 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelOps: AI-driven Operations and Maintenance for Telecommunication Networks
Dec 06, 2024Telecommunication Networks (TNs) have become the most important infrastructure for data communications over the last century. Operations and maintenance (O&M) is extremely important to ensure the availability, effectiveness, and efficiency of TN communications. Different from the popular O&M technique for IT systems (e.g., the cloud), artificial intelligence for IT Operations (AIOps), O&M for TNs meets the following three fundamental challenges: topological dependence of network components, highly heterogeneous software, and restricted failure data. This article presents TelOps, the first AI-driven O&M framework for TNs, systematically enhanced with mechanism, data, and empirical knowledge. We provide a comprehensive comparison between TelOps and AIOps, and conduct a proof-of-concept case study on a typical O&M task (failure diagnosis) for a real industrial TN. As the first systematic AI-driven O&M framework for TNs, TelOps opens a new door to applying AI techniques to TN automation.
* 7 pages, 4 figures, magazine
EdgeSync: Faster Edge-model Updating via Adaptive Continuous Learning for Video Data Drift
Jun 05, 2024



Real-time video analytics systems typically place models with fewer weights on edge devices to reduce latency. The distribution of video content features may change over time for various reasons (i.e. light and weather change) , leading to accuracy degradation of existing models, to solve this problem, recent work proposes a framework that uses a remote server to continually train and adapt the lightweight model at edge with the help of complex model. However, existing analytics approaches leave two challenges untouched: firstly, retraining task is compute-intensive, resulting in large model update delays; secondly, new model may not fit well enough with the data distribution of the current video stream. To address these challenges, in this paper, we present EdgeSync, EdgeSync filters the samples by considering both timeliness and inference results to make training samples more relevant to the current video content as well as reduce the update delay, to improve the quality of training, EdgeSync also designs a training management module that can efficiently adjusts the model training time and training order on the runtime. By evaluating real datasets with complex scenes, our method improves about 3.4% compared to existing methods and about 10% compared to traditional means.
FedLED: Label-Free Equipment Fault Diagnosis with Vertical Federated Transfer Learning
Dec 29, 2023



Intelligent equipment fault diagnosis based on Federated Transfer Learning (FTL) attracts considerable attention from both academia and industry. It allows real-world industrial agents with limited samples to construct a fault diagnosis model without jeopardizing their raw data privacy. Existing approaches, however, can neither address the intense sample heterogeneity caused by different working conditions of practical agents, nor the extreme fault label scarcity, even zero, of newly deployed equipment. To address these issues, we present FedLED, the first unsupervised vertical FTL equipment fault diagnosis method, where knowledge of the unlabeled target domain is further exploited for effective unsupervised model transfer. Results of extensive experiments using data of real equipment monitoring demonstrate that FedLED obviously outperforms SOTA approaches in terms of both diagnosis accuracy (up to 4.13 times) and generality. We expect our work to inspire further study on label-free equipment fault diagnosis systematically enhanced by target domain knowledge.
Generative Model-based Feature Knowledge Distillation for Action Recognition
Dec 14, 2023Knowledge distillation (KD), a technique widely employed in computer vision, has emerged as a de facto standard for improving the performance of small neural networks. However, prevailing KD-based approaches in video tasks primarily focus on designing loss functions and fusing cross-modal information. This overlooks the spatial-temporal feature semantics, resulting in limited advancements in model compression. Addressing this gap, our paper introduces an innovative knowledge distillation framework, with the generative model for training a lightweight student model. In particular, the framework is organized into two steps: the initial phase is Feature Representation, wherein a generative model-based attention module is trained to represent feature semantics; Subsequently, the Generative-based Feature Distillation phase encompasses both Generative Distillation and Attention Distillation, with the objective of transferring attention-based feature semantics with the generative model. The efficacy of our approach is demonstrated through comprehensive experiments on diverse popular datasets, proving considerable enhancements in video action recognition task. Moreover, the effectiveness of our proposed framework is validated in the context of more intricate video action detection task. Our code is available at https://github.com/aaai-24/Generative-based-KD.
Controlled Randomness Improves the Performance of Transformer Models
Oct 20, 2023

During the pre-training step of natural language models, the main objective is to learn a general representation of the pre-training dataset, usually requiring large amounts of textual data to capture the complexity and diversity of natural language. Contrasting this, in most cases, the size of the data available to solve the specific downstream task is often dwarfed by the aforementioned pre-training dataset, especially in domains where data is scarce. We introduce controlled randomness, i.e. noise, into the training process to improve fine-tuning language models and explore the performance of targeted noise in addition to the parameters of these models. We find that adding such noise can improve the performance in our two downstream tasks of joint named entity recognition and relation extraction and text summarization.
