 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-based Weight Transfer from Near-field to Far-field Speaker Verification
Mar 15, 2023


The scarcity of labeled far-field speech is a constraint for training superior far-field speaker verification systems. Fine-tuning the model pre-trained on large-scale near-field speech substantially outperforms training from scratch. However, the fine-tuning method suffers from two limitations--catastrophic forgetting and overfitting. In this paper, we propose a weight transfer regularization(WTR) loss to constrain the distance of the weights between the pre-trained model with large-scale near-field speech and the fine-tuned model through a small number of far-field speech. With the WTR loss, the fine-tuning process takes advantage of the previously acquired discriminative ability from the large-scale near-field speech without catastrophic forgetting. Meanwhile, we use the PAC-Bayes generalization theory to analyze the generalization bound of the fine-tuned model with the WTR loss. The analysis result indicates that the WTR term makes the fine-tuned model have a tighter generalization upper bound. Moreover, we explore three kinds of norm distance for weight transfer, which are L1-norm distance, L2-norm distance and Max-norm distance. Finally, we evaluate the effectiveness of the WTR loss on VoxCeleb (pre-trained dataset) and FFSVC (fine-tuned dataset) datasets.
TEA-PSE 3.0: Tencent-Ethereal-Audio-Lab Personalized Speech Enhancement System For ICASSP 2023 DNS Challenge
Mar 14, 2023


This paper introduces the Unbeatable Team's submission to the ICASSP 2023 Deep Noise Suppression (DNS) Challenge. We expand our previous work, TEA-PSE, to its upgraded version -- TEA-PSE 3.0. Specifically, TEA-PSE 3.0 incorporates a residual LSTM after squeezed temporal convolution network (S-TCN) to enhance sequence modeling capabilities. Additionally, the local-global representation (LGR) structure is introduced to boost speaker information extraction, and multi-STFT resolution loss is used to effectively capture the time-frequency characteristics of the speech signals. Moreover, retraining methods are employed based on the freeze training strategy to fine-tune the system. According to the official results, TEA-PSE 3.0 ranks 1st in both ICASSP 2023 DNS-Challenge track 1 and track 2.
Speech Enhancement with Fullband-Subband Cross-Attention Network
Nov 10, 2022FullSubNet has shown its promising performance on speech enhancement by utilizing both fullband and subband information. However, the relationship between fullband and subband in FullSubNet is achieved by simply concatenating the output of fullband model and subband units. It only supplements the subband units with a small quantity of global information and has not considered the interaction between fullband and subband. This paper proposes a fullband-subband cross-attention (FSCA) module to interactively fuse the global and local information and applies it to FullSubNet. This new framework is called as FS-CANet. Moreover, different from FullSubNet, the proposed FS-CANet optimize the fullband extractor by temporal convolutional network (TCN) blocks to further reduce the model size. Experimental results on DNS Challenge - Interspeech 2021 dataset show that the proposed FS-CANet outperforms other state-of-the-art speech enhancement approaches, and demonstrate the effectiveness of fullband-subband cross-attention.
Speech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022



Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.
