 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Optimization for Feature Selection with Permutation-Invariant Embedding and Policy-Guided Search
May 16, 2025Feature selection removes redundant features to enhanc performance and computational efficiency in downstream tasks. Existing works often struggle to capture complex feature interactions and adapt to diverse scenarios. Recent advances in this domain have incorporated generative intelligence to address these drawbacks by uncovering intricate relationships between features. However, two key limitations remain: 1) embedding feature subsets in a continuous space is challenging due to permutation sensitivity, as changes in feature order can introduce biases and weaken the embedding learning process; 2) gradient-based search in the embedding space assumes convexity, which is rarely guaranteed, leading to reduced search effectiveness and suboptimal subsets. To address these limitations, we propose a new framework that can: 1) preserve feature subset knowledge in a continuous embedding space while ensuring permutation invariance; 2) effectively explore the embedding space without relying on strong convex assumptions. For the first objective, we develop an encoder-decoder paradigm to preserve feature selection knowledge into a continuous embedding space. This paradigm captures feature interactions through pairwise relationships within the subset, removing the influence of feature order on the embedding. Moreover, an inducing point mechanism is introduced to accelerate pairwise relationship computations. For the second objective, we employ a policy-based reinforcement learning (RL) approach to guide the exploration of the embedding space. The RL agent effectively navigates the space by balancing multiple objectives. By prioritizing high-potential regions adaptively and eliminating the reliance on convexity assumptions, the RL agent effectively reduces the risk of converging to local optima. Extensive experiments demonstrate the effectiveness, efficiency, robustness and explicitness of our model.
Unsupervised Feature Transformation via In-context Generation, Generator-critic LLM Agents, and Duet-play Teaming
Apr 30, 2025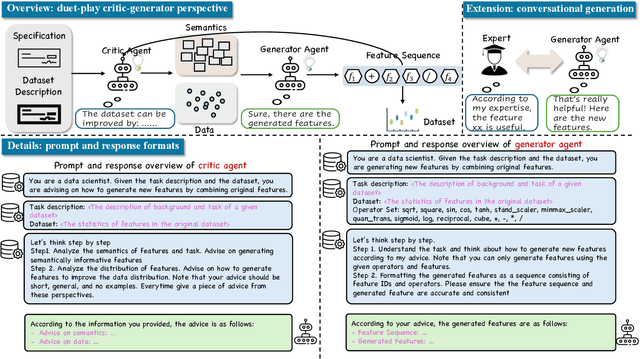
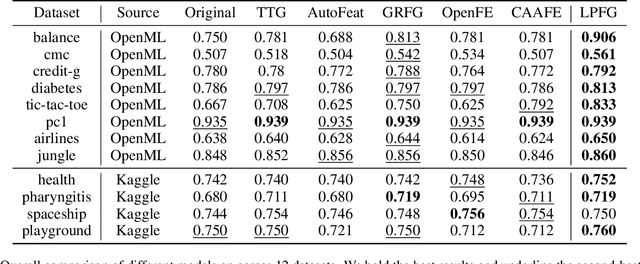


Feature transformation involves generating a new set of features from the original dataset to enhance the data's utility. In certain domains like material performance screening, dimensionality is large and collecting labels is expensive and lengthy. It highly necessitates transforming feature spaces efficiently and without supervision to enhance data readiness and AI utility. However, existing methods fall short in efficient navigation of a vast space of feature combinations, and are mostly designed for supervised settings. To fill this gap, our unique perspective is to leverage a generator-critic duet-play teaming framework using LLM agents and in-context learning to derive pseudo-supervision from unsupervised data. The framework consists of three interconnected steps: (1) Critic agent diagnoses data to generate actionable advice, (2) Generator agent produces tokenized feature transformations guided by the critic's advice, and (3) Iterative refinement ensures continuous improvement through feedback between agents. The generator-critic framework can be generalized to human-agent collaborative generation, by replacing the critic agent with human experts. Extensive experiments demonstrate that the proposed framework outperforms even supervised baselines in feature transformation efficiency, robustness, and practical applicability across diverse datasets.
NAPER: Fault Protection for Real-Time Resource-Constrained Deep Neural Networks
Apr 09, 2025



Fault tolerance in Deep Neural Networks (DNNs) deployed on resource-constrained systems presents unique challenges for high-accuracy applications with strict timing requirements. Memory bit-flips can severely degrade DNN accuracy, while traditional protection approaches like Triple Modular Redundancy (TMR) often sacrifice accuracy to maintain reliability, creating a three-way dilemma between reliability, accuracy, and timeliness. We introduce NAPER, a novel protection approach that addresses this challenge through ensemble learning. Unlike conventional redundancy methods, NAPER employs heterogeneous model redundancy, where diverse models collectively achieve higher accuracy than any individual model. This is complemented by an efficient fault detection mechanism and a real-time scheduler that prioritizes meeting deadlines by intelligently scheduling recovery operations without interrupting inference. Our evaluations demonstrate NAPER's superiority: 40% faster inference in both normal and fault conditions, maintained accuracy 4.2% higher than TMR-based strategies, and guaranteed uninterrupted operation even during fault recovery. NAPER effectively balances the competing demands of accuracy, reliability, and timeliness in real-time DNN applications
FastFT: Accelerating Reinforced Feature Transformation via Advanced Exploration Strategies
Mar 26, 2025