Weakly-Supervised Action Localization by Hierarchically-structured Latent Attention Modeling
Aug 19, 2023Weakly-supervised action localization aims to recognize and localize action instancese in untrimmed videos with only video-level labels. Most existing models rely on multiple instance learning(MIL), where the predictions of unlabeled instances are supervised by classifying labeled bags. The MIL-based methods are relatively well studied with cogent performance achieved on classification but not on localization. Generally, they locate temporal regions by the video-level classification but overlook the temporal variations of feature semantics. To address this problem, we propose a novel attention-based hierarchically-structured latent model to learn the temporal variations of feature semantics. Specifically, our model entails two components, the first is an unsupervised change-points detection module that detects change-points by learning the latent representations of video features in a temporal hierarchy based on their rates of change, and the second is an attention-based classification model that selects the change-points of the foreground as the boundaries. To evaluate the effectiveness of our model, we conduct extensive experiments on two benchmark datasets, THUMOS-14 and ActivityNet-v1.3. The experiments show that our method outperforms current state-of-the-art methods, and even achieves comparable performance with fully-supervised methods.
ACE: Towards Application-Centric Edge-Cloud Collaborative Intelligence
Mar 24, 2022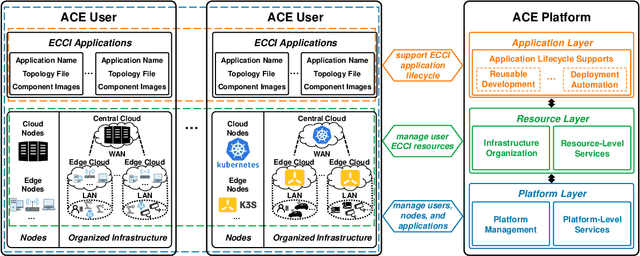
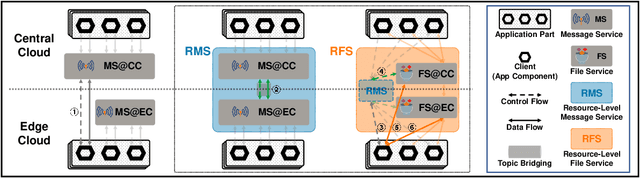
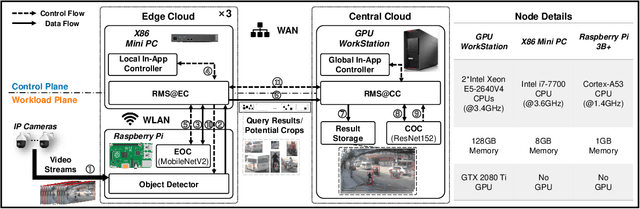
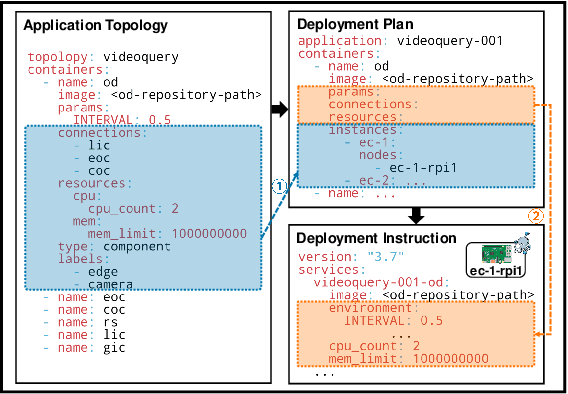
Intelligent applications based on machine learning are impacting many parts of our lives. They are required to operate under rigorous practical constraints in terms of service latency, network bandwidth overheads, and also privacy. Yet current implementations running in the Cloud are unable to satisfy all these constraints. The Edge-Cloud Collaborative Intelligence (ECCI) paradigm has become a popular approach to address such issues, and rapidly increasing applications are developed and deployed. However, these prototypical implementations are developer-dependent and scenario-specific without generality, which cannot be efficiently applied in large-scale or to general ECC scenarios in practice, due to the lack of supports for infrastructure management, edge-cloud collaborative service, complex intelligence workload, and efficient performance optimization. In this article, we systematically design and construct the first unified platform, ACE, that handles ever-increasing edge and cloud resources, user-transparent services, and proliferating intelligence workloads with increasing scale and complexity, to facilitate cost-efficient and high-performing ECCI application development and deployment. For verification, we explicitly present the construction process of an ACE-based intelligent video query application, and demonstrate how to achieve customizable performance optimization efficiently. Based on our initial experience, we discuss both the limitations and vision of ACE to shed light on promising issues to elaborate in the approaching ECCI ecosystem.
