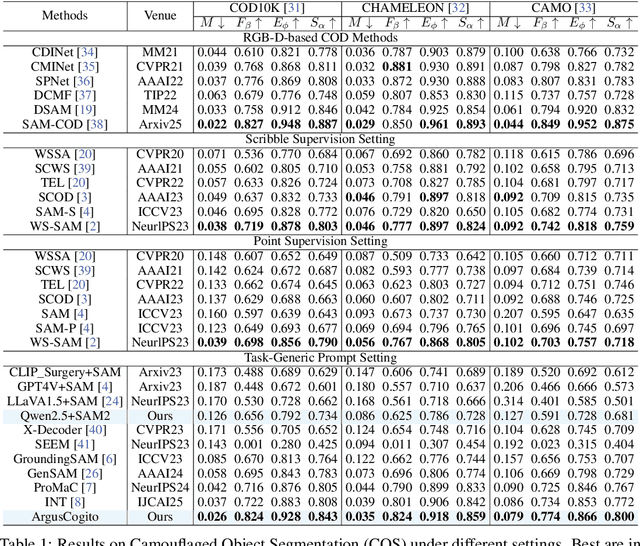
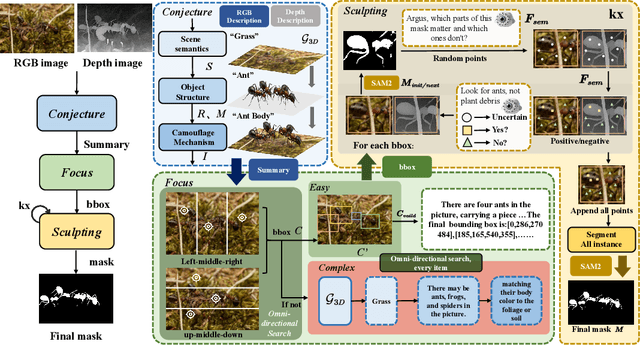
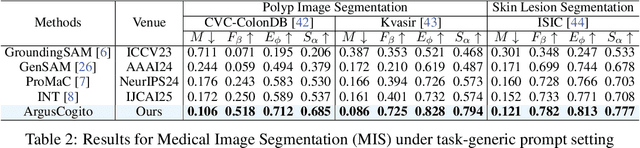
Camouflaged Object Segmentation (COS) poses a significant challenge due to the intrinsic high similarity between targets and backgrounds, demanding models capable of profound holistic understanding beyond superficial cues. Prevailing methods, often limited by shallow feature representation, inadequate reasoning mechanisms, and weak cross-modal integration, struggle to achieve this depth of cognition, resulting in prevalent issues like incomplete target separation and imprecise segmentation. Inspired by the perceptual strategy of the Hundred-eyed Giant-emphasizing holistic observation, omnidirectional focus, and intensive scrutiny-we introduce ArgusCogito, a novel zero-shot, chain-of-thought framework underpinned by cross-modal synergy and omnidirectional reasoning within Vision-Language Models (VLMs). ArgusCogito orchestrates three cognitively-inspired stages: (1) Conjecture: Constructs a strong cognitive prior through global reasoning with cross-modal fusion (RGB, depth, semantic maps), enabling holistic scene understanding and enhanced target-background disambiguation. (2) Focus: Performs omnidirectional, attention-driven scanning and focused reasoning, guided by semantic priors from Conjecture, enabling precise target localization and region-of-interest refinement. (3) Sculpting: Progressively sculpts high-fidelity segmentation masks by integrating cross-modal information and iteratively generating dense positive/negative point prompts within focused regions, emulating Argus' intensive scrutiny. Extensive evaluations on four challenging COS benchmarks and three Medical Image Segmentation (MIS) benchmarks demonstrate that ArgusCogito achieves state-of-the-art (SOTA) performance, validating the framework's exceptional efficacy, superior generalization capability, and robustness.
