 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020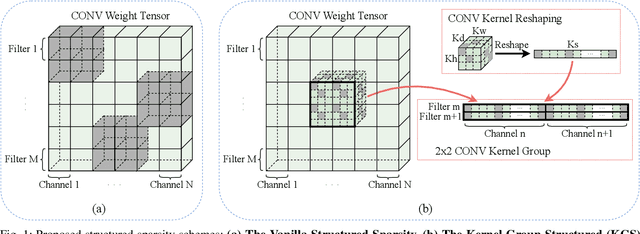
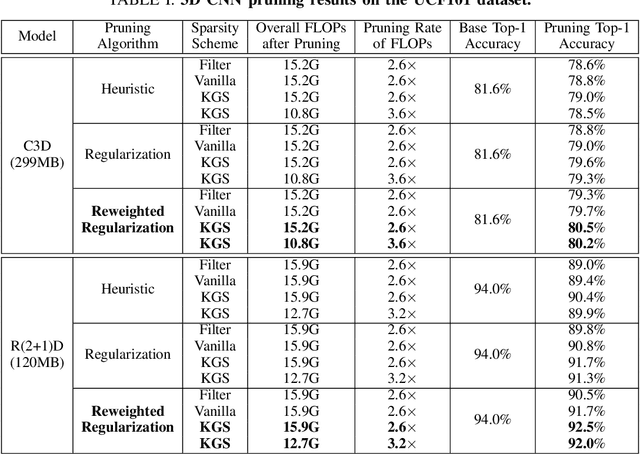
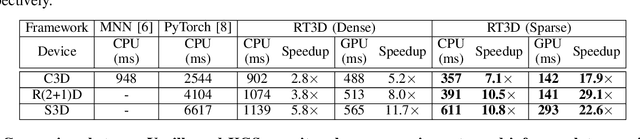

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.
Towards Real-Time DNN Inference on Mobile Platforms with Model Pruning and Compiler Optimization
Apr 22, 2020
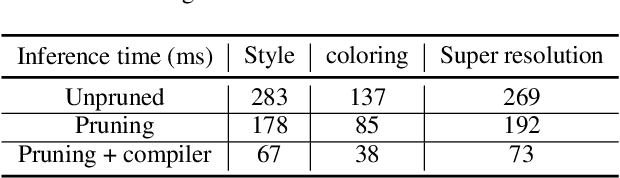
High-end mobile platforms rapidly serve as primary computing devices for a wide range of Deep Neural Network (DNN) applications. However, the constrained computation and storage resources on these devices still pose significant challenges for real-time DNN inference executions. To address this problem, we propose a set of hardware-friendly structured model pruning and compiler optimization techniques to accelerate DNN executions on mobile devices. This demo shows that these optimizations can enable real-time mobile execution of multiple DNN applications, including style transfer, DNN coloring and super resolution.