HEU Emotion: A Large-scale Database for Multi-modal Emotion Recognition in the Wild
Jul 24, 2020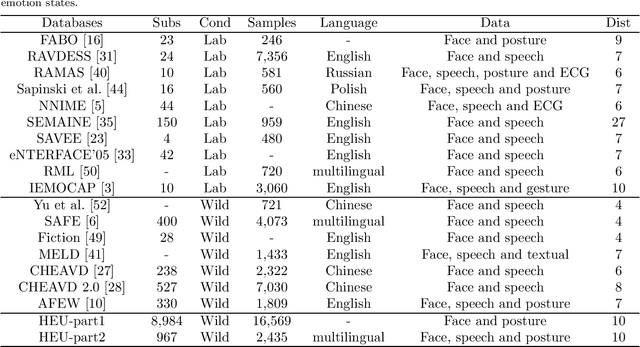
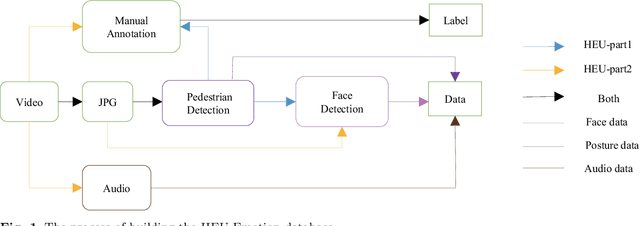


The study of affective computing in the wild setting is underpinned by databases. Existing multimodal emotion databases in the real-world conditions are few and small, with a limited number of subjects and expressed in a single language. To meet this requirement, we collected, annotated, and prepared to release a new natural state video database (called HEU Emotion). HEU Emotion contains a total of 19,004 video clips, which is divided into two parts according to the data source. The first part contains videos downloaded from Tumblr, Google, and Giphy, including 10 emotions and two modalities (facial expression and body posture). The second part includes corpus taken manually from movies, TV series, and variety shows, consisting of 10 emotions and three modalities (facial expression, body posture, and emotional speech). HEU Emotion is by far the most extensive multi-modal emotional database with 9,951 subjects. In order to provide a benchmark for emotion recognition, we used many conventional machine learning and deep learning methods to evaluate HEU Emotion. We proposed a Multi-modal Attention module to fuse multi-modal features adaptively. After multi-modal fusion, the recognition accuracies for the two parts increased by 2.19% and 4.01% respectively over those of single-modal facial expression recognition.
CDC: Classification Driven Compression for Bandwidth Efficient Edge-Cloud Collaborative Deep Learning