Physics-informed deep operator network for traffic state estimation
Aug 18, 2025



Traffic state estimation (TSE) fundamentally involves solving high-dimensional spatiotemporal partial differential equations (PDEs) governing traffic flow dynamics from limited, noisy measurements. While Physics-Informed Neural Networks (PINNs) enforce PDE constraints point-wise, this paper adopts a physics-informed deep operator network (PI-DeepONet) framework that reformulates TSE as an operator learning problem. Our approach trains a parameterized neural operator that maps sparse input data to the full spatiotemporal traffic state field, governed by the traffic flow conservation law. Crucially, unlike PINNs that enforce PDE constraints point-wise, PI-DeepONet integrates traffic flow conservation model and the fundamental diagram directly into the operator learning process, ensuring physical consistency while capturing congestion propagation, spatial correlations, and temporal evolution. Experiments on the NGSIM dataset demonstrate superior performance over state-of-the-art baselines. Further analysis reveals insights into optimal function generation strategies and branch network complexity. Additionally, the impact of input function generation methods and the number of functions on model performance is explored, highlighting the robustness and efficacy of proposed framework.
Multi-Masked Querying Network for Robust Emotion Recognition from Incomplete Multi-Modal Physiological Signals
Jul 28, 2025Emotion recognition from physiological data is crucial for mental health assessment, yet it faces two significant challenges: incomplete multi-modal signals and interference from body movements and artifacts. This paper presents a novel Multi-Masked Querying Network (MMQ-Net) to address these issues by integrating multiple querying mechanisms into a unified framework. Specifically, it uses modality queries to reconstruct missing data from incomplete signals, category queries to focus on emotional state features, and interference queries to separate relevant information from noise. Extensive experiment results demonstrate the superior emotion recognition performance of MMQ-Net compared to existing approaches, particularly under high levels of data incompleteness.
Block-wise Adaptive Caching for Accelerating Diffusion Policy
Jun 16, 2025Diffusion Policy has demonstrated strong visuomotor modeling capabilities, but its high computational cost renders it impractical for real-time robotic control. Despite huge redundancy across repetitive denoising steps, existing diffusion acceleration techniques fail to generalize to Diffusion Policy due to fundamental architectural and data divergences. In this paper, we propose Block-wise Adaptive Caching(BAC), a method to accelerate Diffusion Policy by caching intermediate action features. BAC achieves lossless action generation acceleration by adaptively updating and reusing cached features at the block level, based on a key observation that feature similarities vary non-uniformly across timesteps and locks. To operationalize this insight, we first propose the Adaptive Caching Scheduler, designed to identify optimal update timesteps by maximizing the global feature similarities between cached and skipped features. However, applying this scheduler for each block leads to signiffcant error surges due to the inter-block propagation of caching errors, particularly within Feed-Forward Network (FFN) blocks. To mitigate this issue, we develop the Bubbling Union Algorithm, which truncates these errors by updating the upstream blocks with signiffcant caching errors before downstream FFNs. As a training-free plugin, BAC is readily integrable with existing transformer-based Diffusion Policy and vision-language-action models. Extensive experiments on multiple robotic benchmarks demonstrate that BAC achieves up to 3x inference speedup for free.
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Jun 15, 2025Vision-Language-Action (VLA) models have attracted increasing attention for their strong control capabilities. However, their high computational cost and low execution frequency hinder their suitability for real-time tasks such as robotic manipulation and autonomous navigation. Existing VLA acceleration methods primarily focus on structural optimization, overlooking the fact that these models operate in sequential decision-making environments. As a result, temporal redundancy in sequential action generation and spatial redundancy in visual input remain unaddressed. To this end, we propose SP-VLA, a unified framework that accelerates VLA models by jointly scheduling models and pruning tokens. Specifically, we design an action-aware model scheduling mechanism that reduces temporal redundancy by dynamically switching between VLA model and a lightweight generator. Inspired by the human motion pattern of focusing on key decision points while relying on intuition for other actions, we categorize VLA actions into deliberative and intuitive, assigning the former to the VLA model and the latter to the lightweight generator, enabling frequency-adaptive execution through collaborative model scheduling. To address spatial redundancy, we further develop a spatio-semantic dual-aware token pruning method. Tokens are classified into spatial and semantic types and pruned based on their dual-aware importance to accelerate VLA inference. These two mechanisms work jointly to guide the VLA in focusing on critical actions and salient visual information, achieving effective acceleration while maintaining high accuracy. Experimental results demonstrate that our method achieves up to 1.5$\times$ acceleration with less than 3% drop in accuracy, outperforming existing approaches in multiple tasks.