A Unified DNN Weight Compression Framework Using Reweighted Optimization Methods
Apr 12, 2020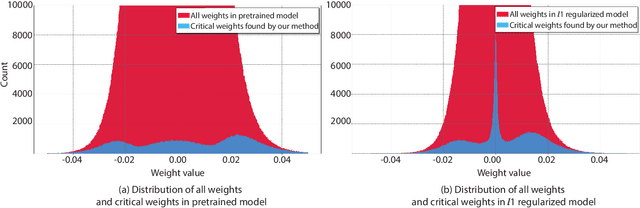

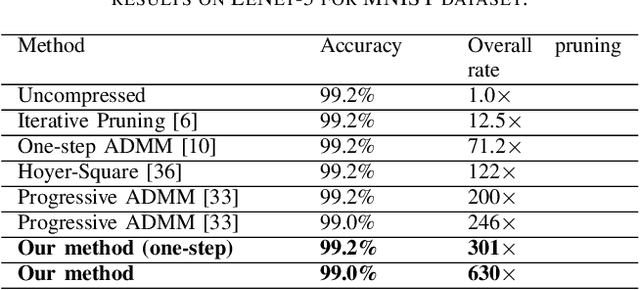
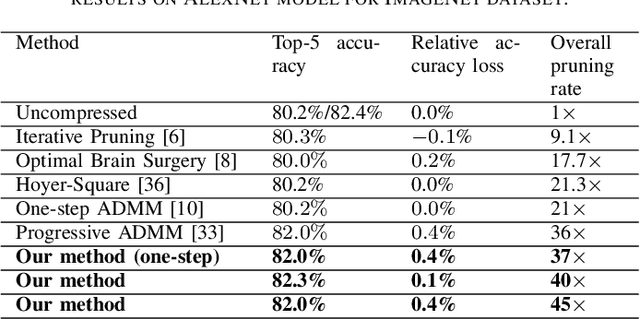
To address the large model size and intensive computation requirement of deep neural networks (DNNs), weight pruning techniques have been proposed and generally fall into two categories, i.e., static regularization-based pruning and dynamic regularization-based pruning. However, the former method currently suffers either complex workloads or accuracy degradation, while the latter one takes a long time to tune the parameters to achieve the desired pruning rate without accuracy loss. In this paper, we propose a unified DNN weight pruning framework with dynamically updated regularization terms bounded by the designated constraint, which can generate both non-structured sparsity and different kinds of structured sparsity. We also extend our method to an integrated framework for the combination of different DNN compression tasks.
CoCoPIE: Making Mobile AI Sweet As PIE --Compression-Compilation Co-Design Goes a Long Way
Mar 25, 2020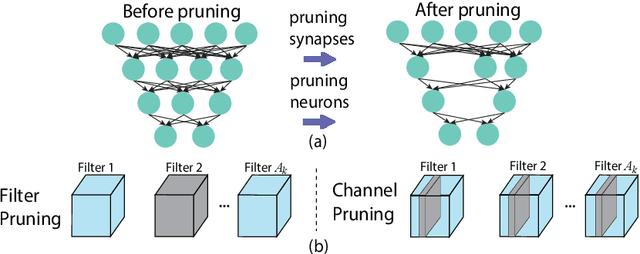

Assuming hardware is the major constraint for enabling real-time mobile intelligence, the industry has mainly dedicated their efforts to developing specialized hardware accelerators for machine learning and inference. This article challenges the assumption. By drawing on a recent real-time AI optimization framework CoCoPIE, it maintains that with effective compression-compiler co-design, it is possible to enable real-time artificial intelligence on mainstream end devices without special hardware. CoCoPIE is a software framework that holds numerous records on mobile AI: the first framework that supports all main kinds of DNNs, from CNNs to RNNs, transformer, language models, and so on; the fastest DNN pruning and acceleration framework, up to 180X faster compared with current DNN pruning on other frameworks such as TensorFlow-Lite; making many representative AI applications able to run in real-time on off-the-shelf mobile devices that have been previously regarded possible only with special hardware support; making off-the-shelf mobile devices outperform a number of representative ASIC and FPGA solutions in terms of energy efficiency and/or performance.
