 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Memory Recursive Least Squares: Uniformly Allocated Approximation Capabilities of RBF Neural Networks in Real-Time Learning
Nov 15, 2022



When performing real-time learning tasks, the radial basis function neural network (RBFNN) is expected to make full use of the training samples such that its learning accuracy and generalization capability are guaranteed. Since the approximation capability of the RBFNN is finite, training methods with forgetting mechanisms such as the forgetting factor recursive least squares (FFRLS) and stochastic gradient descent (SGD) methods are widely used to maintain the learning ability of the RBFNN to new knowledge. However, with the forgetting mechanisms, some useful knowledge will get lost simply because they are learned a long time ago, which we refer to as the passive knowledge forgetting phenomenon. To address this problem, this paper proposes a real-time training method named selective memory recursive least squares (SMRLS) in which the feature space of the RBFNN is evenly discretized into a finite number of partitions and a synthesized objective function is developed to replace the original objective function of the ordinary recursive least squares (RLS) method. SMRLS is featured with a memorization mechanism that synthesizes the samples within each partition in real-time into representative samples uniformly distributed over the feature space, and thus overcomes the passive knowledge forgetting phenomenon and improves the generalization capability of the learned knowledge. Compared with the SGD or FFRLS methods, SMRLS achieves improved learning performance (learning speed, accuracy and generalization capability), which is demonstrated by corresponding simulation results.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022



Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Alleviating the Sample Selection Bias in Few-shot Learning by Removing Projection to the Centroid
Oct 30, 2022



Few-shot learning (FSL) targets at generalization of vision models towards unseen tasks without sufficient annotations. Despite the emergence of a number of few-shot learning methods, the sample selection bias problem, i.e., the sensitivity to the limited amount of support data, has not been well understood. In this paper, we find that this problem usually occurs when the positions of support samples are in the vicinity of task centroid -- the mean of all class centroids in the task. This motivates us to propose an extremely simple feature transformation to alleviate this problem, dubbed Task Centroid Projection Removing (TCPR). TCPR is applied directly to all image features in a given task, aiming at removing the dimension of features along the direction of the task centroid. While the exact task centroid cannot be accurately obtained from limited data, we estimate it using base features that are each similar to one of the support features. Our method effectively prevents features from being too close to the task centroid. Extensive experiments over ten datasets from different domains show that TCPR can reliably improve classification accuracy across various feature extractors, training algorithms and datasets. The code has been made available at https://github.com/KikimorMay/FSL-TCBR.
