 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch and Customize: A Counterfactual Story Generator
Apr 02, 2021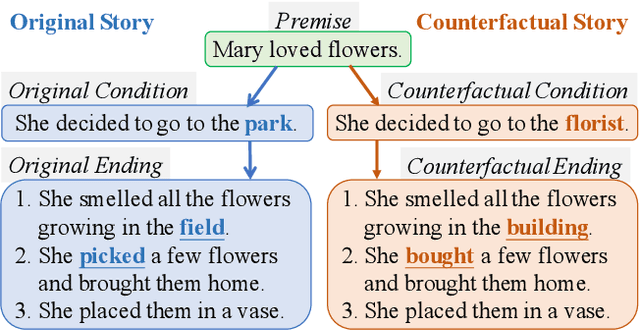
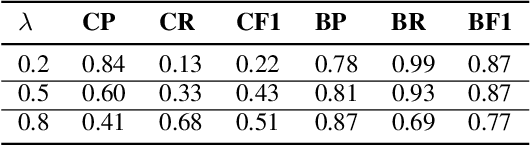
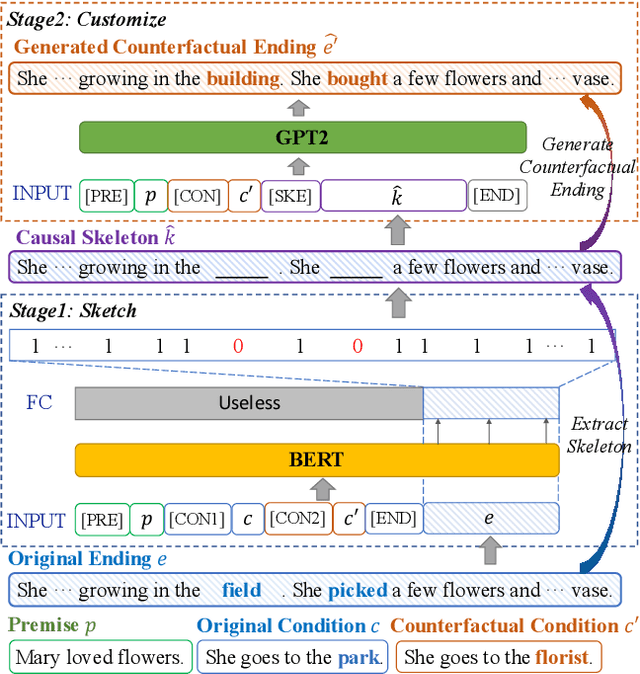
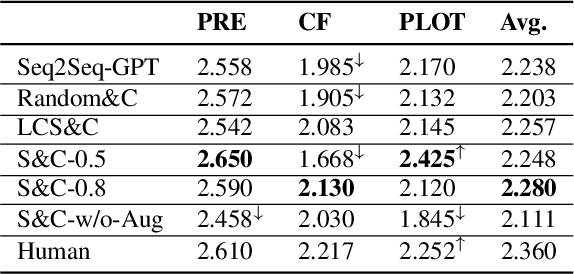
Recent text generation models are easy to generate relevant and fluent text for the given text, while lack of causal reasoning ability when we change some parts of the given text. Counterfactual story rewriting is a recently proposed task to test the causal reasoning ability for text generation models, which requires a model to predict the corresponding story ending when the condition is modified to a counterfactual one. Previous works have shown that the traditional sequence-to-sequence model cannot well handle this problem, as it often captures some spurious correlations between the original and counterfactual endings, instead of the causal relations between conditions and endings. To address this issue, we propose a sketch-and-customize generation model guided by the causality implicated in the conditions and endings. In the sketch stage, a skeleton is extracted by removing words which are conflict to the counterfactual condition, from the original ending. In the customize stage, a generation model is used to fill proper words in the skeleton under the guidance of the counterfactual condition. In this way, the obtained counterfactual ending is both relevant to the original ending and consistent with the counterfactual condition. Experimental results show that the proposed model generates much better endings, as compared with the traditional sequence-to-sequence model.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
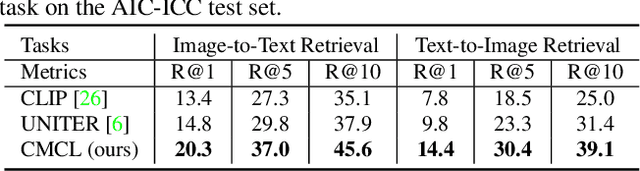