May 04, 2020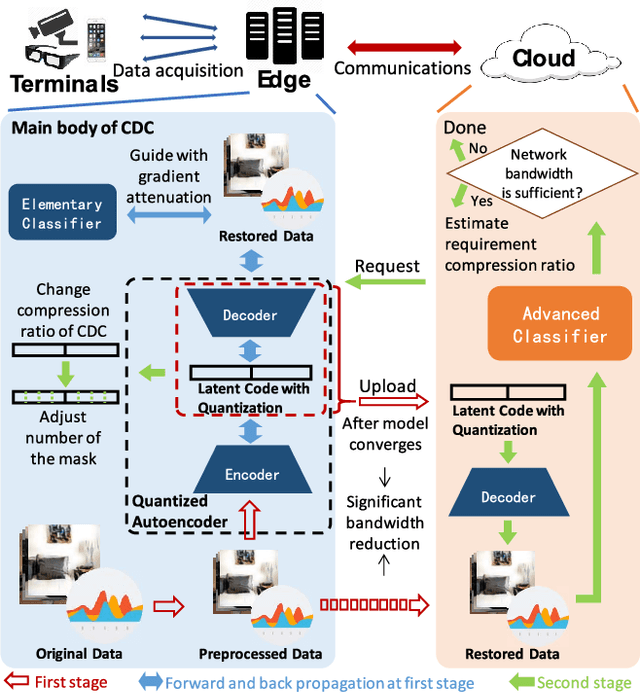
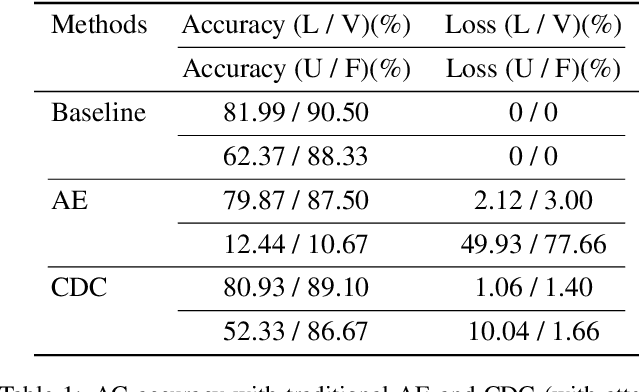
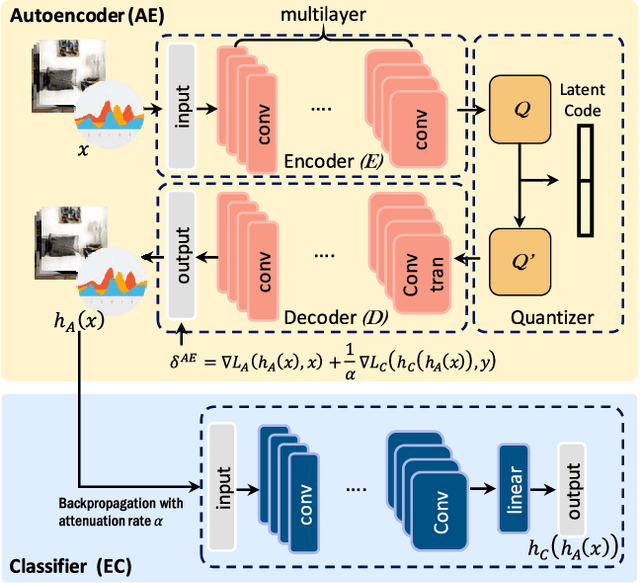
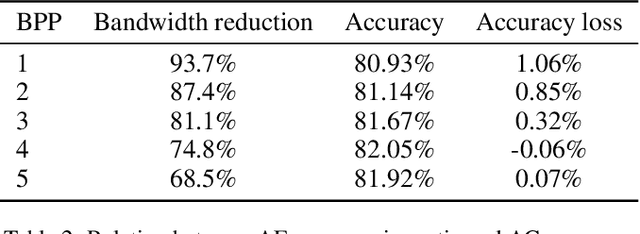
The emerging edge-cloud collaborative Deep Learning (DL) paradigm aims at improving the performance of practical DL implementations in terms of cloud bandwidth consumption, response latency, and data privacy preservation. Focusing on bandwidth efficient edge-cloud collaborative training of DNN-based classifiers, we present CDC, a Classification Driven Compression framework that reduces bandwidth consumption while preserving classification accuracy of edge-cloud collaborative DL. Specifically, to reduce bandwidth consumption, for resource-limited edge servers, we develop a lightweight autoencoder with a classification guidance for compression with classification driven feature preservation, which allows edges to only upload the latent code of raw data for accurate global training on the Cloud. Additionally, we design an adjustable quantization scheme adaptively pursuing the tradeoff between bandwidth consumption and classification accuracy under different network conditions, where only fine-tuning is required for rapid compression ratio adjustment. Results of extensive experiments demonstrate that, compared with DNN training with raw data, CDC consumes 14.9 times less bandwidth with an accuracy loss no more than 1.06%, and compared with DNN training with data compressed by AE without guidance, CDC introduces at least 100% lower accuracy loss.