Q-Net: Query-Informed Few-Shot Medical Image Segmentation
Aug 24, 2022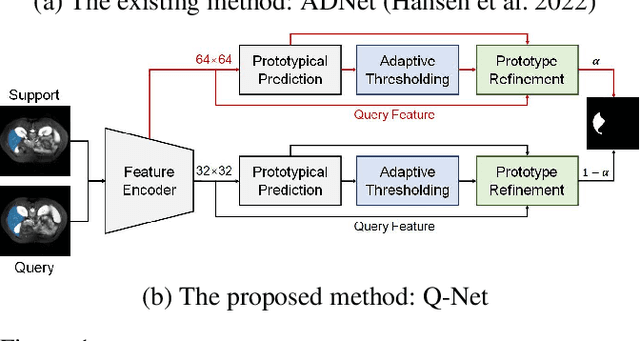
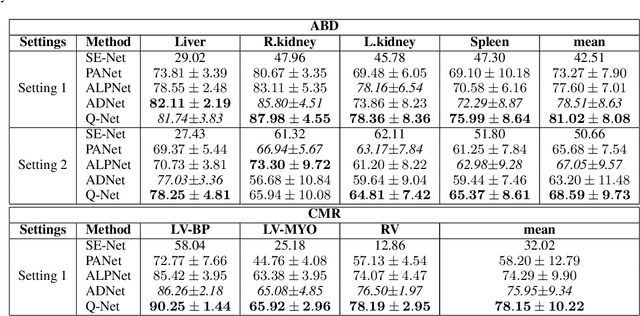
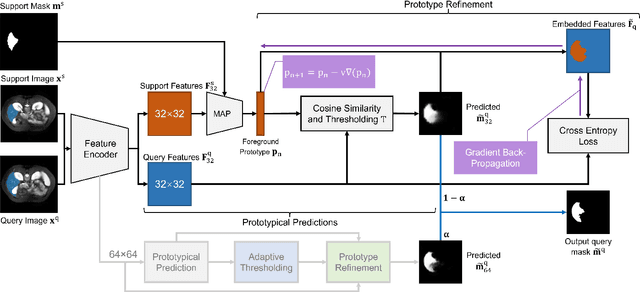
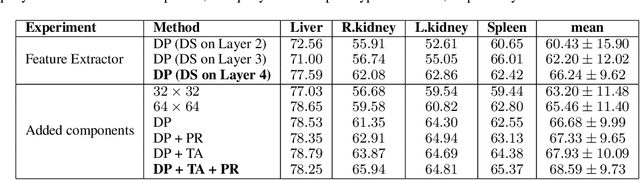
Deep learning has achieved tremendous success in computer vision, while medical image segmentation (MIS) remains a challenge, due to the scarcity of data annotations. Meta-learning techniques for few-shot segmentation (Meta-FSS) have been widely used to tackle this challenge, while they neglect possible distribution shifts between the query image and the support set. In contrast, an experienced clinician can perceive and address such shifts by borrowing information from the query image, then fine-tune or calibrate his (her) prior cognitive model accordingly. Inspired by this, we propose Q-Net, a Query-informed Meta-FSS approach, which mimics in spirit the learning mechanism of an expert clinician. We build Q-Net based on ADNet, a recently proposed anomaly detection-inspired method. Specifically, we add two query-informed computation modules into ADNet, namely a query-informed threshold adaptation module and a query-informed prototype refinement module. Combining them with a dual-path extension of the feature extraction module, Q-Net achieves state-of-the-art performance on two widely used datasets, which are composed of abdominal MR images and cardiac MR images, respectively. Our work sheds light on a novel way to improve Meta-FSS techniques by leveraging query information.
Towards Efficient and Stable K-Asynchronous Federated Learning with Unbounded Stale Gradients on Non-IID Data
Mar 02, 2022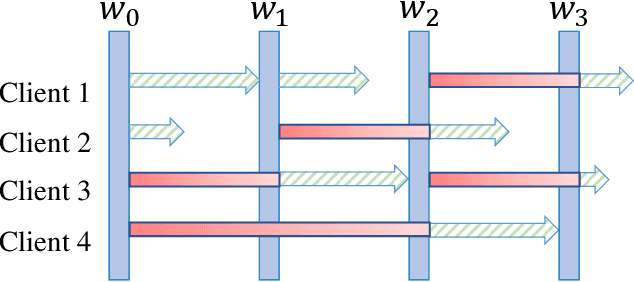

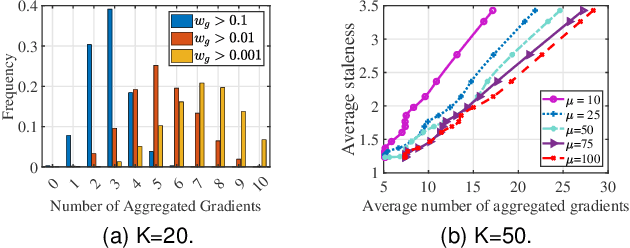
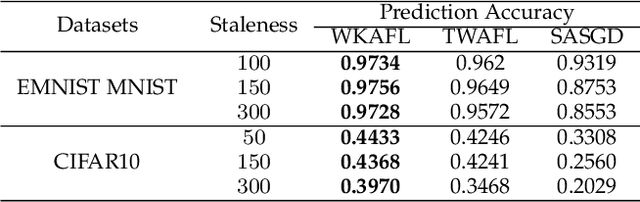
Federated learning (FL) is an emerging privacy-preserving paradigm that enables multiple participants collaboratively to train a global model without uploading raw data. Considering heterogeneous computing and communication capabilities of different participants, asynchronous FL can avoid the stragglers effect in synchronous FL and adapts to scenarios with vast participants. Both staleness and non-IID data in asynchronous FL would reduce the model utility. However, there exists an inherent contradiction between the solutions to the two problems. That is, mitigating the staleness requires to select less but consistent gradients while coping with non-IID data demands more comprehensive gradients. To address the dilemma, this paper proposes a two-stage weighted $K$ asynchronous FL with adaptive learning rate (WKAFL). By selecting consistent gradients and adjusting learning rate adaptively, WKAFL utilizes stale gradients and mitigates the impact of non-IID data, which can achieve multifaceted enhancement in training speed, prediction accuracy and training stability. We also present the convergence analysis for WKAFL under the assumption of unbounded staleness to understand the impact of staleness and non-IID data. Experiments implemented on both benchmark and synthetic FL datasets show that WKAFL has better overall performance compared to existing algorithms.
