 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Inpainting: Unleash 3D Understanding for Precise Camera-Controlled Video Generation
Jan 15, 2026Camera control has been extensively studied in conditioned video generation; however, performing precisely altering the camera trajectories while faithfully preserving the video content remains a challenging task. The mainstream approach to achieving precise camera control is warping a 3D representation according to the target trajectory. However, such methods fail to fully leverage the 3D priors of video diffusion models (VDMs) and often fall into the Inpainting Trap, resulting in subject inconsistency and degraded generation quality. To address this problem, we propose DepthDirector, a video re-rendering framework with precise camera controllability. By leveraging the depth video from explicit 3D representation as camera-control guidance, our method can faithfully reproduce the dynamic scene of an input video under novel camera trajectories. Specifically, we design a View-Content Dual-Stream Condition mechanism that injects both the source video and the warped depth sequence rendered under the target viewpoint into the pretrained video generation model. This geometric guidance signal enables VDMs to comprehend camera movements and leverage their 3D understanding capabilities, thereby facilitating precise camera control and consistent content generation. Next, we introduce a lightweight LoRA-based video diffusion adapter to train our framework, fully preserving the knowledge priors of VDMs. Additionally, we construct a large-scale multi-camera synchronized dataset named MultiCam-WarpData using Unreal Engine 5, containing 8K videos across 1K dynamic scenes. Extensive experiments show that DepthDirector outperforms existing methods in both camera controllability and visual quality. Our code and dataset will be publicly available.
NeuralSSD: A Neural Solver for Signed Distance Surface Reconstruction
Nov 18, 2025We proposed a generalized method, NeuralSSD, for reconstructing a 3D implicit surface from the widely-available point cloud data. NeuralSSD is a solver-based on the neural Galerkin method, aimed at reconstructing higher-quality and accurate surfaces from input point clouds. Implicit method is preferred due to its ability to accurately represent shapes and its robustness in handling topological changes. However, existing parameterizations of implicit fields lack explicit mechanisms to ensure a tight fit between the surface and input data. To address this, we propose a novel energy equation that balances the reliability of point cloud information. Additionally, we introduce a new convolutional network that learns three-dimensional information to achieve superior optimization results. This approach ensures that the reconstructed surface closely adheres to the raw input points and infers valuable inductive biases from point clouds, resulting in a highly accurate and stable surface reconstruction. NeuralSSD is evaluated on a variety of challenging datasets, including the ShapeNet and Matterport datasets, and achieves state-of-the-art results in terms of both surface reconstruction accuracy and generalizability.
Recovering Complete Actions for Cross-dataset Skeleton Action Recognition
Oct 31, 2024



Despite huge progress in skeleton-based action recognition, its generalizability to different domains remains a challenging issue. In this paper, to solve the skeleton action generalization problem, we present a recover-and-resample augmentation framework based on a novel complete action prior. We observe that human daily actions are confronted with temporal mismatch across different datasets, as they are usually partial observations of their complete action sequences. By recovering complete actions and resampling from these full sequences, we can generate strong augmentations for unseen domains. At the same time, we discover the nature of general action completeness within large datasets, indicated by the per-frame diversity over time. This allows us to exploit two assets of transferable knowledge that can be shared across action samples and be helpful for action completion: boundary poses for determining the action start, and linear temporal transforms for capturing global action patterns. Therefore, we formulate the recovering stage as a two-step stochastic action completion with boundary pose-conditioned extrapolation followed by smooth linear transforms. Both the boundary poses and linear transforms can be efficiently learned from the whole dataset via clustering. We validate our approach on a cross-dataset setting with three skeleton action datasets, outperforming other domain generalization approaches by a considerable margin.
