 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
DreamFit: Garment-Centric Human Generation via a Lightweight Anything-Dressing Encoder
Dec 23, 2024



Diffusion models for garment-centric human generation from text or image prompts have garnered emerging attention for their great application potential. However, existing methods often face a dilemma: lightweight approaches, such as adapters, are prone to generate inconsistent textures; while finetune-based methods involve high training costs and struggle to maintain the generalization capabilities of pretrained diffusion models, limiting their performance across diverse scenarios. To address these challenges, we propose DreamFit, which incorporates a lightweight Anything-Dressing Encoder specifically tailored for the garment-centric human generation. DreamFit has three key advantages: (1) \textbf{Lightweight training}: with the proposed adaptive attention and LoRA modules, DreamFit significantly minimizes the model complexity to 83.4M trainable parameters. (2)\textbf{Anything-Dressing}: Our model generalizes surprisingly well to a wide range of (non-)garments, creative styles, and prompt instructions, consistently delivering high-quality results across diverse scenarios. (3) \textbf{Plug-and-play}: DreamFit is engineered for smooth integration with any community control plugins for diffusion models, ensuring easy compatibility and minimizing adoption barriers. To further enhance generation quality, DreamFit leverages pretrained large multi-modal models (LMMs) to enrich the prompt with fine-grained garment descriptions, thereby reducing the prompt gap between training and inference. We conduct comprehensive experiments on both $768 \times 512$ high-resolution benchmarks and in-the-wild images. DreamFit surpasses all existing methods, highlighting its state-of-the-art capabilities of garment-centric human generation.
Dynamic Try-On: Taming Video Virtual Try-on with Dynamic Attention Mechanism
Dec 13, 2024



Video try-on stands as a promising area for its tremendous real-world potential. Previous research on video try-on has primarily focused on transferring product clothing images to videos with simple human poses, while performing poorly with complex movements. To better preserve clothing details, those approaches are armed with an additional garment encoder, resulting in higher computational resource consumption. The primary challenges in this domain are twofold: (1) leveraging the garment encoder's capabilities in video try-on while lowering computational requirements; (2) ensuring temporal consistency in the synthesis of human body parts, especially during rapid movements. To tackle these issues, we propose a novel video try-on framework based on Diffusion Transformer(DiT), named Dynamic Try-On. To reduce computational overhead, we adopt a straightforward approach by utilizing the DiT backbone itself as the garment encoder and employing a dynamic feature fusion module to store and integrate garment features. To ensure temporal consistency of human body parts, we introduce a limb-aware dynamic attention module that enforces the DiT backbone to focus on the regions of human limbs during the denoising process. Extensive experiments demonstrate the superiority of Dynamic Try-On in generating stable and smooth try-on results, even for videos featuring complicated human postures.
GarmentAligner: Text-to-Garment Generation via Retrieval-augmented Multi-level Corrections
Aug 23, 2024



General text-to-image models bring revolutionary innovation to the fields of arts, design, and media. However, when applied to garment generation, even the state-of-the-art text-to-image models suffer from fine-grained semantic misalignment, particularly concerning the quantity, position, and interrelations of garment components. Addressing this, we propose GarmentAligner, a text-to-garment diffusion model trained with retrieval-augmented multi-level corrections. To achieve semantic alignment at the component level, we introduce an automatic component extraction pipeline to obtain spatial and quantitative information of garment components from corresponding images and captions. Subsequently, to exploit component relationships within the garment images, we construct retrieval subsets for each garment by retrieval augmentation based on component-level similarity ranking and conduct contrastive learning to enhance the model perception of components from positive and negative samples. To further enhance the alignment of components across semantic, spatial, and quantitative granularities, we propose the utilization of multi-level correction losses that leverage detailed component information. The experimental findings demonstrate that GarmentAligner achieves superior fidelity and fine-grained semantic alignment when compared to existing competitors.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation
May 01, 2024



This paper introduces MMTryon, a multi-modal multi-reference VIrtual Try-ON (VITON) framework, which can generate high-quality compositional try-on results by taking as inputs a text instruction and multiple garment images. Our MMTryon mainly addresses two problems overlooked in prior literature: 1) Support of multiple try-on items and dressing styleExisting methods are commonly designed for single-item try-on tasks (e.g., upper/lower garments, dresses) and fall short on customizing dressing styles (e.g., zipped/unzipped, tuck-in/tuck-out, etc.) 2) Segmentation Dependency. They further heavily rely on category-specific segmentation models to identify the replacement regions, with segmentation errors directly leading to significant artifacts in the try-on results. For the first issue, our MMTryon introduces a novel multi-modality and multi-reference attention mechanism to combine the garment information from reference images and dressing-style information from text instructions. Besides, to remove the segmentation dependency, MMTryon uses a parsing-free garment encoder and leverages a novel scalable data generation pipeline to convert existing VITON datasets to a form that allows MMTryon to be trained without requiring any explicit segmentation. Extensive experiments on high-resolution benchmarks and in-the-wild test sets demonstrate MMTryon's superiority over existing SOTA methods both qualitatively and quantitatively. Besides, MMTryon's impressive performance on multi-items and style-controllable virtual try-on scenarios and its ability to try on any outfit in a large variety of scenarios from any source image, opens up a new avenue for future investigation in the fashion community.
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
Fashion Matrix: Editing Photos by Just Talking
Jul 25, 2023



