 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-based Fast Gradient Rescaling Method for Highly Transferable Adversarial Attacks
Jul 06, 2023Deep neural networks are known to be vulnerable to adversarial examples crafted by adding human-imperceptible perturbations to the benign input. After achieving nearly 100% attack success rates in white-box setting, more focus is shifted to black-box attacks, of which the transferability of adversarial examples has gained significant attention. In either case, the common gradient-based methods generally use the sign function to generate perturbations on the gradient update, that offers a roughly correct direction and has gained great success. But little work pays attention to its possible limitation. In this work, we observe that the deviation between the original gradient and the generated noise may lead to inaccurate gradient update estimation and suboptimal solutions for adversarial transferability. To this end, we propose a Sampling-based Fast Gradient Rescaling Method (S-FGRM). Specifically, we use data rescaling to substitute the sign function without extra computational cost. We further propose a Depth First Sampling method to eliminate the fluctuation of rescaling and stabilize the gradient update. Our method could be used in any gradient-based attacks and is extensible to be integrated with various input transformation or ensemble methods to further improve the adversarial transferability. Extensive experiments on the standard ImageNet dataset show that our method could significantly boost the transferability of gradient-based attacks and outperform the state-of-the-art baselines.
Robust Backdoor Attack with Visible, Semantic, Sample-Specific, and Compatible Triggers
Jun 01, 2023Deep neural networks (DNNs) can be manipulated to exhibit specific behaviors when exposed to specific trigger patterns, without affecting their performance on normal samples. This type of attack is known as a backdoor attack. Recent research has focused on designing invisible triggers for backdoor attacks to ensure visual stealthiness. These triggers have demonstrated strong attack performance even under backdoor defense, which aims to eliminate or suppress the backdoor effect in the model. However, through experimental observations, we have noticed that these carefully designed invisible triggers are often susceptible to visual distortion during inference, such as Gaussian blurring or environmental variations in real-world scenarios. This phenomenon significantly undermines the effectiveness of attacks in practical applications. Unfortunately, this issue has not received sufficient attention and has not been thoroughly investigated. To address this limitation, we propose a novel approach called the Visible, Semantic, Sample-Specific, and Compatible trigger (VSSC-trigger), which leverages a recent powerful image method known as the stable diffusion model. In this approach, a text trigger is utilized as a prompt and combined with a benign image. The resulting combination is then processed by a pre-trained stable diffusion model, generating a corresponding semantic object. This object is seamlessly integrated with the original image, resulting in a new realistic image, referred to as the poisoned image. Extensive experimental results and analysis validate the effectiveness and robustness of our proposed attack method, even in the presence of visual distortion. We believe that the new trigger proposed in this work, along with the proposed idea to address the aforementioned issues, will have significant prospective implications for further advancements in this direction.
UCF: Uncovering Common Features for Generalizable Deepfake Detection
Apr 27, 2023



Deepfake detection remains a challenging task due to the difficulty of generalizing to new types of forgeries. This problem primarily stems from the overfitting of existing detection methods to forgery-irrelevant features and method-specific patterns. The latter is often ignored by previous works. This paper presents a novel approach to address the two types of overfitting issues by uncovering common forgery features. Specifically, we first propose a disentanglement framework that decomposes image information into three distinct components: forgery-irrelevant, method-specific forgery, and common forgery features. To ensure the decoupling of method-specific and common forgery features, a multi-task learning strategy is employed, including a multi-class classification that predicts the category of the forgery method and a binary classification that distinguishes the real from the fake. Additionally, a conditional decoder is designed to utilize forgery features as a condition along with forgery-irrelevant features to generate reconstructed images. Furthermore, a contrastive regularization technique is proposed to encourage the disentanglement of the common and specific forgery features. Ultimately, we only utilize the common forgery features for the purpose of generalizable deepfake detection. Extensive evaluations demonstrate that our framework can perform superior generalization than current state-of-the-art methods.
Enhancing Fine-Tuning Based Backdoor Defense with Sharpness-Aware Minimization
Apr 24, 2023



Backdoor defense, which aims to detect or mitigate the effect of malicious triggers introduced by attackers, is becoming increasingly critical for machine learning security and integrity. Fine-tuning based on benign data is a natural defense to erase the backdoor effect in a backdoored model. However, recent studies show that, given limited benign data, vanilla fine-tuning has poor defense performance. In this work, we provide a deep study of fine-tuning the backdoored model from the neuron perspective and find that backdoorrelated neurons fail to escape the local minimum in the fine-tuning process. Inspired by observing that the backdoorrelated neurons often have larger norms, we propose FTSAM, a novel backdoor defense paradigm that aims to shrink the norms of backdoor-related neurons by incorporating sharpness-aware minimization with fine-tuning. We demonstrate the effectiveness of our method on several benchmark datasets and network architectures, where it achieves state-of-the-art defense performance. Overall, our work provides a promising avenue for improving the robustness of machine learning models against backdoor attacks.