Feature Transformation is crucial for classic machine learning that aims to generate feature combinations to enhance the performance of downstream tasks from a data-centric perspective. Current methodologies, such as manual expert-driven processes, iterative-feedback techniques, and exploration-generative tactics, have shown promise in automating such data engineering workflow by minimizing human involvement. However, three challenges remain in those frameworks: (1) It predominantly depends on downstream task performance metrics, as assessment is time-consuming, especially for large datasets. (2) The diversity of feature combinations will hardly be guaranteed after random exploration ends. (3) Rare significant transformations lead to sparse valuable feedback that hinders the learning processes or leads to less effective results. In response to these challenges, we introduce FastFT, an innovative framework that leverages a trio of advanced strategies.We first decouple the feature transformation evaluation from the outcomes of the generated datasets via the performance predictor. To address the issue of reward sparsity, we developed a method to evaluate the novelty of generated transformation sequences. Incorporating this novelty into the reward function accelerates the model's exploration of effective transformations, thereby improving the search productivity. Additionally, we combine novelty and performance to create a prioritized memory buffer, ensuring that essential experiences are effectively revisited during exploration. Our extensive experimental evaluations validate the performance, efficiency, and traceability of our proposed framework, showcasing its superiority in handling complex feature transformation tasks.
A Survey on Data-Centric AI: Tabular Learning from Reinforcement Learning and Generative AI Perspective
Feb 12, 2025


Tabular data is one of the most widely used data formats across various domains such as bioinformatics, healthcare, and marketing. As artificial intelligence moves towards a data-centric perspective, improving data quality is essential for enhancing model performance in tabular data-driven applications. This survey focuses on data-driven tabular data optimization, specifically exploring reinforcement learning (RL) and generative approaches for feature selection and feature generation as fundamental techniques for refining data spaces. Feature selection aims to identify and retain the most informative attributes, while feature generation constructs new features to better capture complex data patterns. We systematically review existing generative methods for tabular data engineering, analyzing their latest advancements, real-world applications, and respective strengths and limitations. This survey emphasizes how RL-based and generative techniques contribute to the automation and intelligence of feature engineering. Finally, we summarize the existing challenges and discuss future research directions, aiming to provide insights that drive continued innovation in this field.
LEKA:LLM-Enhanced Knowledge Augmentation
Jan 29, 2025



Humans excel in analogical learning and knowledge transfer and, more importantly, possess a unique understanding of identifying appropriate sources of knowledge. From a model's perspective, this presents an interesting challenge. If models could autonomously retrieve knowledge useful for transfer or decision-making to solve problems, they would transition from passively acquiring to actively accessing and learning from knowledge. However, filling models with knowledge is relatively straightforward -- it simply requires more training and accessible knowledge bases. The more complex task is teaching models about which knowledge can be analogized and transferred. Therefore, we design a knowledge augmentation method LEKA for knowledge transfer that actively searches for suitable knowledge sources that can enrich the target domain's knowledge. This LEKA method extracts key information from textual information from the target domain, retrieves pertinent data from external data libraries, and harmonizes retrieved data with the target domain data in feature space and marginal probability measures. We validate the effectiveness of our approach through extensive experiments across various domains and demonstrate significant improvements over traditional methods in reducing computational costs, automating data alignment, and optimizing transfer learning outcomes.
Iterative Feature Space Optimization through Incremental Adaptive Evaluation
Jan 24, 2025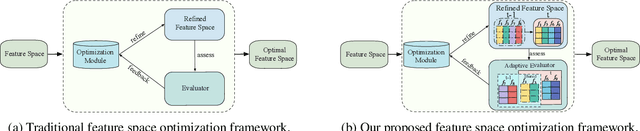
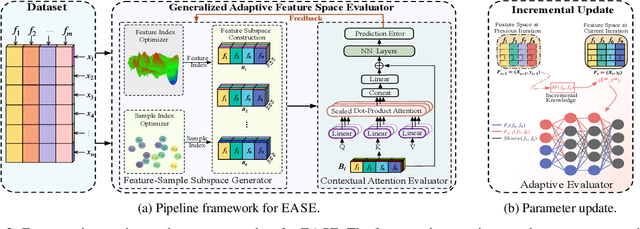
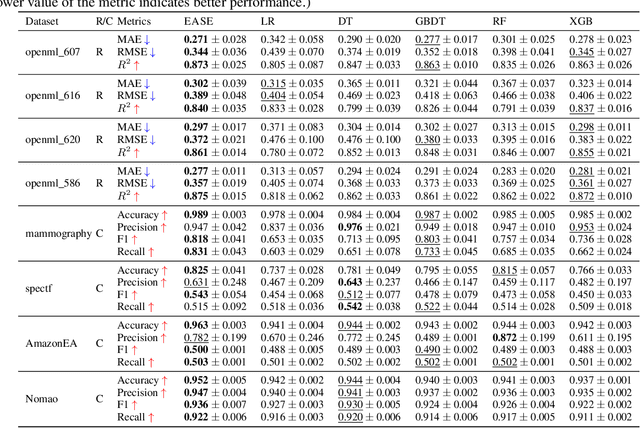
Iterative feature space optimization involves systematically evaluating and adjusting the feature space to improve downstream task performance. However, existing works suffer from three key limitations:1) overlooking differences among data samples leads to evaluation bias; 2) tailoring feature spaces to specific machine learning models results in overfitting and poor generalization; 3) requiring the evaluator to be retrained from scratch during each optimization iteration significantly reduces the overall efficiency of the optimization process. To bridge these gaps, we propose a gEneralized Adaptive feature Space Evaluator (EASE) to efficiently produce optimal and generalized feature spaces. This framework consists of two key components: Feature-Sample Subspace Generator and Contextual Attention Evaluator. The first component aims to decouple the information distribution within the feature space to mitigate evaluation bias. To achieve this, we first identify features most relevant to prediction tasks and samples most challenging for evaluation based on feedback from the subsequent evaluator. This decoupling strategy makes the evaluator consistently target the most challenging aspects of the feature space. The second component intends to incrementally capture evolving patterns of the feature space for efficient evaluation. We propose a weighted-sharing multi-head attention mechanism to encode key characteristics of the feature space into an embedding vector for evaluation. Moreover, the evaluator is updated incrementally, retaining prior evaluation knowledge while incorporating new insights, as consecutive feature spaces during the optimization process share partial information. Extensive experiments on fourteen real-world datasets demonstrate the effectiveness of the proposed framework. Our code and data are publicly available.
Towards Data-Centric AI: A Comprehensive Survey of Traditional, Reinforcement, and Generative Approaches for Tabular Data Transformation
Jan 17, 2025



