 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
MUSAR: Exploring Multi-Subject Customization from Single-Subject Dataset via Attention Routing
May 05, 2025



Current multi-subject customization approaches encounter two critical challenges: the difficulty in acquiring diverse multi-subject training data, and attribute entanglement across different subjects. To bridge these gaps, we propose MUSAR - a simple yet effective framework to achieve robust multi-subject customization while requiring only single-subject training data. Firstly, to break the data limitation, we introduce debiased diptych learning. It constructs diptych training pairs from single-subject images to facilitate multi-subject learning, while actively correcting the distribution bias introduced by diptych construction via static attention routing and dual-branch LoRA. Secondly, to eliminate cross-subject entanglement, we introduce dynamic attention routing mechanism, which adaptively establishes bijective mappings between generated images and conditional subjects. This design not only achieves decoupling of multi-subject representations but also maintains scalable generalization performance with increasing reference subjects. Comprehensive experiments demonstrate that our MUSAR outperforms existing methods - even those trained on multi-subject dataset - in image quality, subject consistency, and interaction naturalness, despite requiring only single-subject dataset.
DreamO: A Unified Framework for Image Customization
Apr 23, 2025Recently, extensive research on image customization (e.g., identity, subject, style, background, etc.) demonstrates strong customization capabilities in large-scale generative models. However, most approaches are designed for specific tasks, restricting their generalizability to combine different types of condition. Developing a unified framework for image customization remains an open challenge. In this paper, we present DreamO, an image customization framework designed to support a wide range of tasks while facilitating seamless integration of multiple conditions. Specifically, DreamO utilizes a diffusion transformer (DiT) framework to uniformly process input of different types. During training, we construct a large-scale training dataset that includes various customization tasks, and we introduce a feature routing constraint to facilitate the precise querying of relevant information from reference images. Additionally, we design a placeholder strategy that associates specific placeholders with conditions at particular positions, enabling control over the placement of conditions in the generated results. Moreover, we employ a progressive training strategy consisting of three stages: an initial stage focused on simple tasks with limited data to establish baseline consistency, a full-scale training stage to comprehensively enhance the customization capabilities, and a final quality alignment stage to correct quality biases introduced by low-quality data. Extensive experiments demonstrate that the proposed DreamO can effectively perform various image customization tasks with high quality and flexibly integrate different types of control conditions.
Upper Mid-Band Channel Measurements and Characterization at 6.75 GHz FR1(C) and 16.95 GHz FR3 in an Indoor Factory Scenario
Nov 06, 2024



This paper presents detailed radio propagation measurements for an indoor factory (InF) environment at 6.75 GHz and 16.95 GHz using a 1 GHz bandwidth channel sounder. Conducted at the NYU MakerSpace in the NYU Tandon School of Engineering campus in Brooklyn, NY, USA, our measurement campaign characterizes a representative small factory with diverse machinery and open workspaces across 12 locations, comprising 5 line-of-sight (LOS) and 7 non-line-of-sight (NLOS) scenarios. Analysis using the close-in (CI) path loss model with a 1 m reference distance reveals path loss exponents (PLE) below 2 in LOS at 6.75 GHz and 16.95 GHz, while in NLOS PLE is similar to free-space propagation. The RMS delay spread (DS) decreases at higher frequencies with a clear frequency dependence. Similarly, RMS angular spread (AS) measurements show wider spreads in NLOS compared to LOS at both frequency bands, with a decreasing trend as frequency increases. These observations in a dense-scatterer environment demonstrate frequency-dependent behavior that deviate from existing industry-standard models. Our findings provide crucial insights into complex propagation mechanisms in factory environments, essential for designing robust industrial wireless networks at upper mid-band frequencies.
Urban Outdoor Propagation Measurements and Channel Models at 6.75 GHz FR1(C) and 16.95 GHz FR3 Upper Mid-Band Spectrum for 5G and 6G
Oct 24, 2024Global allocations in the upper mid-band spectrum (4-24 GHz) necessitate a comprehensive exploration of the propagation behavior to meet the promise of coverage and capacity. This paper presents an extensive Urban Microcell (UMi) outdoor propagation measurement campaign at 6.75 GHz and 16.95 GHz conducted in Downtown Brooklyn, USA, using a 1 GHz bandwidth sliding correlation channel sounder over 40-880 m propagation distance, encompassing 6 Line of Sight (LOS) and 14 Non-Line of Sight (NLOS) locations. Analysis of the path loss (PL) reveals lower directional and omnidirectional PL exponents compared to mmWave and sub-THz frequencies in the UMi environment, using the close-in PL model with a 1 m reference distance. Additionally, a decreasing trend in root mean square (RMS) delay spread (DS) and angular spread (AS) with increasing frequency was observed. The NLOS RMS DS and RMS AS mean values are obtained consistently lower compared to 3GPP model predictions. Point data for all measured statistics at each TX-RX location are provided to supplement the models and results. The spatio-temporal statistics evaluated here offer valuable insights for the design of next-generation wireless systems and networks.
PuLID: Pure and Lightning ID Customization via Contrastive Alignment
Apr 24, 2024