Dual Path Structural Contrastive Embeddings for Learning Novel Objects
Jan 04, 2022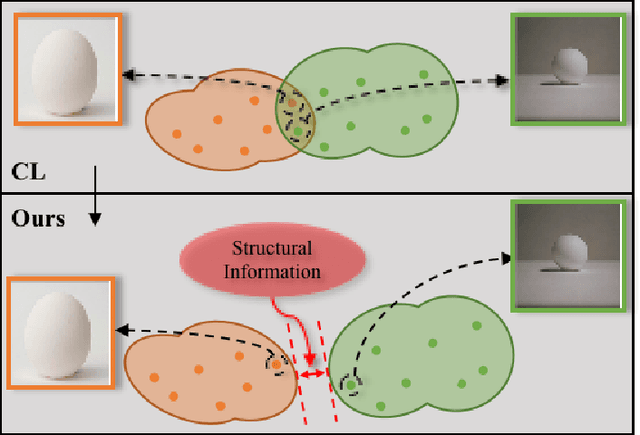
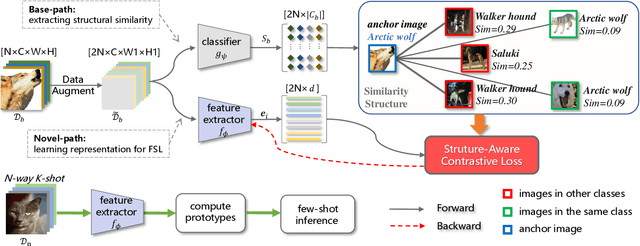
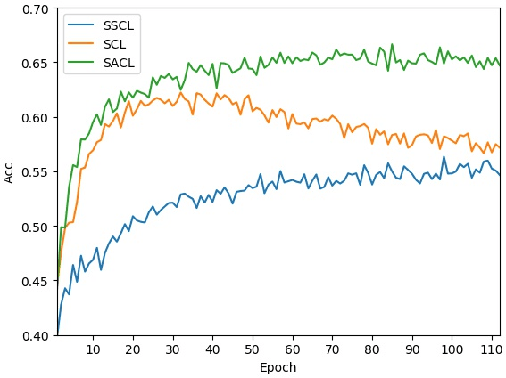

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
Class-Incremental Few-Shot Object Detection
May 17, 2021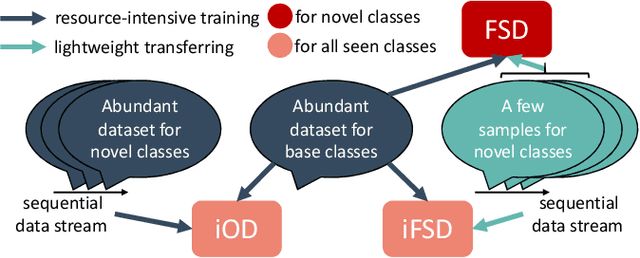
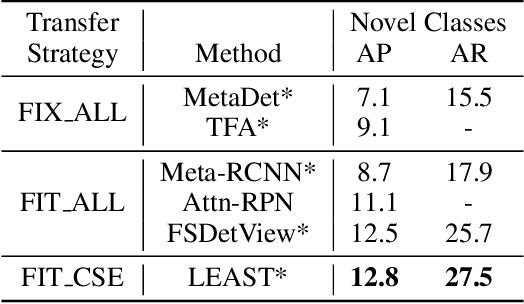
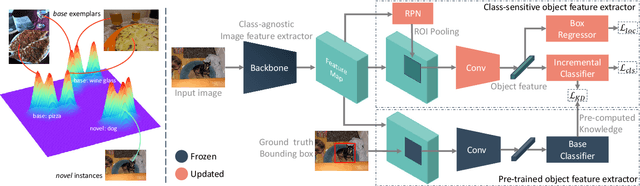
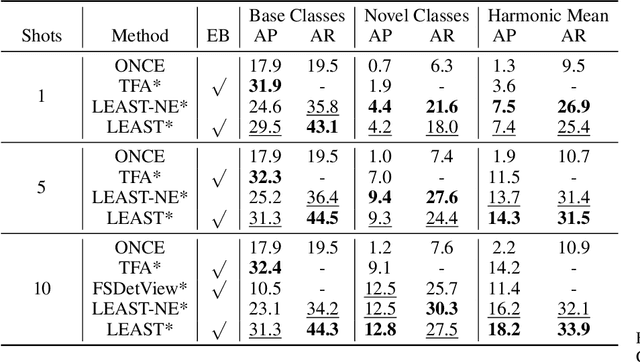
Conventional detection networks usually need abundant labeled training samples, while humans can learn new concepts incrementally with just a few examples. This paper focuses on a more challenging but realistic class-incremental few-shot object detection problem (iFSD). It aims to incrementally transfer the model for novel objects from only a few annotated samples without catastrophically forgetting the previously learned ones. To tackle this problem, we propose a novel method LEAST, which can transfer with Less forgetting, fEwer training resources, And Stronger Transfer capability. Specifically, we first present the transfer strategy to reduce unnecessary weight adaptation and improve the transfer capability for iFSD. On this basis, we then integrate the knowledge distillation technique using a less resource-consuming approach to alleviate forgetting and propose a novel clustering-based exemplar selection process to preserve more discriminative features previously learned. Being a generic and effective method, LEAST can largely improve the iFSD performance on various benchmarks.