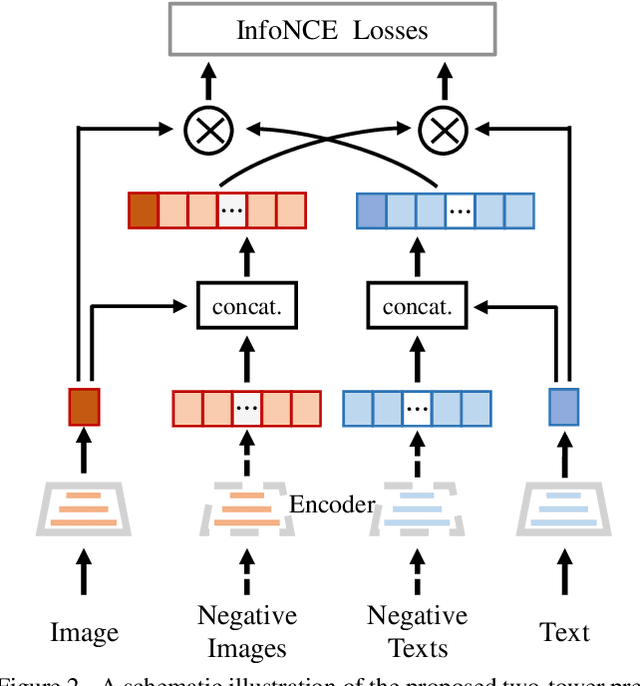
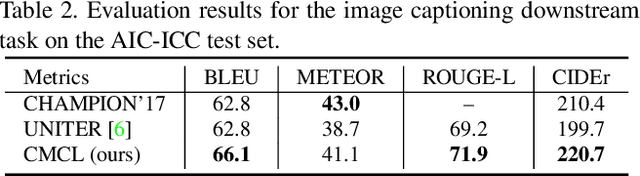
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
Probing Product Description Generation via Posterior Distillation
Mar 02, 2021

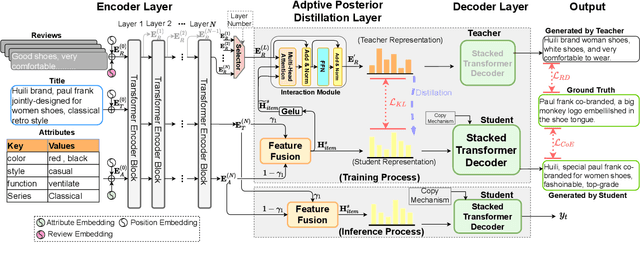

In product description generation (PDG), the user-cared aspect is critical for the recommendation system, which can not only improve user's experiences but also obtain more clicks. High-quality customer reviews can be considered as an ideal source to mine user-cared aspects. However, in reality, a large number of new products (known as long-tailed commodities) cannot gather sufficient amount of customer reviews, which brings a big challenge in the product description generation task. Existing works tend to generate the product description solely based on item information, i.e., product attributes or title words, which leads to tedious contents and cannot attract customers effectively. To tackle this problem, we propose an adaptive posterior network based on Transformer architecture that can utilize user-cared information from customer reviews. Specifically, we first extend the self-attentive Transformer encoder to encode product titles and attributes. Then, we apply an adaptive posterior distillation module to utilize useful review information, which integrates user-cared aspects to the generation process. Finally, we apply a Transformer-based decoding phase with copy mechanism to automatically generate the product description. Besides, we also collect a large-scare Chinese product description dataset to support our work and further research in this field. Experimental results show that our model is superior to traditional generative models in both automatic indicators and human evaluation.