Programmable Motion Generation for Open-Set Motion Control Tasks
May 29, 2024Character animation in real-world scenarios necessitates a variety of constraints, such as trajectories, key-frames, interactions, etc. Existing methodologies typically treat single or a finite set of these constraint(s) as separate control tasks. They are often specialized, and the tasks they address are rarely extendable or customizable. We categorize these as solutions to the close-set motion control problem. In response to the complexity of practical motion control, we propose and attempt to solve the open-set motion control problem. This problem is characterized by an open and fully customizable set of motion control tasks. To address this, we introduce a new paradigm, programmable motion generation. In this paradigm, any given motion control task is broken down into a combination of atomic constraints. These constraints are then programmed into an error function that quantifies the degree to which a motion sequence adheres to them. We utilize a pre-trained motion generation model and optimize its latent code to minimize the error function of the generated motion. Consequently, the generated motion not only inherits the prior of the generative model but also satisfies the required constraints. Experiments show that we can generate high-quality motions when addressing a wide range of unseen tasks. These tasks encompass motion control by motion dynamics, geometric constraints, physical laws, interactions with scenes, objects or the character own body parts, etc. All of these are achieved in a unified approach, without the need for ad-hoc paired training data collection or specialized network designs. During the programming of novel tasks, we observed the emergence of new skills beyond those of the prior model. With the assistance of large language models, we also achieved automatic programming. We hope that this work will pave the way for the motion control of general AI agents.
Theoretically Achieving Continuous Representation of Oriented Bounding Boxes
Feb 29, 2024Considerable efforts have been devoted to Oriented Object Detection (OOD). However, one lasting issue regarding the discontinuity in Oriented Bounding Box (OBB) representation remains unresolved, which is an inherent bottleneck for extant OOD methods. This paper endeavors to completely solve this issue in a theoretically guaranteed manner and puts an end to the ad-hoc efforts in this direction. Prior studies typically can only address one of the two cases of discontinuity: rotation and aspect ratio, and often inadvertently introduce decoding discontinuity, e.g. Decoding Incompleteness (DI) and Decoding Ambiguity (DA) as discussed in literature. Specifically, we propose a novel representation method called Continuous OBB (COBB), which can be readily integrated into existing detectors e.g. Faster-RCNN as a plugin. It can theoretically ensure continuity in bounding box regression which to our best knowledge, has not been achieved in literature for rectangle-based object representation. For fairness and transparency of experiments, we have developed a modularized benchmark based on the open-source deep learning framework Jittor's detection toolbox JDet for OOD evaluation. On the popular DOTA dataset, by integrating Faster-RCNN as the same baseline model, our new method outperforms the peer method Gliding Vertex by 1.13% mAP50 (relative improvement 1.54%), and 2.46% mAP75 (relative improvement 5.91%), without any tricks.
Semantic-Aware Transformation-Invariant RoI Align
Dec 15, 2023



Great progress has been made in learning-based object detection methods in the last decade. Two-stage detectors often have higher detection accuracy than one-stage detectors, due to the use of region of interest (RoI) feature extractors which extract transformation-invariant RoI features for different RoI proposals, making refinement of bounding boxes and prediction of object categories more robust and accurate. However, previous RoI feature extractors can only extract invariant features under limited transformations. In this paper, we propose a novel RoI feature extractor, termed Semantic RoI Align (SRA), which is capable of extracting invariant RoI features under a variety of transformations for two-stage detectors. Specifically, we propose a semantic attention module to adaptively determine different sampling areas by leveraging the global and local semantic relationship within the RoI. We also propose a Dynamic Feature Sampler which dynamically samples features based on the RoI aspect ratio to enhance the efficiency of SRA, and a new position embedding, \ie Area Embedding, to provide more accurate position information for SRA through an improved sampling area representation. Experiments show that our model significantly outperforms baseline models with slight computational overhead. In addition, it shows excellent generalization ability and can be used to improve performance with various state-of-the-art backbones and detection methods.