OL4EL: Online Learning for Edge-cloud Collaborative Learning on Heterogeneous Edges with Resource Constraints
Apr 23, 2020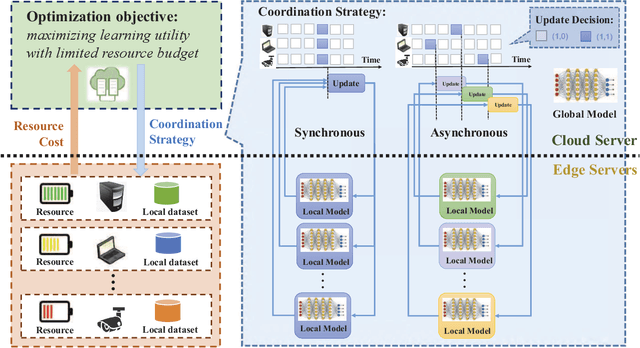
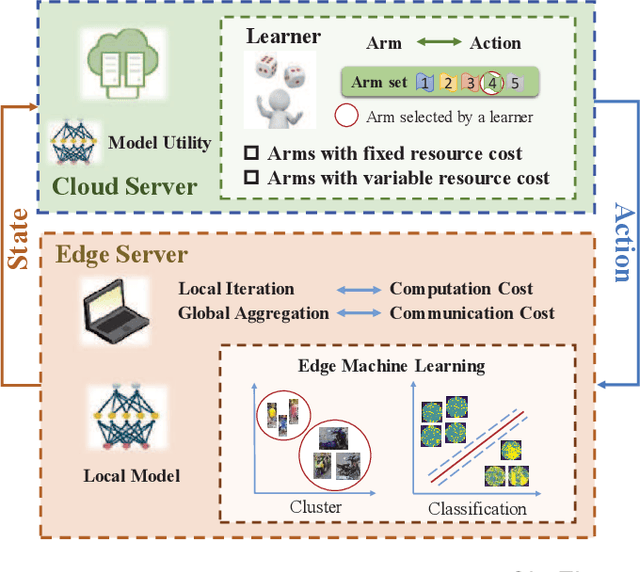
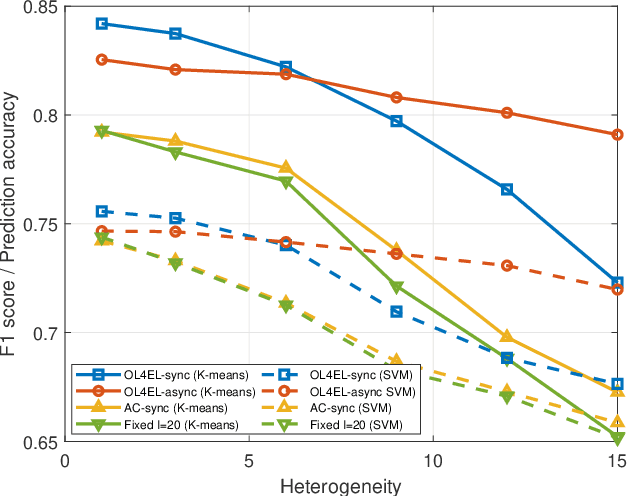
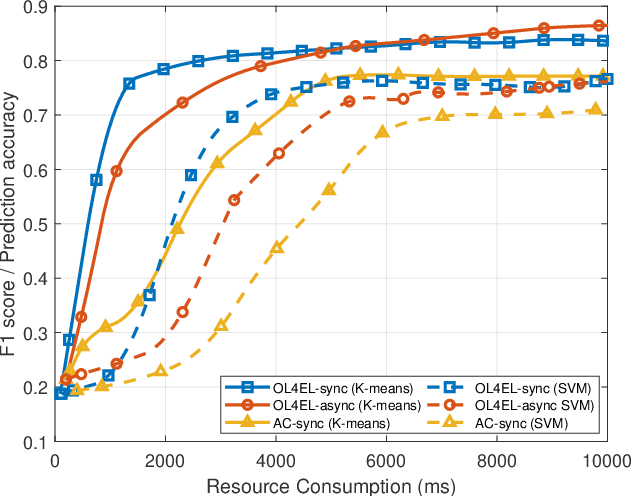
Distributed machine learning (ML) at network edge is a promising paradigm that can preserve both network bandwidth and privacy of data providers. However, heterogeneous and limited computation and communication resources on edge servers (or edges) pose great challenges on distributed ML and formulate a new paradigm of Edge Learning (i.e. edge-cloud collaborative machine learning). In this article, we propose a novel framework of 'learning to learn' for effective Edge Learning (EL) on heterogeneous edges with resource constraints. We first model the dynamic determination of collaboration strategy (i.e. the allocation of local iterations at edge servers and global aggregations on the Cloud during collaborative learning process) as an online optimization problem to achieve the tradeoff between the performance of EL and the resource consumption of edge servers. Then, we propose an Online Learning for EL (OL4EL) framework based on the budget-limited multi-armed bandit model. OL4EL supports both synchronous and asynchronous learning patterns, and can be used for both supervised and unsupervised learning tasks. To evaluate the performance of OL4EL, we conducted both real-world testbed experiments and extensive simulations based on docker containers, where both Support Vector Machine and K-means were considered as use cases. Experimental results demonstrate that OL4EL significantly outperforms state-of-the-art EL and other collaborative ML approaches in terms of the trade-off between learning performance and resource consumption.