A Privacy-Preserving DNN Pruning and Mobile Acceleration Framework
Mar 13, 2020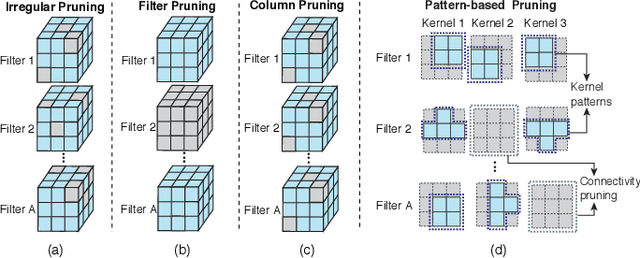
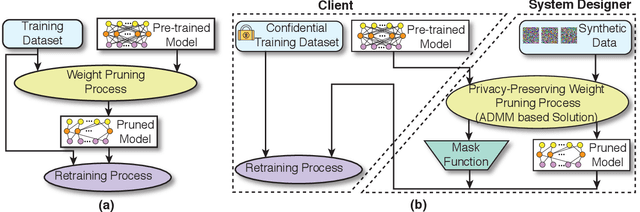
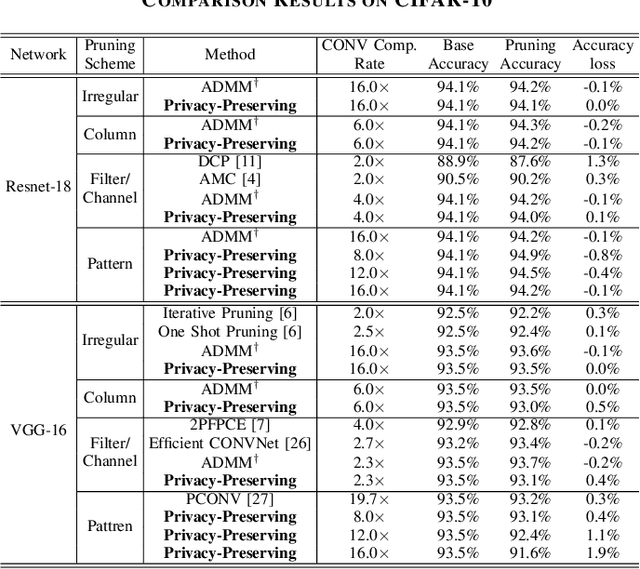
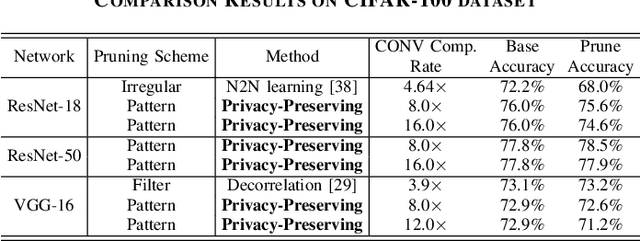
To facilitate the deployment of deep neural networks (DNNs) on resource-constrained computing systems, DNN model compression methods have been proposed. However, previous methods mainly focus on reducing the model size and/or improving hardware performance, without considering the data privacy requirement. This paper proposes a privacy-preserving model compression framework that formulates a privacy-preserving DNN weight pruning problem and develops an ADMM based solution to support different weight pruning schemes. We consider the case that the system designer will perform weight pruning on a pre-trained model provided by the client, whereas the client cannot share her confidential training dataset. To mitigate the non-availability of the training dataset, the system designer distills the knowledge of a pre-trained model into a pruned model using only randomly generated synthetic data. Then the client's effort is simply reduced to performing the retraining process using her confidential training dataset, which is similar as the DNN training process with the help of the mask function from the system designer. Both algorithmic and hardware experiments validate the effectiveness of the proposed framework.