Improving Tracking through Human-Robot Sensory Augmentation
Feb 17, 2020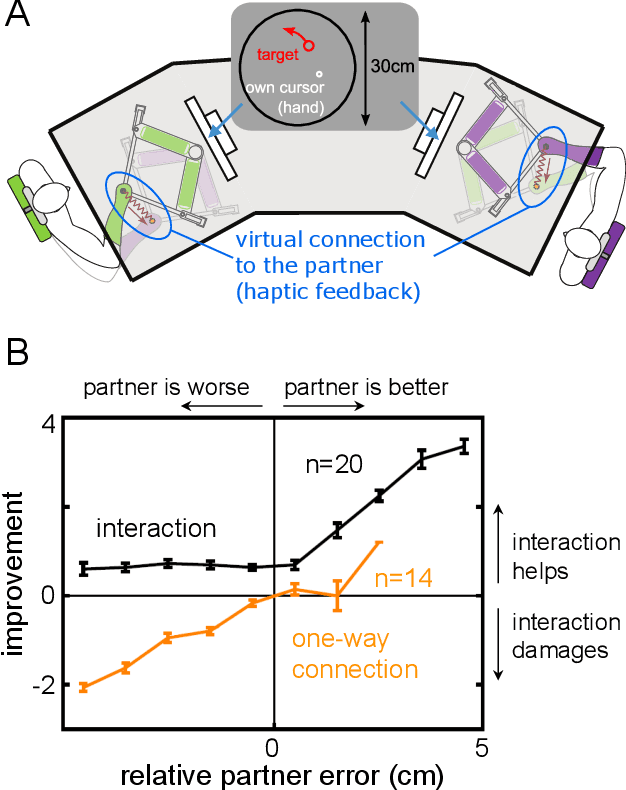
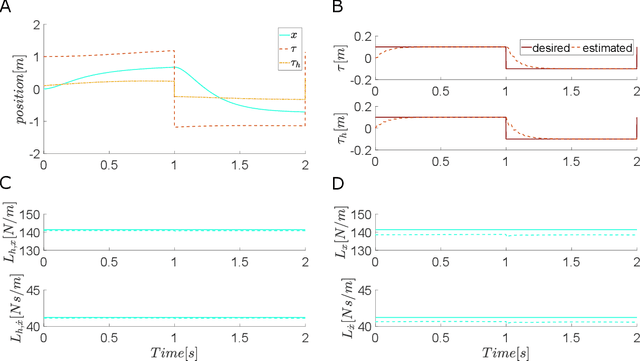
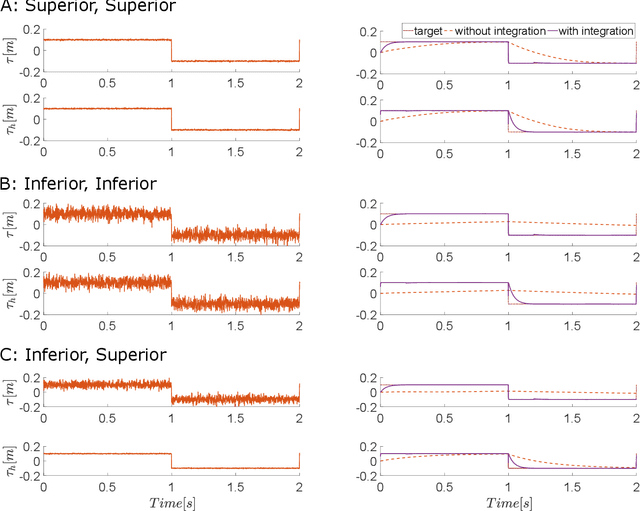
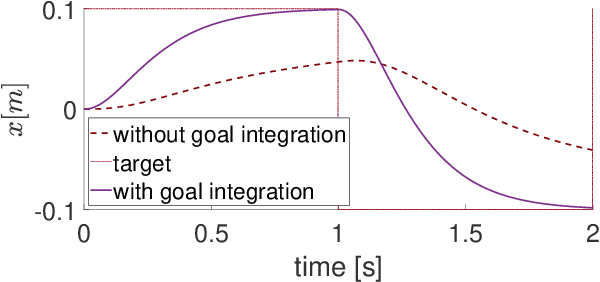
This paper introduces human-robot sensory augmentation and illustrates it on a tracking task, where performance can be improved by the exchange of sensory information between the robot and its human user. It was recently found that during interaction between humans, the partners use each other's sensory information to improve their own sensing, thus also their performance and learning. In this paper, we develop a computational model of this unique human ability, and use it to build a novel control framework for human-robot interaction. The human partner's control is formulated as a feedback control with unknown control gains and desired trajectory. A Kalman filter is used to estimate first the control gains and then the desired trajectory. The estimated human partner's desired trajectory is used as augmented sensory information about the system and combined with the robot's measurement to estimate an uncertain target trajectory. Simulations and an implementation of the presented framework on a robotic interface validate the proposed observer-predictor pair for a tracking task. The results obtained using this robot demonstrate how the human user's control can be identified, and exhibit similar benefits of this sensory augmentation as was observed between interacting humans.
Asynchronous Federated Learning with Differential Privacy for Edge Intelligence