Learning to Truncate Ranked Lists for Information Retrieval
Mar 01, 2021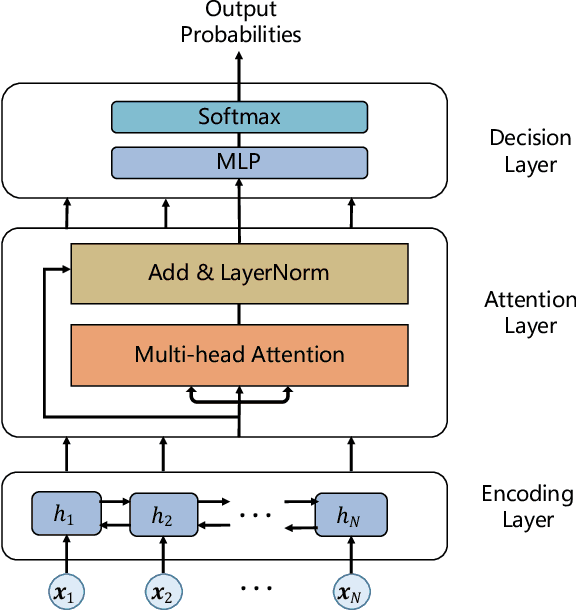

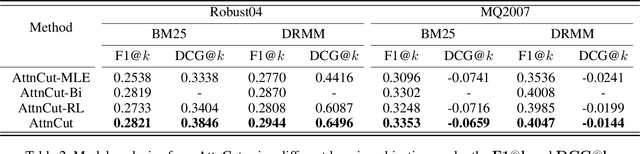
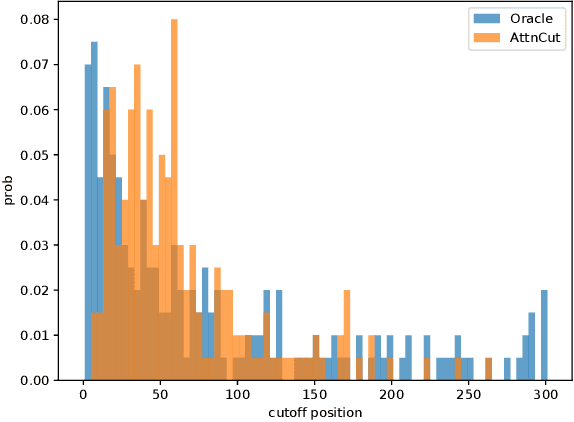
Ranked list truncation is of critical importance in a variety of professional information retrieval applications such as patent search or legal search. The goal is to dynamically determine the number of returned documents according to some user-defined objectives, in order to reach a balance between the overall utility of the results and user efforts. Existing methods formulate this task as a sequential decision problem and take some pre-defined loss as a proxy objective, which suffers from the limitation of local decision and non-direct optimization. In this work, we propose a global decision based truncation model named AttnCut, which directly optimizes user-defined objectives for the ranked list truncation. Specifically, we take the successful transformer architecture to capture the global dependency within the ranked list for truncation decision, and employ the reward augmented maximum likelihood (RAML) for direct optimization. We consider two types of user-defined objectives which are of practical usage. One is the widely adopted metric such as F1 which acts as a balanced objective, and the other is the best F1 under some minimal recall constraint which represents a typical objective in professional search. Empirical results over the Robust04 and MQ2007 datasets demonstrate the effectiveness of our approach as compared with the state-of-the-art baselines.