BLK-REW: A Unified Block-based DNN Pruning Framework using Reweighted Regularization Method
Feb 22, 2020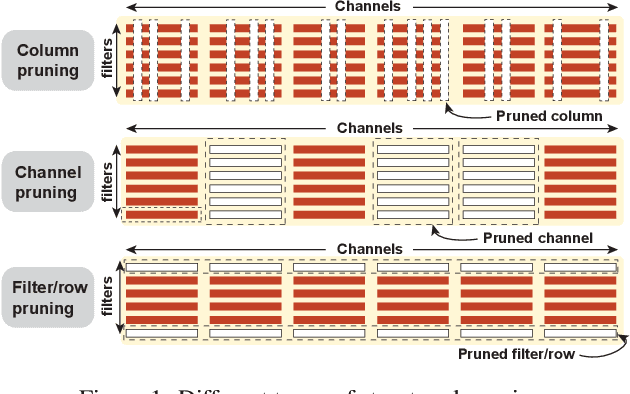
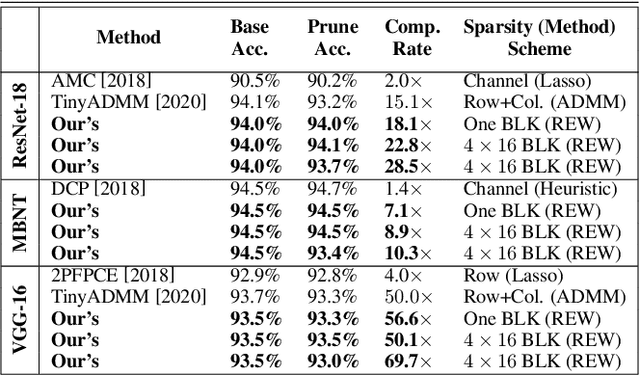
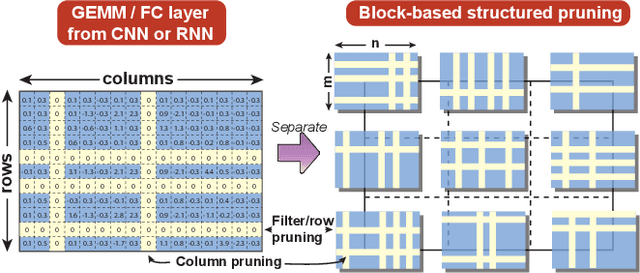
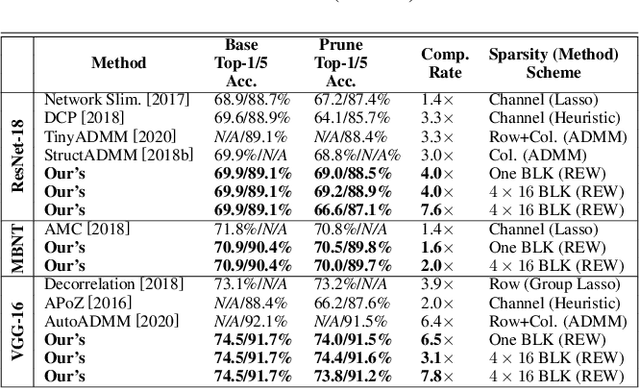
Accelerating DNN execution on various resource-limited computing platforms has been a long-standing problem. Prior works utilize l1-based group lasso or dynamic regularization such as ADMM to perform structured pruning on DNN models to leverage the parallel computing architectures. However, both of the pruning dimensions and pruning methods lack universality, which leads to degraded performance and limited applicability. To solve the problem, we propose a new block-based pruning framework that comprises a general and flexible structured pruning dimension as well as a powerful and efficient reweighted regularization