Dec 17, 2019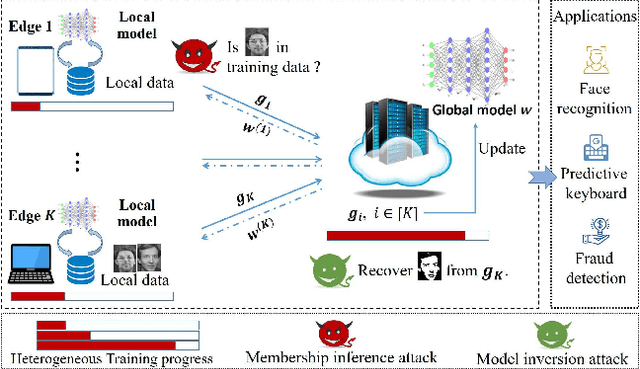

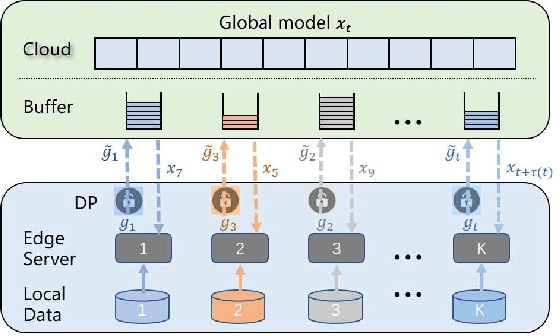

Federated learning has been showing as a promising approach in paving the last mile of artificial intelligence, due to its great potential of solving the data isolation problem in large scale machine learning. Particularly, with consideration of the heterogeneity in practical edge computing systems, asynchronous edge-cloud collaboration based federated learning can further improve the learning efficiency by significantly reducing the straggler effect. Despite no raw data sharing, the open architecture and extensive collaborations of asynchronous federated learning (AFL) still give some malicious participants great opportunities to infer other parties' training data, thus leading to serious concerns of privacy. To achieve a rigorous privacy guarantee with high utility, we investigate to secure asynchronous edge-cloud collaborative federated learning with differential privacy, focusing on the impacts of differential privacy on model convergence of AFL. Formally, we give the first analysis on the model convergence of AFL under DP and propose a multi-stage adjustable private algorithm (MAPA) to improve the trade-off between model utility and privacy by dynamically adjusting both the noise scale and the learning rate. Through extensive simulations and real-world experiments with an edge-could testbed, we demonstrate that MAPA significantly improves both the model accuracy and convergence speed with sufficient privacy guarantee.