A Linguistic Study on Relevance Modeling in Information Retrieval
Mar 01, 2021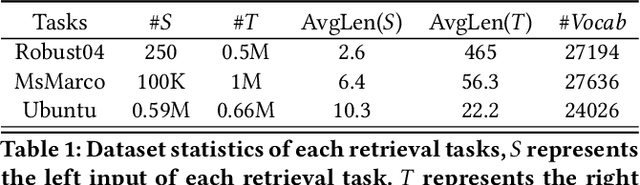
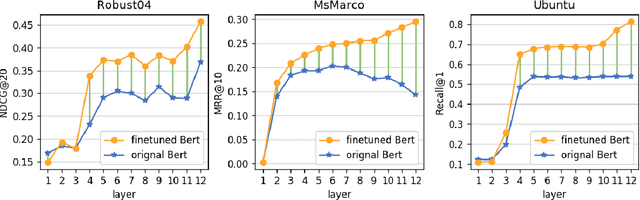
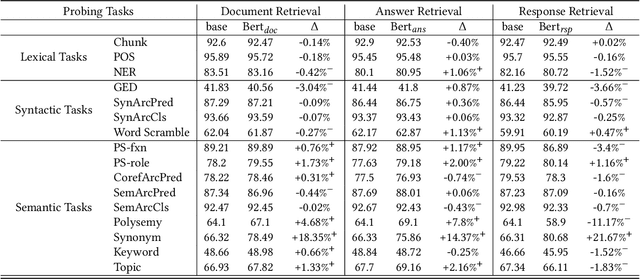
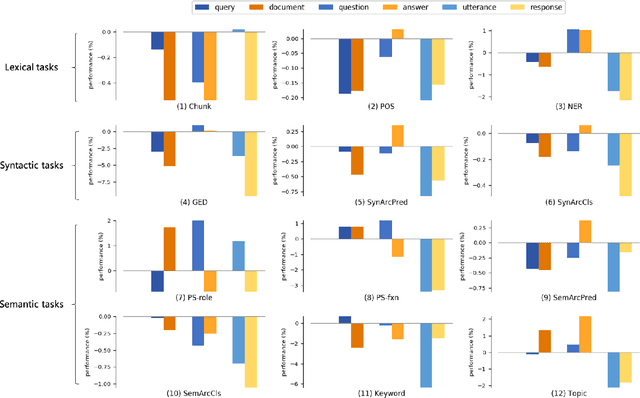
Relevance plays a central role in information retrieval (IR), which has received extensive studies starting from the 20th century. The definition and the modeling of relevance has always been critical challenges in both information science and computer science research areas. Along with the debate and exploration on relevance, IR has already become a core task in many real-world applications, such as Web search engines, question answering systems, conversational bots, and so on. While relevance acts as a unified concept in all these retrieval tasks, the inherent definitions are quite different due to the heterogeneity of these tasks. This raises a question to us: Do these different forms of relevance really lead to different modeling focuses? To answer this question, in this work, we conduct an empirical study on relevance modeling in three representative IR tasks, i.e., document retrieval, answer retrieval, and response retrieval. Specifically, we attempt to study the following two questions: 1) Does relevance modeling in these tasks really show differences in terms of natural language understanding (NLU)? We employ 16 linguistic tasks to probe a unified retrieval model over these three retrieval tasks to answer this question. 2) If there do exist differences, how can we leverage the findings to enhance the relevance modeling? We proposed three intervention methods to investigate how to leverage different modeling focuses of relevance to improve these IR tasks. We believe the way we study the problem as well as our findings would be beneficial to the IR community.
User-Inspired Posterior Network for Recommendation Reason Generation
Feb 16, 2021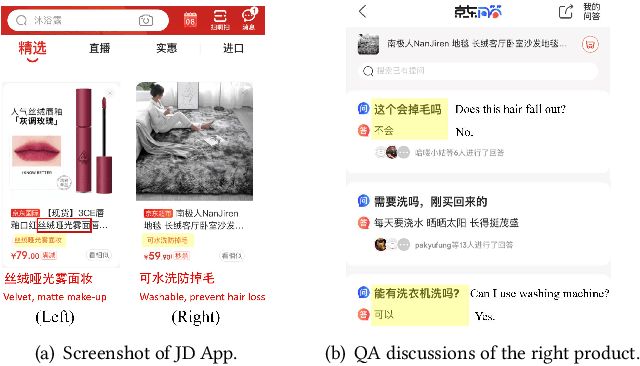
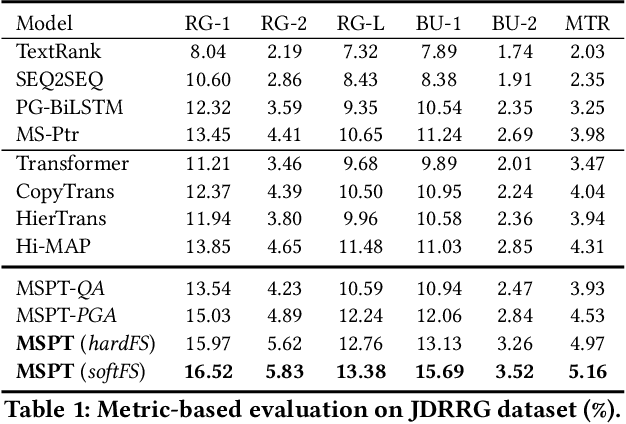
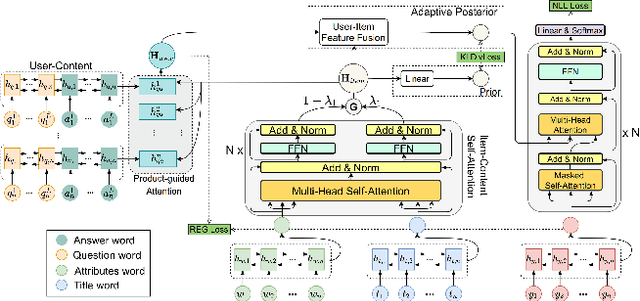
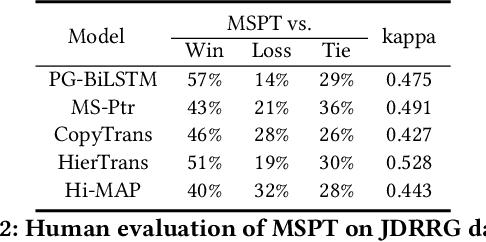