SLS4D: Sparse Latent Space for 4D Novel View Synthesis
Dec 15, 2023Neural radiance field (NeRF) has achieved great success in novel view synthesis and 3D representation for static scenarios. Existing dynamic NeRFs usually exploit a locally dense grid to fit the deformation field; however, they fail to capture the global dynamics and concomitantly yield models of heavy parameters. We observe that the 4D space is inherently sparse. Firstly, the deformation field is sparse in spatial but dense in temporal due to the continuity of of motion. Secondly, the radiance field is only valid on the surface of the underlying scene, usually occupying a small fraction of the whole space. We thus propose to represent the 4D scene using a learnable sparse latent space, a.k.a. SLS4D. Specifically, SLS4D first uses dense learnable time slot features to depict the temporal space, from which the deformation field is fitted with linear multi-layer perceptions (MLP) to predict the displacement of a 3D position at any time. It then learns the spatial features of a 3D position using another sparse latent space. This is achieved by learning the adaptive weights of each latent code with the attention mechanism. Extensive experiments demonstrate the effectiveness of our SLS4D: it achieves the best 4D novel view synthesis using only about $6\%$ parameters of the most recent work.
Long Range Pooling for 3D Large-Scale Scene Understanding
Jan 17, 2023Inspired by the success of recent vision transformers and large kernel design in convolutional neural networks (CNNs), in this paper, we analyze and explore essential reasons for their success. We claim two factors that are critical for 3D large-scale scene understanding: a larger receptive field and operations with greater non-linearity. The former is responsible for providing long range contexts and the latter can enhance the capacity of the network. To achieve the above properties, we propose a simple yet effective long range pooling (LRP) module using dilation max pooling, which provides a network with a large adaptive receptive field. LRP has few parameters, and can be readily added to current CNNs. Also, based on LRP, we present an entire network architecture, LRPNet, for 3D understanding. Ablation studies are presented to support our claims, and show that the LRP module achieves better results than large kernel convolution yet with reduced computation, due to its nonlinearity. We also demonstrate the superiority of LRPNet on various benchmarks: LRPNet performs the best on ScanNet and surpasses other CNN-based methods on S3DIS and Matterport3D. Code will be made publicly available.
MonoNeuralFusion: Online Monocular Neural 3D Reconstruction with Geometric Priors
Sep 30, 2022
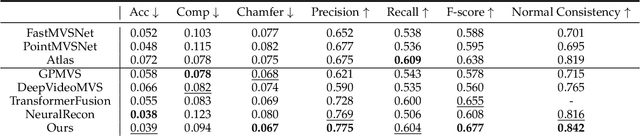
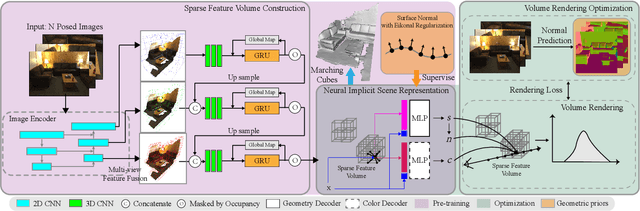
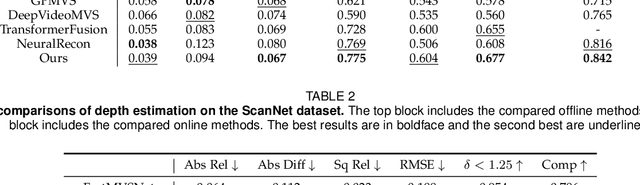
High-fidelity 3D scene reconstruction from monocular videos continues to be challenging, especially for complete and fine-grained geometry reconstruction. The previous 3D reconstruction approaches with neural implicit representations have shown a promising ability for complete scene reconstruction, while their results are often over-smooth and lack enough geometric details. This paper introduces a novel neural implicit scene representation with volume rendering for high-fidelity online 3D scene reconstruction from monocular videos. For fine-grained reconstruction, our key insight is to incorporate geometric priors into both the neural implicit scene representation and neural volume rendering, thus leading to an effective geometry learning mechanism based on volume rendering optimization. Benefiting from this, we present MonoNeuralFusion to perform the online neural 3D reconstruction from monocular videos, by which the 3D scene geometry is efficiently generated and optimized during the on-the-fly 3D monocular scanning. The extensive comparisons with state-of-the-art approaches show that our MonoNeuralFusion consistently generates much better complete and fine-grained reconstruction results, both quantitatively and qualitatively.