We propose Pure and Lightning ID customization (PuLID), a novel tuning-free ID customization method for text-to-image generation. By incorporating a Lightning T2I branch with a standard diffusion one, PuLID introduces both contrastive alignment loss and accurate ID loss, minimizing disruption to the original model and ensuring high ID fidelity. Experiments show that PuLID achieves superior performance in both ID fidelity and editability. Another attractive property of PuLID is that the image elements (e.g., background, lighting, composition, and style) before and after the ID insertion are kept as consistent as possible. Codes and models will be available at https://github.com/ToTheBeginning/PuLID
DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Mar 12, 2024



The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively. Our project page is https://tianhao-qi.github.io/DEADiff/.
AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos
Jun 21, 2022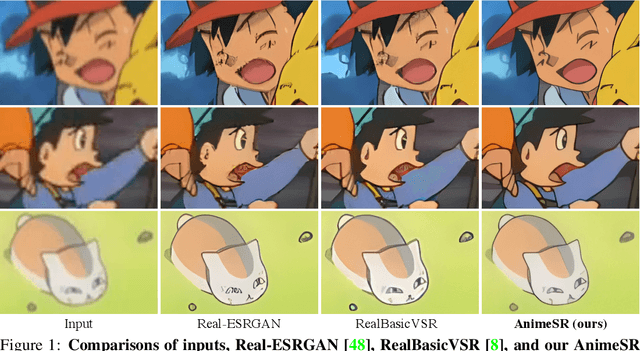

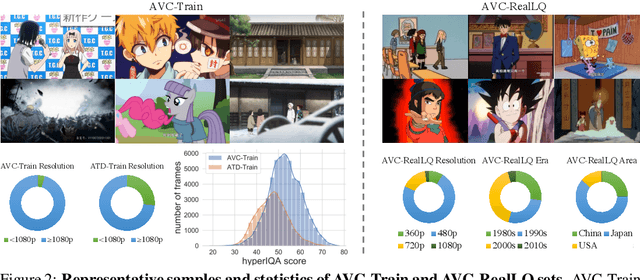
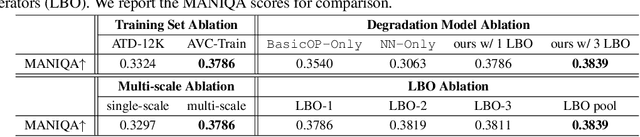
This paper studies the problem of real-world video super-resolution (VSR) for animation videos, and reveals three key improvements for practical animation VSR. First, recent real-world super-resolution approaches typically rely on degradation simulation using basic operators without any learning capability, such as blur, noise, and compression. In this work, we propose to learn such basic operators from real low-quality animation videos, and incorporate the learned ones into the degradation generation pipeline. Such neural-network-based basic operators could help to better capture the distribution of real degradations. Second, a large-scale high-quality animation video dataset, AVC, is built to facilitate comprehensive training and evaluations for animation VSR. Third, we further investigate an efficient multi-scale network structure. It takes advantage of the efficiency of unidirectional recurrent networks and the effectiveness of sliding-window-based methods. Thanks to the above delicate designs, our method, AnimeSR, is capable of restoring real-world low-quality animation videos effectively and efficiently, achieving superior performance to previous state-of-the-art methods.
Metric Learning based Interactive Modulation for Real-World Super-Resolution
May 10, 2022
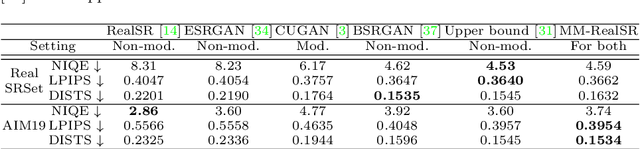
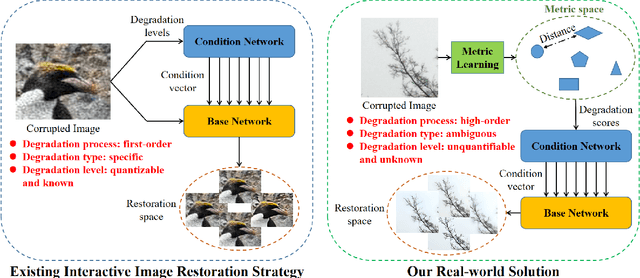