Recommendation reason generation, aiming at showing the selling points of products for customers, plays a vital role in attracting customers' attention as well as improving user experience. A simple and effective way is to extract keywords directly from the knowledge-base of products, i.e., attributes or title, as the recommendation reason. However, generating recommendation reason from product knowledge doesn't naturally respond to users' interests. Fortunately, on some E-commerce websites, there exists more and more user-generated content (user-content for short), i.e., product question-answering (QA) discussions, which reflect user-cared aspects. Therefore, in this paper, we consider generating the recommendation reason by taking into account not only the product attributes but also the customer-generated product QA discussions. In reality, adequate user-content is only possible for the most popular commodities, whereas large sums of long-tail products or new products cannot gather a sufficient number of user-content. To tackle this problem, we propose a user-inspired multi-source posterior transformer (MSPT), which induces the model reflecting the users' interests with a posterior multiple QA discussions module, and generating recommendation reasons containing the product attributes as well as the user-cared aspects. Experimental results show that our model is superior to traditional generative models. Additionally, the analysis also shows that our model can focus more on the user-cared aspects than baselines.
Match-Ignition: Plugging PageRank into Transformer for Long-form Text Matching
Jan 16, 2021
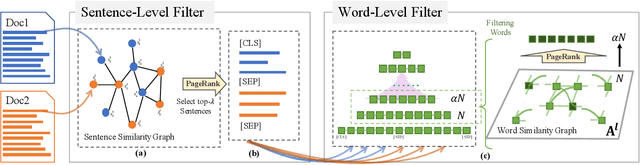
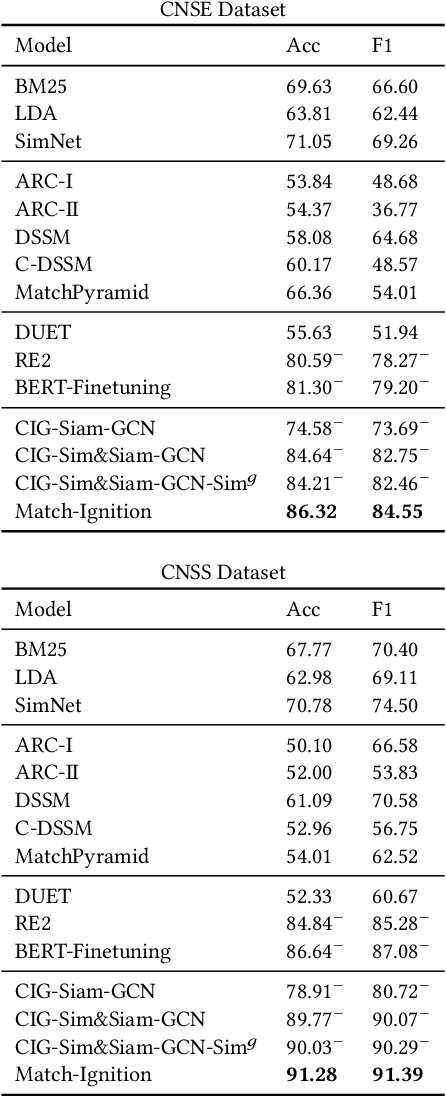
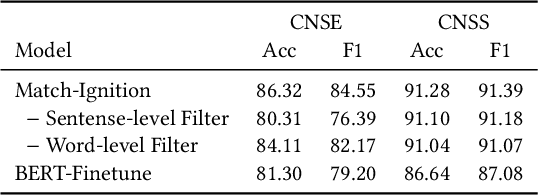
Semantic text matching models have been widely used in community question answering, information retrieval, and dialogue. However, these models cannot well address the long-form text matching problem. That is because there are usually many noises in the setting of long-form text matching, and it is difficult for existing semantic text matching to capture the key matching signals from this noisy information. Besides, these models are computationally expensive because they simply use all textual data indiscriminately in the matching process. To