Tabular data is one of the most widely used formats across industries, driving critical applications in areas such as finance, healthcare, and marketing. In the era of data-centric AI, improving data quality and representation has become essential for enhancing model performance, particularly in applications centered around tabular data. This survey examines the key aspects of tabular data-centric AI, emphasizing feature selection and feature generation as essential techniques for data space refinement. We provide a systematic review of feature selection methods, which identify and retain the most relevant data attributes, and feature generation approaches, which create new features to simplify the capture of complex data patterns. This survey offers a comprehensive overview of current methodologies through an analysis of recent advancements, practical applications, and the strengths and limitations of these techniques. Finally, we outline open challenges and suggest future perspectives to inspire continued innovation in this field.
Topology-aware Reinforcement Feature Space Reconstruction for Graph Data
Nov 08, 2024



Feature space is an environment where data points are vectorized to represent the original dataset. Reconstructing a good feature space is essential to augment the AI power of data, improve model generalization, and increase the availability of downstream ML models. Existing literature, such as feature transformation and feature selection, is labor-intensive (e.g., heavy reliance on empirical experience) and mostly designed for tabular data. Moreover, these methods regard data samples as independent, which ignores the unique topological structure when applied to graph data, thus resulting in a suboptimal reconstruction feature space. Can we consider the topological information to automatically reconstruct feature space for graph data without heavy experiential knowledge? To fill this gap, we leverage topology-aware reinforcement learning to automate and optimize feature space reconstruction for graph data. Our approach combines the extraction of core subgraphs to capture essential structural information with a graph neural network (GNN) to encode topological features and reduce computing complexity. Then we introduce three reinforcement agents within a hierarchical structure to systematically generate meaningful features through an iterative process, effectively reconstructing the feature space. This framework provides a principled solution for attributed graph feature space reconstruction. The extensive experiments demonstrate the effectiveness and efficiency of including topological awareness.
Make Graph Neural Networks Great Again: A Generic Integration Paradigm of Topology-Free Patterns for Traffic Speed Prediction
Jun 24, 2024



Urban traffic speed prediction aims to estimate the future traffic speed for improving urban transportation services. Enormous efforts have been made to exploit Graph Neural Networks (GNNs) for modeling spatial correlations and temporal dependencies of traffic speed evolving patterns, regularized by graph topology.While achieving promising results, current traffic speed prediction methods still suffer from ignoring topology-free patterns, which cannot be captured by GNNs. To tackle this challenge, we propose a generic model for enabling the current GNN-based methods to preserve topology-free patterns. Specifically, we first develop a Dual Cross-Scale Transformer (DCST) architecture, including a Spatial Transformer and a Temporal Transformer, to preserve the cross-scale topology-free patterns and associated dynamics, respectively. Then, to further integrate both topology-regularized/-free patterns, we propose a distillation-style learning framework, in which the existing GNN-based methods are considered as the teacher model, and the proposed DCST architecture is considered as the student model. The teacher model would inject the learned topology-regularized patterns into the student model for integrating topology-free patterns. The extensive experimental results demonstrated the effectiveness of our methods.