The utilization of Large Language Models (LLMs) for the construction of AI systems has garnered significant attention across diverse fields. The extension of LLMs to the domain of fashion holds substantial commercial potential but also inherent challenges due to the intricate semantic interactions in fashion-related generation. To address this issue, we developed a hierarchical AI system called Fashion Matrix dedicated to editing photos by just talking. This system facilitates diverse prompt-driven tasks, encompassing garment or accessory replacement, recoloring, addition, and removal. Specifically, Fashion Matrix employs LLM as its foundational support and engages in iterative interactions with users. It employs a range of Semantic Segmentation Models (e.g., Grounded-SAM, MattingAnything, etc.) to delineate the specific editing masks based on user instructions. Subsequently, Visual Foundation Models (e.g., Stable Diffusion, ControlNet, etc.) are leveraged to generate edited images from text prompts and masks, thereby facilitating the automation of fashion editing processes. Experiments demonstrate the outstanding ability of Fashion Matrix to explores the collaborative potential of functionally diverse pre-trained models in the domain of fashion editing.
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022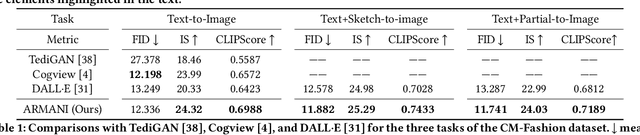

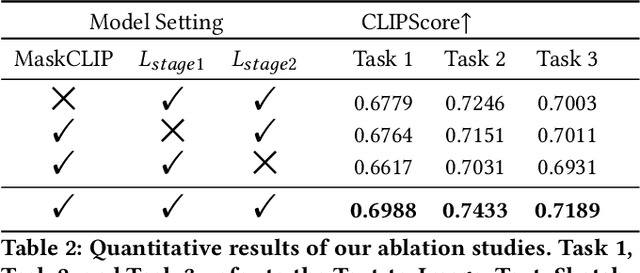
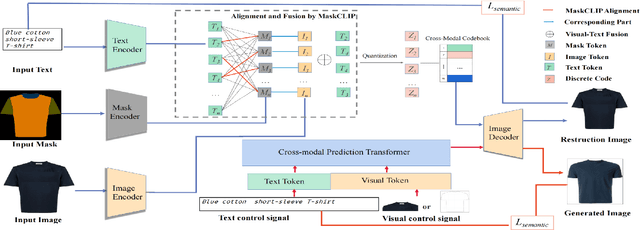
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model
Oct 28, 2021

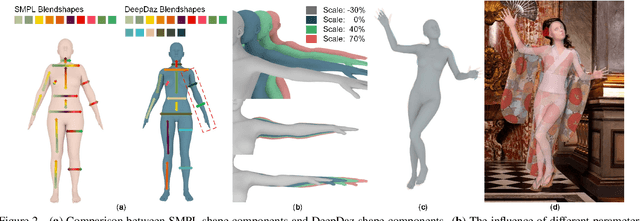
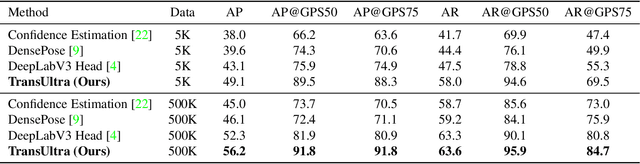
Recovering dense human poses from images plays a critical role in establishing an image-to-surface correspondence between RGB images and the 3D surface of the human body, serving the foundation of rich real-world applications, such as virtual humans, monocular-to-3d reconstruction. However, the popular DensePose-COCO dataset relies on a sophisticated manual annotation system, leading to severe limitations in acquiring the denser and more accurate annotated pose resources. In this work, we introduce a new 3D human-body model with a series of decoupled parameters that could freely control the generation of the body. Furthermore, we build a data generation system based on this decoupling 3D model, and construct an ultra dense synthetic benchmark UltraPose, containing around 1.3 billion corresponding points. Compared to the existing manually annotated DensePose-COCO dataset, the synthetic UltraPose has ultra dense image-to-surface correspondences without annotation cost and error. Our proposed UltraPose provides the largest benchmark and data resources for lifting the model capability in predicting more accurate dense poses. To promote future researches in this field, we also propose a transformer-based method to model the dense correspondence between 2D and 3D worlds. The proposed model trained on synthetic UltraPose can be applied to real-world scenarios, indicating the effectiveness of our benchmark and model.
* Accepted to ICCV 2021