tackle the effectiveness and efficiency problem, we propose a novel hierarchical noise filtering model in this paper, namely Match-Ignition. The basic idea is to plug the well-known PageRank algorithm into the Transformer, to identify and filter both sentence and word level noisy information in the matching process. Noisy sentences are usually easy to detect because the sentence is the basic unit of a long-form text, so we directly use PageRank to filter such information, based on a sentence similarity graph. While words need to rely on their contexts to express concrete meanings, so we propose to jointly learn the filtering process and the matching process, to reflect the contextual dependencies between words. Specifically, a word graph is first built based on the attention scores in each self-attention block of Transformer, and keywords are then selected by applying PageRank on this graph. In this way, noisy words will be filtered out layer by layer in the matching process. Experimental results show that Match-Ignition outperforms both traditional text matching models for short text and recent long-form text matching models. We also conduct detailed analysis to show that Match-Ignition can efficiently capture important sentences or words, which are helpful for long-form text matching.
Dynamic-K Recommendation with Personalized Decision Boundary
Dec 25, 2020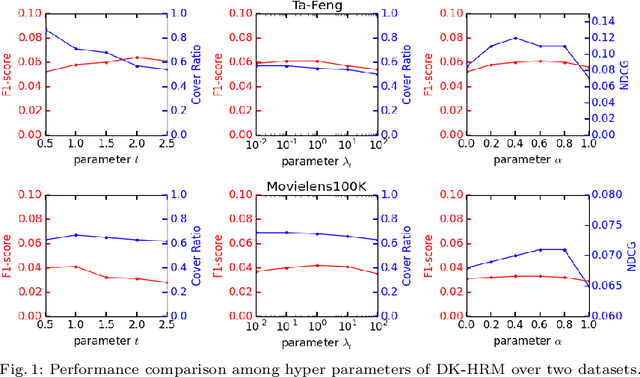
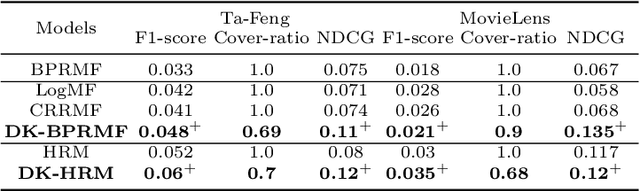
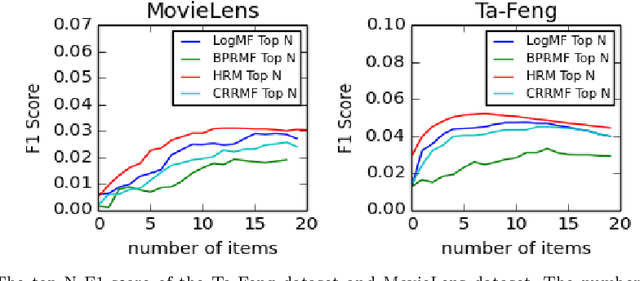
In this paper, we investigate the recommendation task in the most common scenario with implicit feedback (e.g., clicks, purchases). State-of-the-art methods in this direction usually cast the problem as to learn a personalized ranking on a set of items (e.g., webpages, products). The top-N results are then provided to users as recommendations, where the N is usually a fixed number pre-defined by the system according to some heuristic criteria (e.g., page size, screen size). There is one major assumption underlying this fixed-number recommendation scheme, i.e., there are always sufficient relevant items to users' preferences. Unfortunately, this assumption may not always hold