DPE: Disentanglement of Pose and Expression for General Video Portrait Editing
Jan 16, 2023One-shot video-driven talking face generation aims at producing a synthetic talking video by transferring the facial motion from a video to an arbitrary portrait image. Head pose and facial expression are always entangled in facial motion and transferred simultaneously. However, the entanglement sets up a barrier for these methods to be used in video portrait editing directly, where it may require to modify the expression only while maintaining the pose unchanged. One challenge of decoupling pose and expression is the lack of paired data, such as the same pose but different expressions. Only a few methods attempt to tackle this challenge with the feat of 3D Morphable Models (3DMMs) for explicit disentanglement. But 3DMMs are not accurate enough to capture facial details due to the limited number of Blenshapes, which has side effects on motion transfer. In this paper, we introduce a novel self-supervised disentanglement framework to decouple pose and expression without 3DMMs and paired data, which consists of a motion editing module, a pose generator, and an expression generator. The editing module projects faces into a latent space where pose motion and expression motion can be disentangled, and the pose or expression transfer can be performed in the latent space conveniently via addition. The two generators render the modified latent codes to images, respectively. Moreover, to guarantee the disentanglement, we propose a bidirectional cyclic training strategy with well-designed constraints. Evaluations demonstrate our method can control pose or expression independently and be used for general video editing.
Generalizable Black-Box Adversarial Attack with Meta Learning
Jan 01, 2023In the scenario of black-box adversarial attack, the target model's parameters are unknown, and the attacker aims to find a successful adversarial perturbation based on query feedback under a query budget. Due to the limited feedback information, existing query-based black-box attack methods often require many queries for attacking each benign example. To reduce query cost, we propose to utilize the feedback information across historical attacks, dubbed example-level adversarial transferability. Specifically, by treating the attack on each benign example as one task, we develop a meta-learning framework by training a meta-generator to produce perturbations conditioned on benign examples. When attacking a new benign example, the meta generator can be quickly fine-tuned based on the feedback information of the new task as well as a few historical attacks to produce effective perturbations. Moreover, since the meta-train procedure consumes many queries to learn a generalizable generator, we utilize model-level adversarial transferability to train the meta-generator on a white-box surrogate model, then transfer it to help the attack against the target model. The proposed framework with the two types of adversarial transferability can be naturally combined with any off-the-shelf query-based attack methods to boost their performance, which is verified by extensive experiments.
3D GAN Inversion with Facial Symmetry Prior
Nov 30, 2022Recently, a surge of high-quality 3D-aware GANs have been proposed, which leverage the generative power of neural rendering. It is natural to associate 3D GANs with GAN inversion methods to project a real image into the generator's latent space, allowing free-view consistent synthesis and editing, referred as 3D GAN inversion. Although with the facial prior preserved in pre-trained 3D GANs, reconstructing a 3D portrait with only one monocular image is still an ill-pose problem. The straightforward application of 2D GAN inversion methods focuses on texture similarity only while ignoring the correctness of 3D geometry shapes. It may raise geometry collapse effects, especially when reconstructing a side face under an extreme pose. Besides, the synthetic results in novel views are prone to be blurry. In this work, we propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior. We design a pipeline and constraints to make full use of the pseudo auxiliary view obtained via image flipping, which helps obtain a robust and reasonable geometry shape during the inversion process. To enhance texture fidelity in unobserved viewpoints, pseudo labels from depth-guided 3D warping can provide extra supervision. We design constraints aimed at filtering out conflict areas for optimization in asymmetric situations. Comprehensive quantitative and qualitative evaluations on image reconstruction and editing demonstrate the superiority of our method.
High-fidelity Facial Avatar Reconstruction from Monocular Video with Generative Priors
Nov 28, 2022High-fidelity facial avatar reconstruction from a monocular video is a significant research problem in computer graphics and computer vision. Recently, Neural Radiance Field (NeRF) has shown impressive novel view rendering results and has been considered for facial avatar reconstruction. However, the complex facial dynamics and missing 3D information in monocular videos raise significant challenges for faithful facial reconstruction. In this work, we propose a new method for NeRF-based facial avatar reconstruction that utilizes 3D-aware generative prior. Different from existing works that depend on a conditional deformation field for dynamic modeling, we propose to learn a personalized generative prior, which is formulated as a local and low dimensional subspace in the latent space of 3D-GAN. We propose an efficient method to construct the personalized generative prior based on a small set of facial images of a given individual. After learning, it allows for photo-realistic rendering with novel views and the face reenactment can be realized by performing navigation in the latent space. Our proposed method is applicable for different driven signals, including RGB images, 3DMM coefficients, and audios. Compared with existing works, we obtain superior novel view synthesis results and faithfully face reenactment performance.