method. Our framework is universal, which can be applied to both CNNs and RNNs, implying complete support for the two major kinds of computation-intensive layers (i.e., CONV and FC layers). To complete all aspects of the pruning-for-acceleration task, we also integrate compiler-based code optimization into our framework that can perform DNN inference in a real-time manner. To the best of our knowledge, it is the first time that the weight pruning framework achieves universal coverage for both CNNs and RNNs with real-time mobile acceleration and no accuracy compromise.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
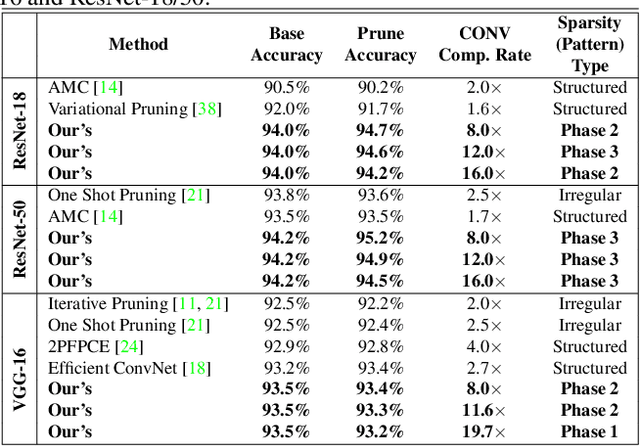
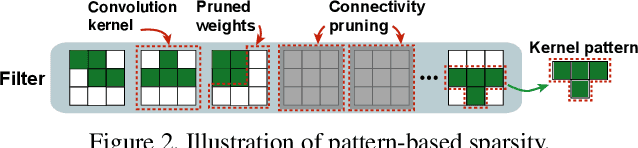
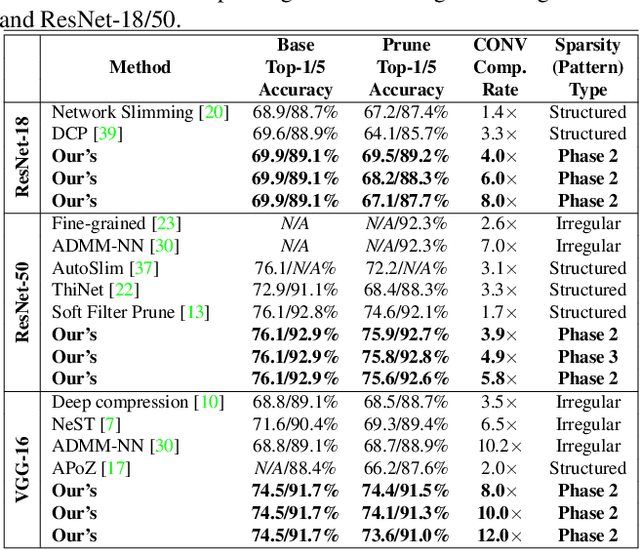
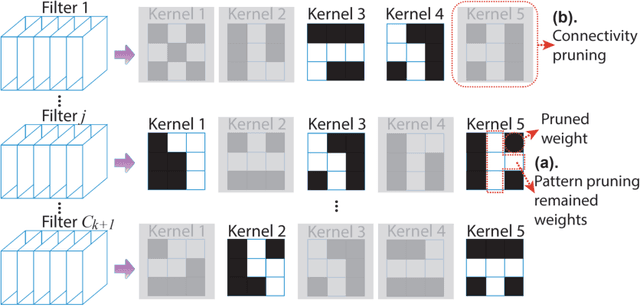
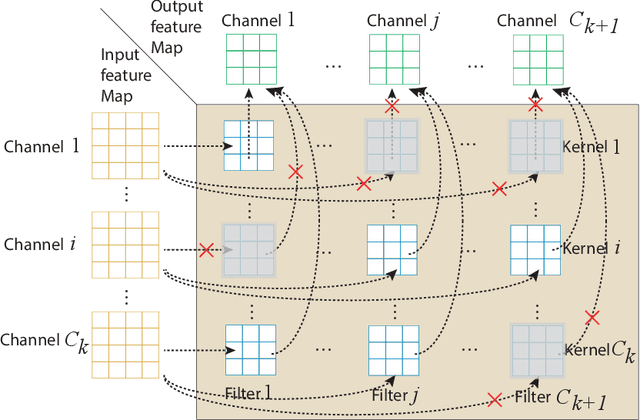
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.
RTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020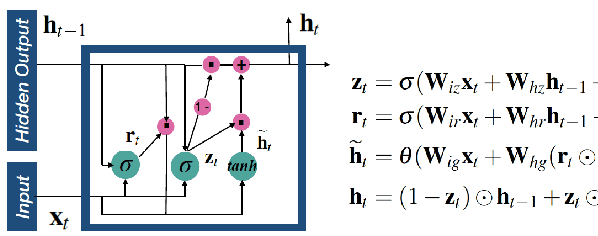
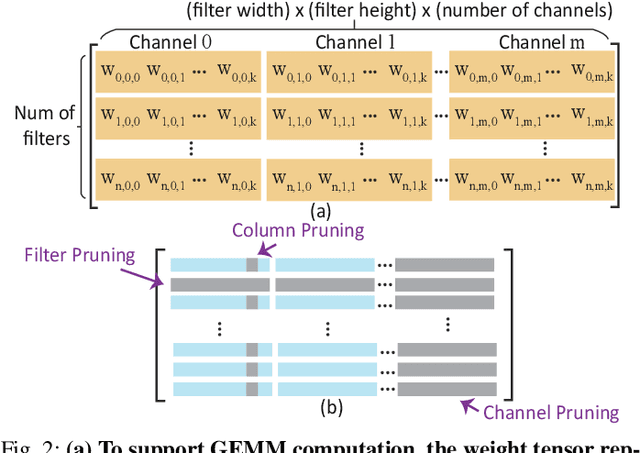
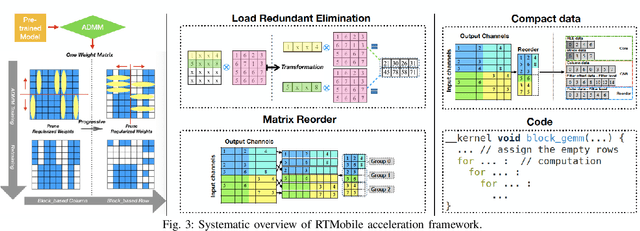
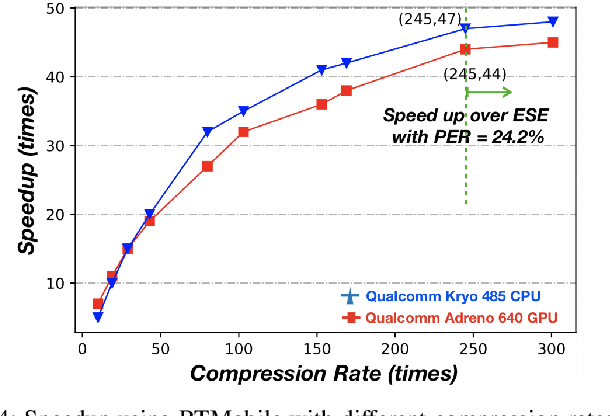
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.
Efficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Feb 12, 2020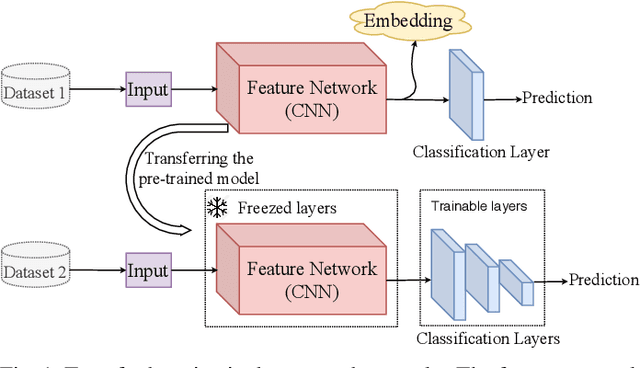
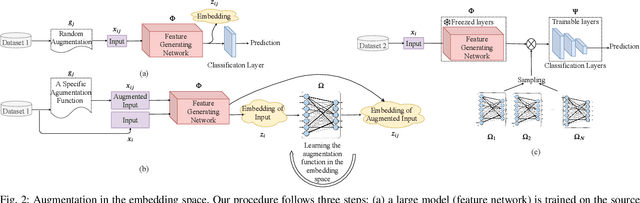
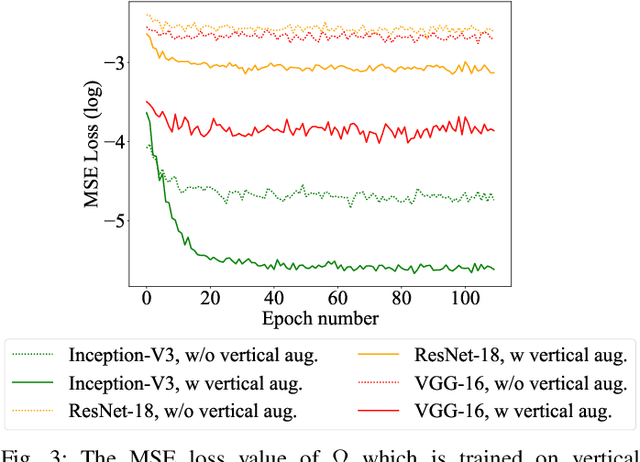
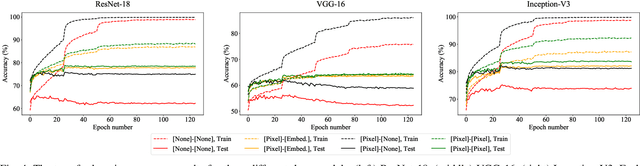
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.