in real-world scenarios. In some applications, there might be very limited candidate items to recommend, and some users may have very high relevance requirement in recommendation. In this way, even the top-1 ranked item may not be relevant to a user's preference. Therefore, we argue that it is critical to provide a dynamic-K recommendation, where the K should be different with respect to the candidate item set and the target user. We formulate this dynamic-K recommendation task as a joint learning problem with both ranking and classification objectives. The ranking objective is the same as existing methods, i.e., to create a ranking list of items according to users' interests. The classification objective is unique in this work, which aims to learn a personalized decision boundary to differentiate the relevant items from irrelevant items. Based on these ideas, we extend two state-of-the-art ranking-based recommendation methods, i.e., BPRMF and HRM, to the corresponding dynamic-K versions, namely DK-BPRMF and DK-HRM. Our experimental results on two datasets show that the dynamic-K models are more effective than the original fixed-N recommendation methods.
* 12 pages
Transformation Driven Visual Reasoning
Nov 26, 2020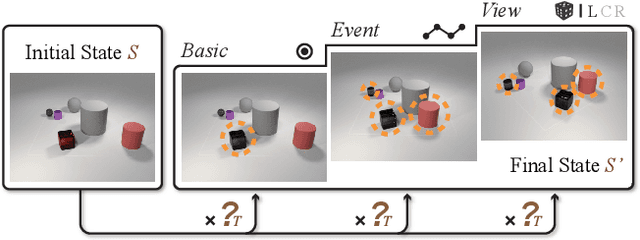
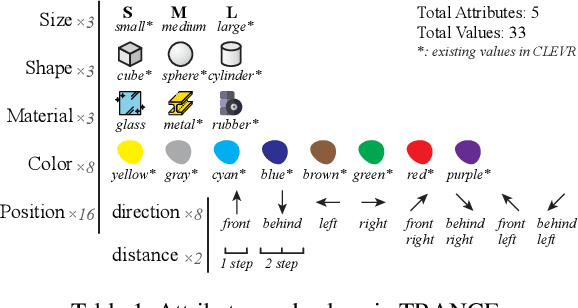
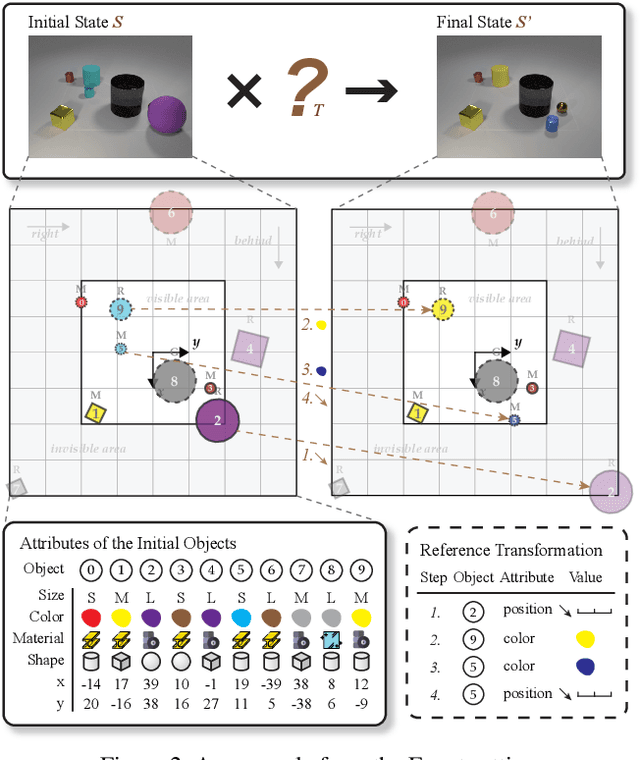
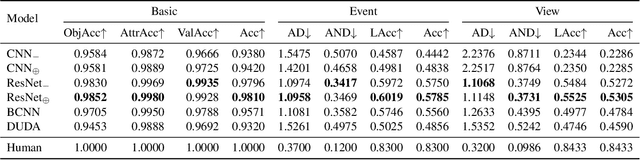
This paper defines a new visual reasoning paradigm by introducing an important factor, i.e., transformation. The motivation comes from the fact that most existing visual reasoning tasks, such as CLEVR in VQA, are solely defined to test how well the machine understands the concepts and relations within static settings, like one image. We argue that this kind of state driven visual reasoning approach has limitations in reflecting whether the machine has the ability to infer the dynamics between different states, which has been shown as important as state-level reasoning for human cognition in Piaget's theory. To tackle this problem, we propose a novel transformation driven visual reasoning task. Given both the initial and final states, the target is to infer the corresponding single-step