Image Segmentation via Variational Model Based Tailored UNet: A Deep Variational Framework
May 09, 2025Traditional image segmentation methods, such as variational models based on partial differential equations (PDEs), offer strong mathematical interpretability and precise boundary modeling, but often suffer from sensitivity to parameter settings and high computational costs. In contrast, deep learning models such as UNet, which are relatively lightweight in parameters, excel in automatic feature extraction but lack theoretical interpretability and require extensive labeled data. To harness the complementary strengths of both paradigms, we propose Variational Model Based Tailored UNet (VM_TUNet), a novel hybrid framework that integrates the fourth-order modified Cahn-Hilliard equation with the deep learning backbone of UNet, which combines the interpretability and edge-preserving properties of variational methods with the adaptive feature learning of neural networks. Specifically, a data-driven operator is introduced to replace manual parameter tuning, and we incorporate the tailored finite point method (TFPM) to enforce high-precision boundary preservation. Experimental results on benchmark datasets demonstrate that VM_TUNet achieves superior segmentation performance compared to existing approaches, especially for fine boundary delineation.
SonarT165: A Large-scale Benchmark and STFTrack Framework for Acoustic Object Tracking
Apr 22, 2025



Underwater observation systems typically integrate optical cameras and imaging sonar systems. When underwater visibility is insufficient, only sonar systems can provide stable data, which necessitates exploration of the underwater acoustic object tracking (UAOT) task. Previous studies have explored traditional methods and Siamese networks for UAOT. However, the absence of a unified evaluation benchmark has significantly constrained the value of these methods. To alleviate this limitation, we propose the first large-scale UAOT benchmark, SonarT165, comprising 165 square sequences, 165 fan sequences, and 205K high-quality annotations. Experimental results demonstrate that SonarT165 reveals limitations in current state-of-the-art SOT trackers. To address these limitations, we propose STFTrack, an efficient framework for acoustic object tracking. It includes two novel modules, a multi-view template fusion module (MTFM) and an optimal trajectory correction module (OTCM). The MTFM module integrates multi-view feature of both the original image and the binary image of the dynamic template, and introduces a cross-attention-like layer to fuse the spatio-temporal target representations. The OTCM module introduces the acoustic-response-equivalent pixel property and proposes normalized pixel brightness response scores, thereby suppressing suboptimal matches caused by inaccurate Kalman filter prediction boxes. To further improve the model feature, STFTrack introduces a acoustic image enhancement method and a Frequency Enhancement Module (FEM) into its tracking pipeline. Comprehensive experiments show the proposed STFTrack achieves state-of-the-art performance on the proposed benchmark. The code is available at https://github.com/LiYunfengLYF/SonarT165.
RGBSQGrasp: Inferring Local Superquadric Primitives from Single RGB Image for Graspability-Aware Bin Picking
Mar 04, 2025Bin picking is a challenging robotic task due to occlusions and physical constraints that limit visual information for object recognition and grasping. Existing approaches often rely on known CAD models or prior object geometries, restricting generalization to novel or unknown objects. Other methods directly regress grasp poses from RGB-D data without object priors, but the inherent noise in depth sensing and the lack of object understanding make grasp synthesis and evaluation more difficult. Superquadrics (SQ) offer a compact, interpretable shape representation that captures the physical and graspability understanding of objects. However, recovering them from limited viewpoints is challenging, as existing methods rely on multiple perspectives for near-complete point cloud reconstruction, limiting their effectiveness in bin-picking. To address these challenges, we propose \textbf{RGBSQGrasp}, a grasping framework that leverages superquadric shape primitives and foundation metric depth estimation models to infer grasp poses from a monocular RGB camera -- eliminating the need for depth sensors. Our framework integrates a universal, cross-platform dataset generation pipeline, a foundation model-based object point cloud estimation module, a global-local superquadric fitting network, and an SQ-guided grasp pose sampling module. By integrating these components, RGBSQGrasp reliably infers grasp poses through geometric reasoning, enhancing grasp stability and adaptability to unseen objects. Real-world robotic experiments demonstrate a 92\% grasp success rate, highlighting the effectiveness of RGBSQGrasp in packed bin-picking environments.