PCNN: Pattern-based Fine-Grained Regular Pruning towards Optimizing CNN Accelerators
Feb 11, 2020
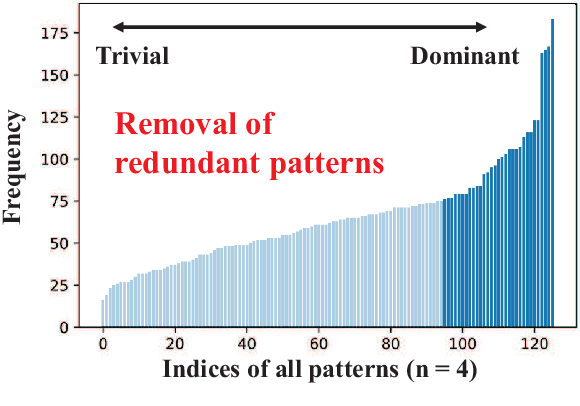
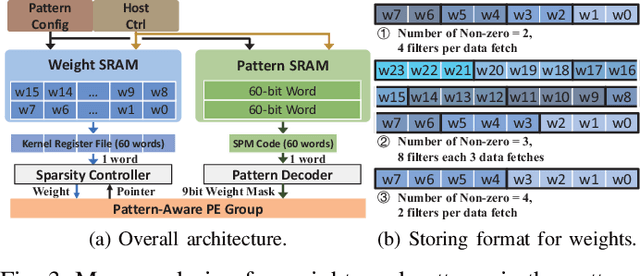
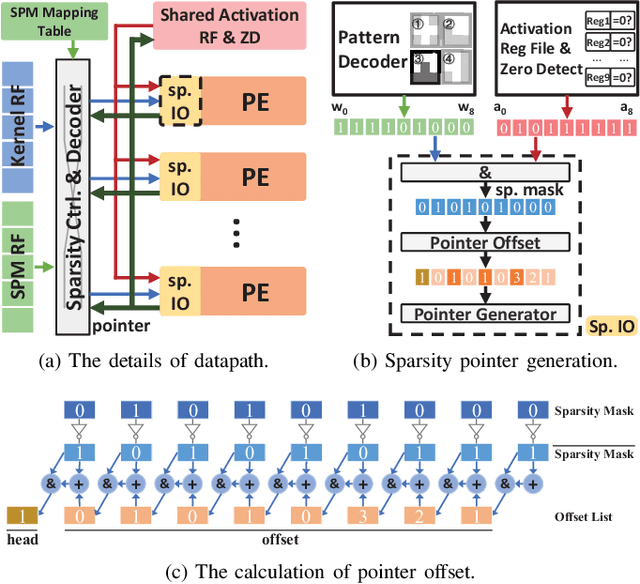
Weight pruning is a powerful technique to realize model compression. We propose PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves the compression rate up to 8.4X with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, achieving up to 9.0X speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.