Adversarial Rademacher Complexity of Deep Neural Networks
Nov 27, 2022



Deep neural networks are vulnerable to adversarial attacks. Ideally, a robust model shall perform well on both the perturbed training data and the unseen perturbed test data. It is found empirically that fitting perturbed training data is not hard, but generalizing to perturbed test data is quite difficult. To better understand adversarial generalization, it is of great interest to study the adversarial Rademacher complexity (ARC) of deep neural networks. However, how to bound ARC in multi-layers cases is largely unclear due to the difficulty of analyzing adversarial loss in the definition of ARC. There have been two types of attempts of ARC. One is to provide the upper bound of ARC in linear and one-hidden layer cases. However, these approaches seem hard to extend to multi-layer cases. Another is to modify the adversarial loss and provide upper bounds of Rademacher complexity on such surrogate loss in multi-layer cases. However, such variants of Rademacher complexity are not guaranteed to be bounds for meaningful robust generalization gaps (RGG). In this paper, we provide a solution to this unsolved problem. Specifically, we provide the first bound of adversarial Rademacher complexity of deep neural networks. Our approach is based on covering numbers. We provide a method to handle the robustify function classes of DNNs such that we can calculate the covering numbers. Finally, we provide experiments to study the empirical implication of our bounds and provide an analysis of poor adversarial generalization.
Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
Oct 12, 2022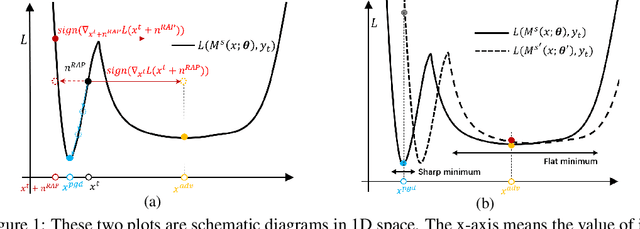
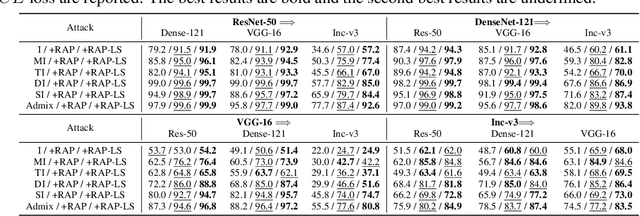
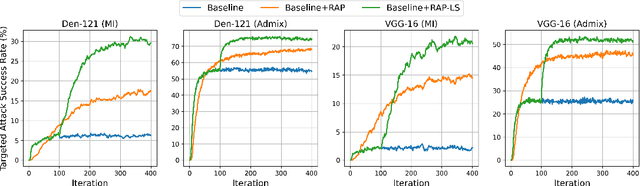
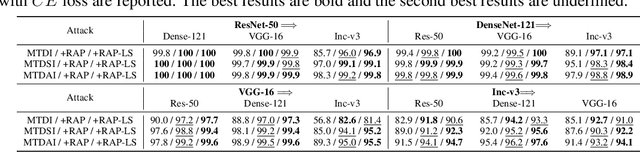
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples, which can produce erroneous predictions by injecting imperceptible perturbations. In this work, we study the transferability of adversarial examples, which is significant due to its threat to real-world applications where model architecture or parameters are usually unknown. Many existing works reveal that the adversarial examples are likely to overfit the surrogate model that they are generated from, limiting its transfer attack performance against different target models. To mitigate the overfitting of the surrogate model, we propose a novel attack method, dubbed reverse adversarial perturbation (RAP). Specifically, instead of minimizing the loss of a single adversarial point, we advocate seeking adversarial example located at a region with unified low loss value, by injecting the worst-case perturbation (the reverse adversarial perturbation) for each step of the optimization procedure. The adversarial attack with RAP is formulated as a min-max bi-level optimization problem. By integrating RAP into the iterative process for attacks, our method can find more stable adversarial examples which are less sensitive to the changes of decision boundary, mitigating the overfitting of the surrogate model. Comprehensive experimental comparisons demonstrate that RAP can significantly boost adversarial transferability. Furthermore, RAP can be naturally combined with many existing black-box attack techniques, to further boost the transferability. When attacking a real-world image recognition system, Google Cloud Vision API, we obtain 22% performance improvement of targeted attacks over the compared method. Our codes are available at https://github.com/SCLBD/Transfer_attack_RAP.