ClusterGNN: Cluster-based Coarse-to-Fine Graph Neural Network for Efficient Feature Matching
Apr 25, 2022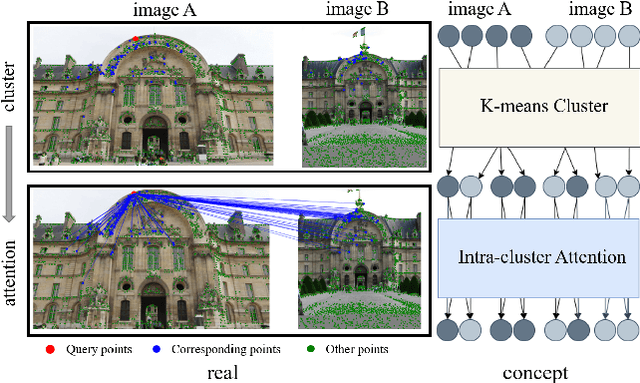
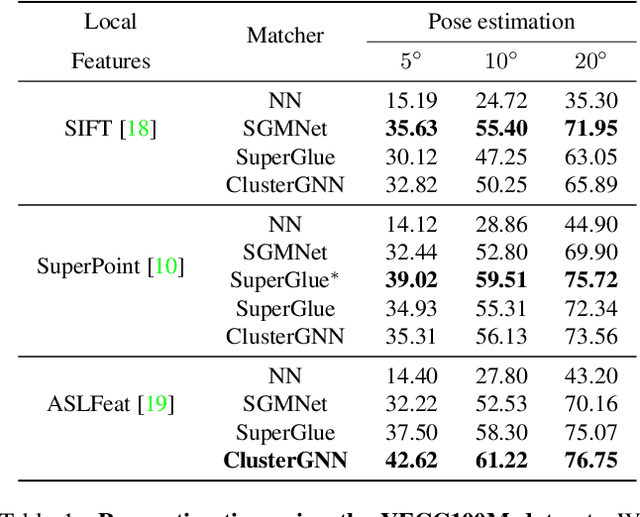
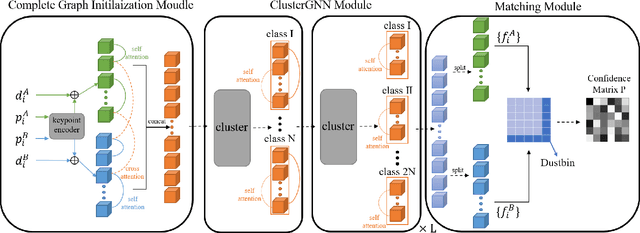
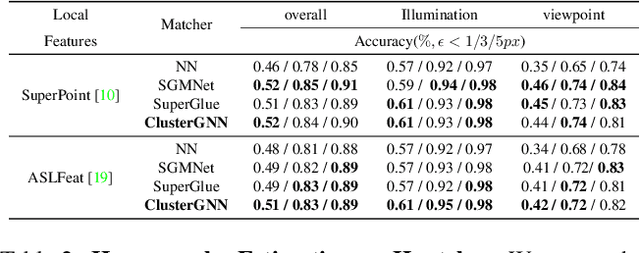
Graph Neural Networks (GNNs) with attention have been successfully applied for learning visual feature matching. However, current methods learn with complete graphs, resulting in a quadratic complexity in the number of features. Motivated by a prior observation that self- and cross- attention matrices converge to a sparse representation, we propose ClusterGNN, an attentional GNN architecture which operates on clusters for learning the feature matching task. Using a progressive clustering module we adaptively divide keypoints into different subgraphs to reduce redundant connectivity, and employ a coarse-to-fine paradigm for mitigating miss-classification within images. Our approach yields a 59.7% reduction in runtime and 58.4% reduction in memory consumption for dense detection, compared to current state-of-the-art GNN-based matching, while achieving a competitive performance on various computer vision tasks.