or multi-step transformation, represented as a triplet (object, attribute, value) or a sequence of triplets, respectively. Following this definition, a new dataset namely TRANCE is constructed on the basis of CLEVR, including three levels of settings, i.e., Basic (single-step transformation), Event (multi-step transformation), and View (multi-step transformation with variant views). Experimental results show that the state-of-the-art visual reasoning models perform well on Basic, but are still far from human-level intelligence on Event and View. We believe the proposed new paradigm will boost the development of machine visual reasoning. More advanced methods and real data need to be investigated in this direction. Code is available at: https://github.com/hughplay/TVR.
Beyond Language: Learning Commonsense from Images for Reasoning
Oct 10, 2020

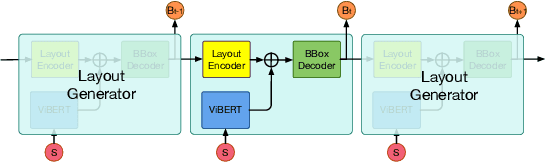
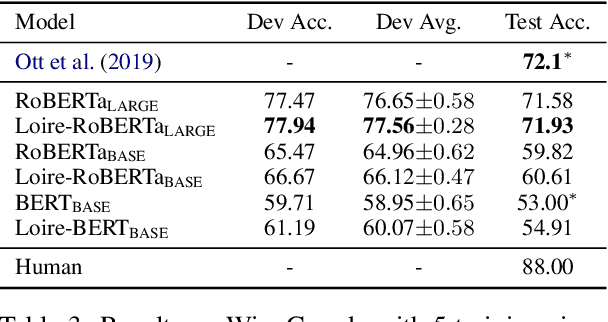
This paper proposes a novel approach to learn commonsense from images, instead of limited raw texts or costly constructed knowledge bases, for the commonsense reasoning problem in NLP. Our motivation comes from the fact that an image is worth a thousand words, where richer scene information could be leveraged to help distill the commonsense knowledge, which is often hidden in languages. Our approach, namely Loire, consists of two stages. In the first stage, a bi-modal sequence-to-sequence approach is utilized to conduct the scene layout generation task, based on a text representation model ViBERT. In this way, the required visual scene knowledge, such as spatial relations, will be encoded in ViBERT by the supervised learning process with some bi-modal data like COCO. Then ViBERT is concatenated with a pre-trained language model to perform the downstream commonsense reasoning tasks. Experimental results on two commonsense reasoning problems, i.e. commonsense question answering and pronoun resolution, demonstrate that Loire outperforms traditional language-based methods. We also give some case studies to show what knowledge is learned from images and explain how the generated scene layout helps the commonsense reasoning process.