Local-global speaker representation for target speaker extraction
Oct 28, 2022



Target speaker extraction is to extract the target speaker's voice from a mixture of signals according to the given enrollment utterance. The target speaker's enrollment utterance is also called as anchor speech. The effective utilization of anchor speech is crucial for speaker extraction. In this study, we propose a new system to exploit speaker information from anchor speech fully. Unlike models that use only local or global features of the anchor, the proposed method extracts speaker information on global and local levels and feeds the features into a speech separation network. Our approach benefits from the complementary advantages of both global and local features, and the performance of speaker extraction is improved. We verified the feasibility of this local-global representation (LGR) method using multiple speaker extraction models. Systematic experiments were conducted on the open-source dataset Libri-2talker, and the results showed that the proposed method significantly outperformed the baseline models.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022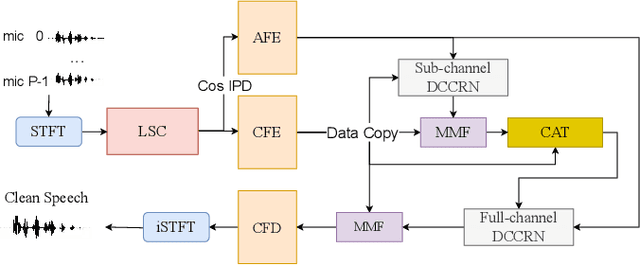