Interactive image restoration aims to restore images by adjusting several controlling coefficients, which determine the restoration strength. Existing methods are restricted in learning the controllable functions under the supervision of known degradation types and levels. They usually suffer from a severe performance drop when the real degradation is different from their assumptions. Such a limitation is due to the complexity of real-world degradations, which can not provide explicit supervision to the interactive modulation during training. However, how to realize the interactive modulation in real-world super-resolution has not yet been studied. In this work, we present a Metric Learning based Interactive Modulation for Real-World Super-Resolution (MM-RealSR). Specifically, we propose an unsupervised degradation estimation strategy to estimate the degradation level in real-world scenarios. Instead of using known degradation levels as explicit supervision to the interactive mechanism, we propose a metric learning strategy to map the unquantifiable degradation levels in real-world scenarios to a metric space, which is trained in an unsupervised manner. Moreover, we introduce an anchor point strategy in the metric learning process to normalize the distribution of metric space. Extensive experiments demonstrate that the proposed MM-RealSR achieves excellent modulation and restoration performance in real-world super-resolution. Codes are available at https://github.com/TencentARC/MM-RealSR.
Towards Vivid and Diverse Image Colorization with Generative Color Prior
Aug 19, 2021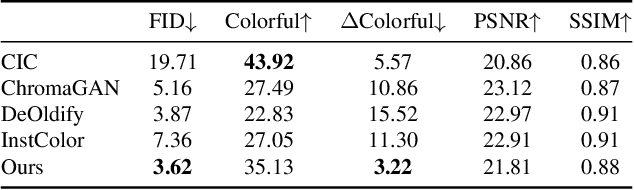
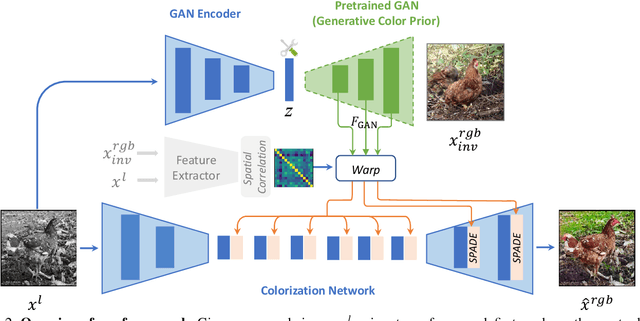


Colorization has attracted increasing interest in recent years. Classic reference-based methods usually rely on external color images for plausible results. A large image database or online search engine is inevitably required for retrieving such exemplars. Recent deep-learning-based methods could automatically colorize images at a low cost. However, unsatisfactory artifacts and incoherent colors are always accompanied. In this work, we aim at recovering vivid colors by leveraging the rich and diverse color priors encapsulated in a pretrained Generative Adversarial Networks (GAN). Specifically, we first "retrieve" matched features (similar to exemplars) via a GAN encoder and then incorporate these features into the colorization process with feature modulations. Thanks to the powerful generative color prior and delicate designs, our method could produce vivid colors with a single forward pass. Moreover, it is highly convenient to obtain diverse results by modifying GAN latent codes. Our method also inherits the merit of interpretable controls of GANs and could attain controllable and smooth transitions by walking through GAN latent space. Extensive experiments and user studies demonstrate that our method achieves superior performance than previous works.