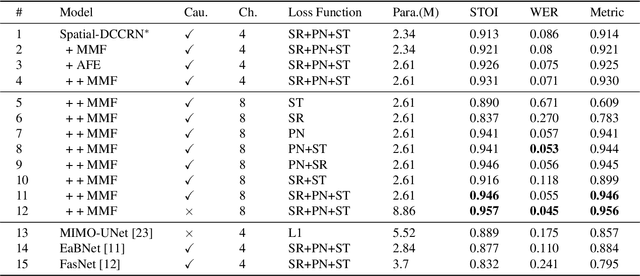
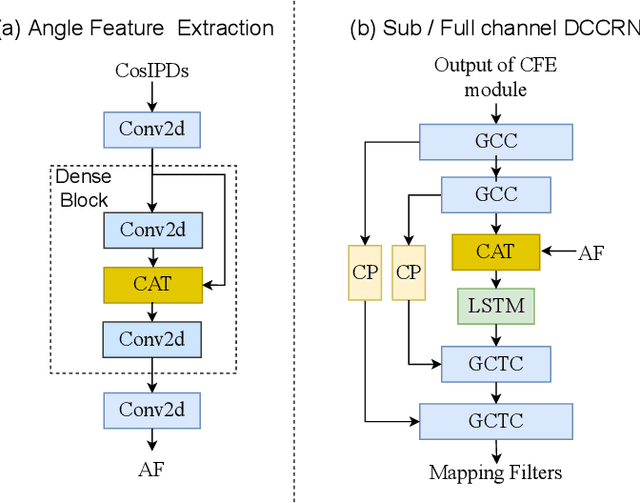
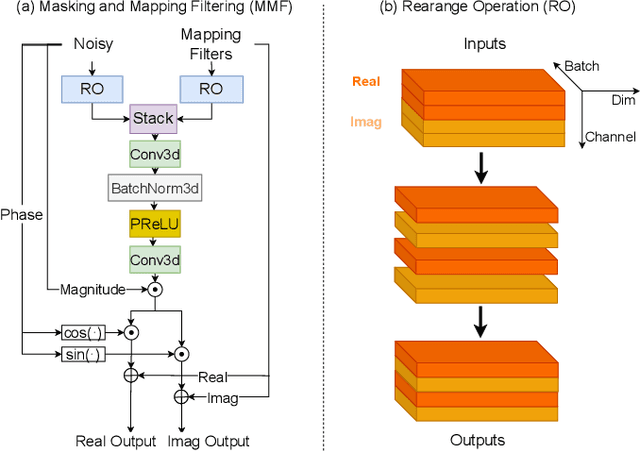
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022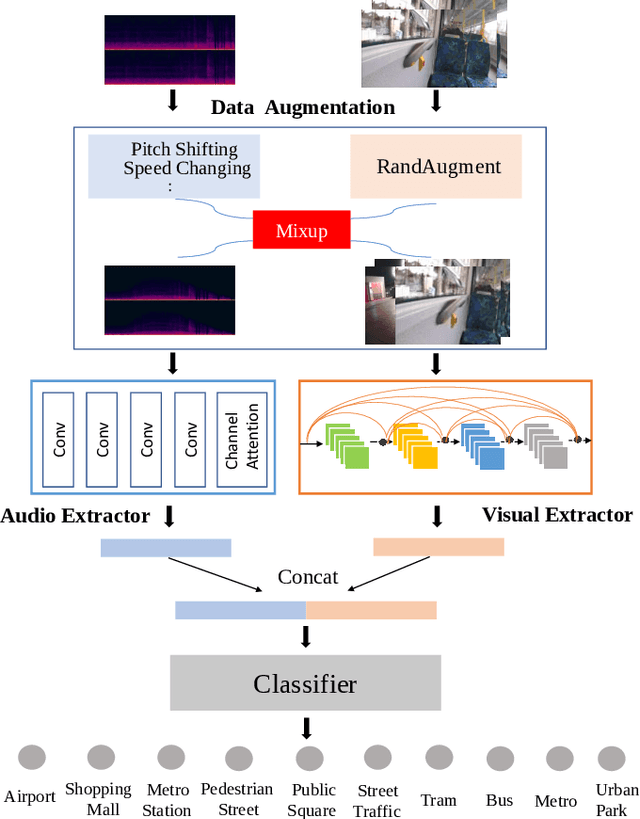
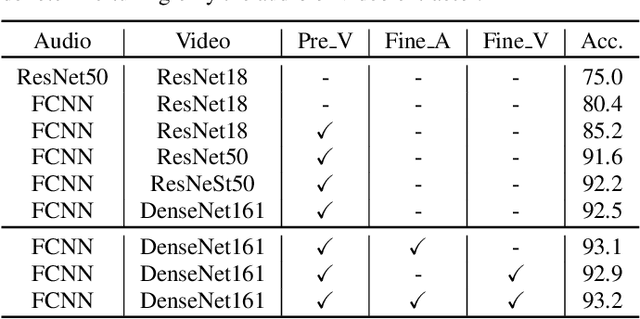
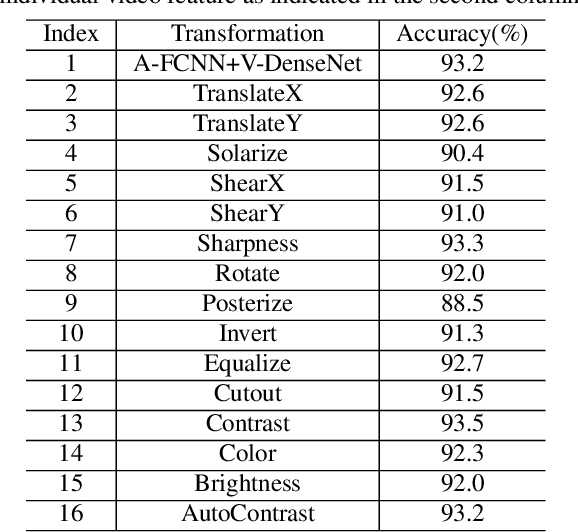
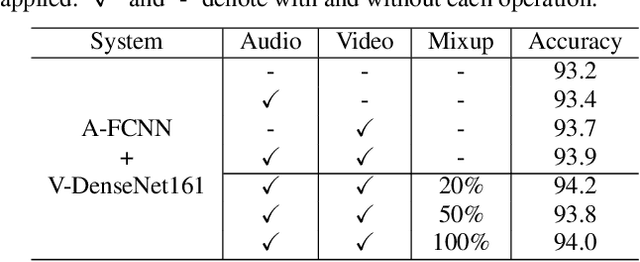
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021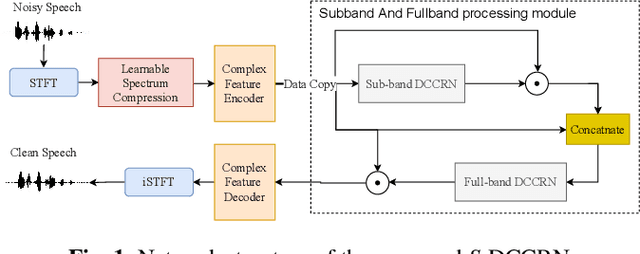
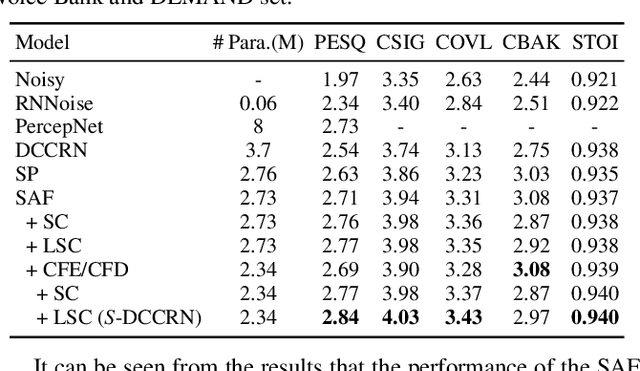
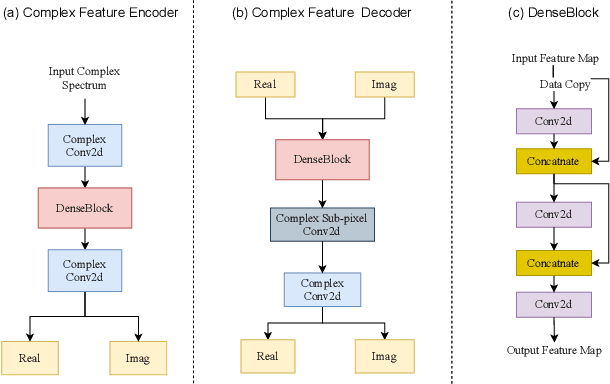
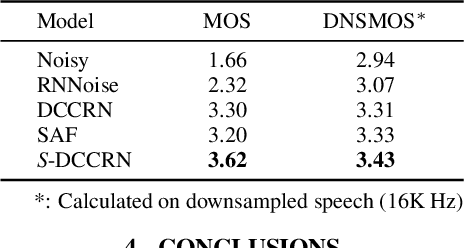
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
A Lottery Ticket Hypothesis Framework for Low-Complexity Device-Robust Neural Acoustic Scene Classification
Jul 03, 2021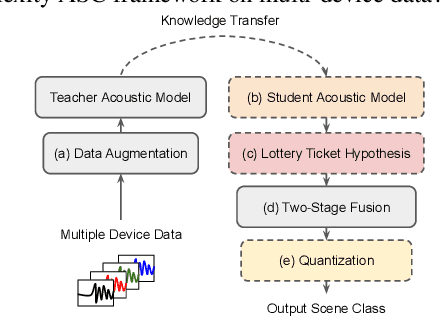
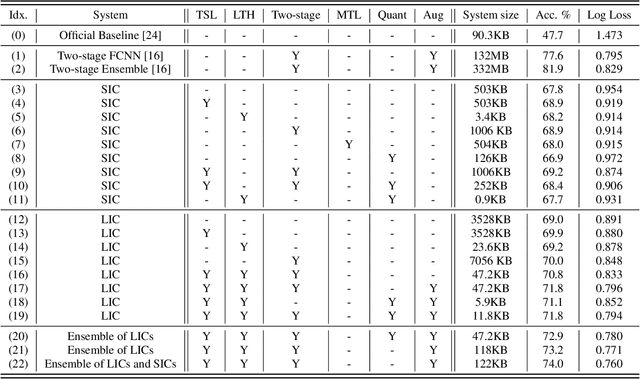
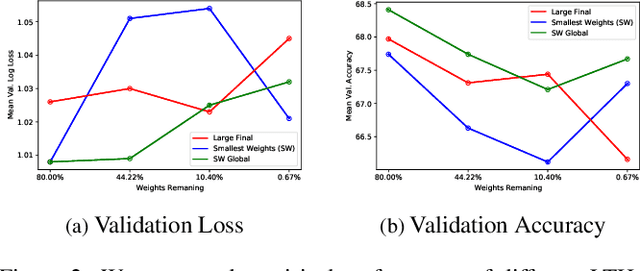

We propose a novel neural model compression strategy combining data augmentation, knowledge transfer, pruning, and quantization for device-robust acoustic scene classification (ASC). Specifically, we tackle the ASC task in a low-resource environment leveraging a recently proposed advanced neural network pruning mechanism, namely Lottery Ticket Hypothesis (LTH), to find a sub-network neural model associated with a small amount non-zero model parameters. The effectiveness of LTH for low-complexity acoustic modeling is assessed by investigating various data augmentation and compression schemes, and we report an efficient joint framework for low-complexity multi-device ASC, called Acoustic Lottery. Acoustic Lottery could compress an ASC model over $1/10^{4}$ and attain a superior performance (validation accuracy of 74.01% and Log loss of 0.76) compared to its not compressed seed model. All results reported in this work are based on a joint effort of four groups, namely GT-USTC-UKE-Tencent, aiming to address the "Low-Complexity Acoustic Scene Classification (ASC) with Multiple Devices" in the DCASE 2021 Challenge Task 1a.
* 5 figures. DCASE 2021. The project started in November 2020
Improving Channel Decorrelation for Multi-Channel Target Speech Extraction
Jun 06, 2021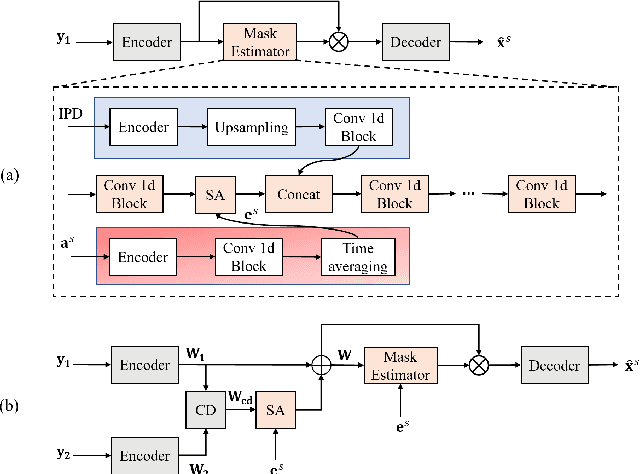
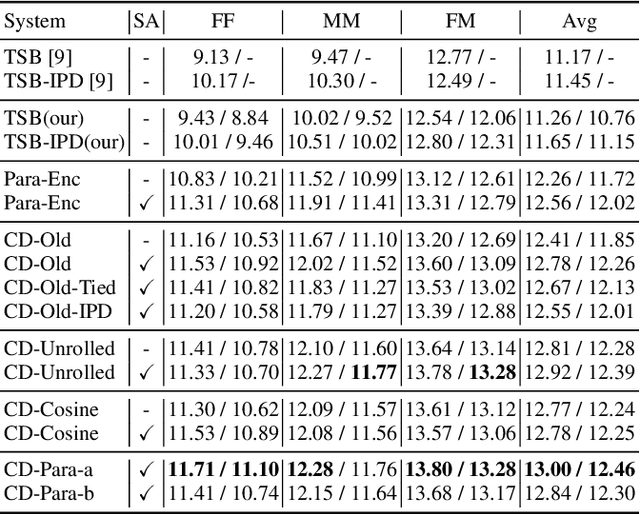
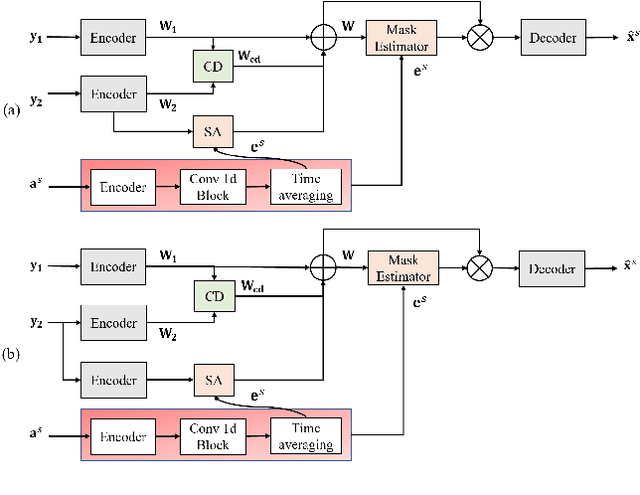
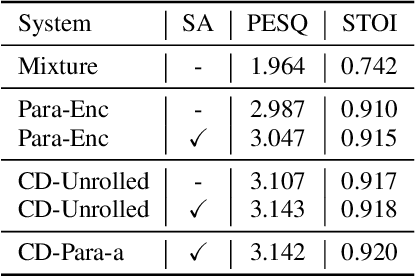
Target speech extraction has attracted widespread attention. When microphone arrays are available, the additional spatial information can be helpful in extracting the target speech. We have recently proposed a channel decorrelation (CD) mechanism to extract the inter-channel differential information to enhance the reference channel encoder representation. Although the proposed mechanism has shown promising results for extracting the target speech from mixtures, the extraction performance is still limited by the nature of the original decorrelation theory. In this paper, we propose two methods to broaden the horizon of the original channel decorrelation, by replacing the original softmax-based inter-channel similarity between encoder representations, using an unrolled probability and a normalized cosine-based similarity at the dimensional-level. Moreover, new combination strategies of the CD-based spatial information and target speaker adaptation of parallel encoder outputs are also investigated. Experiments on the reverberant WSJ0 2-mix show that the improved CD can result in more discriminative differential information and the new adaptation strategy is also very effective to improve the target speech extraction.