 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Ghanaian NLP Landscape: A First Look
May 10, 2024Despite comprising one-third of global languages, African languages are critically underrepresented in Artificial Intelligence (AI), threatening linguistic diversity and cultural heritage. Ghanaian languages, in particular, face an alarming decline, with documented extinction and several at risk. This study pioneers a comprehensive survey of Natural Language Processing (NLP) research focused on Ghanaian languages, identifying methodologies, datasets, and techniques employed. Additionally, we create a detailed roadmap outlining challenges, best practices, and future directions, aiming to improve accessibility for researchers. This work serves as a foundational resource for Ghanaian NLP research and underscores the critical need for integrating global linguistic diversity into AI development.
How Does Unlabeled Data Provably Help Out-of-Distribution Detection?
Feb 05, 2024Using unlabeled data to regularize the machine learning models has demonstrated promise for improving safety and reliability in detecting out-of-distribution (OOD) data. Harnessing the power of unlabeled in-the-wild data is non-trivial due to the heterogeneity of both in-distribution (ID) and OOD data. This lack of a clean set of OOD samples poses significant challenges in learning an optimal OOD classifier. Currently, there is a lack of research on formally understanding how unlabeled data helps OOD detection. This paper bridges the gap by introducing a new learning framework SAL (Separate And Learn) that offers both strong theoretical guarantees and empirical effectiveness. The framework separates candidate outliers from the unlabeled data and then trains an OOD classifier using the candidate outliers and the labeled ID data. Theoretically, we provide rigorous error bounds from the lens of separability and learnability, formally justifying the two components in our algorithm. Our theory shows that SAL can separate the candidate outliers with small error rates, which leads to a generalization guarantee for the learned OOD classifier. Empirically, SAL achieves state-of-the-art performance on common benchmarks, reinforcing our theoretical insights. Code is publicly available at https://github.com/deeplearning-wisc/sal.
Dream the Impossible: Outlier Imagination with Diffusion Models
Sep 23, 2023Utilizing auxiliary outlier datasets to regularize the machine learning model has demonstrated promise for out-of-distribution (OOD) detection and safe prediction. Due to the labor intensity in data collection and cleaning, automating outlier data generation has been a long-desired alternative. Despite the appeal, generating photo-realistic outliers in the high dimensional pixel space has been an open challenge for the field. To tackle the problem, this paper proposes a new framework DREAM-OOD, which enables imagining photo-realistic outliers by way of diffusion models, provided with only the in-distribution (ID) data and classes. Specifically, DREAM-OOD learns a text-conditioned latent space based on ID data, and then samples outliers in the low-likelihood region via the latent, which can be decoded into images by the diffusion model. Different from prior works, DREAM-OOD enables visualizing and understanding the imagined outliers, directly in the pixel space. We conduct comprehensive quantitative and qualitative studies to understand the efficacy of DREAM-OOD, and show that training with the samples generated by DREAM-OOD can benefit OOD detection performance. Code is publicly available at https://github.com/deeplearning-wisc/dream-ood.
OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection
Jun 17, 2023Out-of-Distribution (OOD) detection is critical for the reliable operation of open-world intelligent systems. Despite the emergence of an increasing number of OOD detection methods, the evaluation inconsistencies present challenges for tracking the progress in this field. OpenOOD v1 initiated the unification of the OOD detection evaluation but faced limitations in scalability and usability. In response, this paper presents OpenOOD v1.5, a significant improvement from its predecessor that ensures accurate, standardized, and user-friendly evaluation of OOD detection methodologies. Notably, OpenOOD v1.5 extends its evaluation capabilities to large-scale datasets such as ImageNet, investigates full-spectrum OOD detection which is important yet underexplored, and introduces new features including an online leaderboard and an easy-to-use evaluator. This work also contributes in-depth analysis and insights derived from comprehensive experimental results, thereby enriching the knowledge pool of OOD detection methodologies. With these enhancements, OpenOOD v1.5 aims to drive advancements and offer a more robust and comprehensive evaluation benchmark for OOD detection research.
Feed Two Birds with One Scone: Exploiting Wild Data for Both Out-of-Distribution Generalization and Detection
Jun 15, 2023Modern machine learning models deployed in the wild can encounter both covariate and semantic shifts, giving rise to the problems of out-of-distribution (OOD) generalization and OOD detection respectively. While both problems have received significant research attention lately, they have been pursued independently. This may not be surprising, since the two tasks have seemingly conflicting goals. This paper provides a new unified approach that is capable of simultaneously generalizing to covariate shifts while robustly detecting semantic shifts. We propose a margin-based learning framework that exploits freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. We show both empirically and theoretically that the proposed margin constraint is the key to achieving both OOD generalization and detection. Extensive experiments show the superiority of our framework, outperforming competitive baselines that specialize in either OOD generalization or OOD detection. Code is publicly available at https://github.com/deeplearning-wisc/scone.
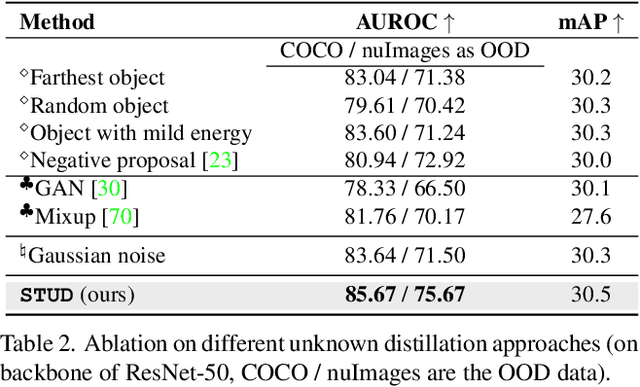
Non-Parametric Outlier Synthesis
Mar 06, 2023



Out-of-distribution (OOD) detection is indispensable for safely deploying machine learning models in the wild. One of the key challenges is that models lack supervision signals from unknown data, and as a result, can produce overconfident predictions on OOD data. Recent work on outlier synthesis modeled the feature space as parametric Gaussian distribution, a strong and restrictive assumption that might not hold in reality. In this paper, we propose a novel framework, Non-Parametric Outlier Synthesis (NPOS), which generates artificial OOD training data and facilitates learning a reliable decision boundary between ID and OOD data. Importantly, our proposed synthesis approach does not make any distributional assumption on the ID embeddings, thereby offering strong flexibility and generality. We show that our synthesis approach can be mathematically interpreted as a rejection sampling framework. Extensive experiments show that NPOS can achieve superior OOD detection performance, outperforming the competitive rivals by a significant margin. Code is publicly available at https://github.com/deeplearning-wisc/npos.
OpenOOD: Benchmarking Generalized Out-of-Distribution Detection
Oct 13, 2022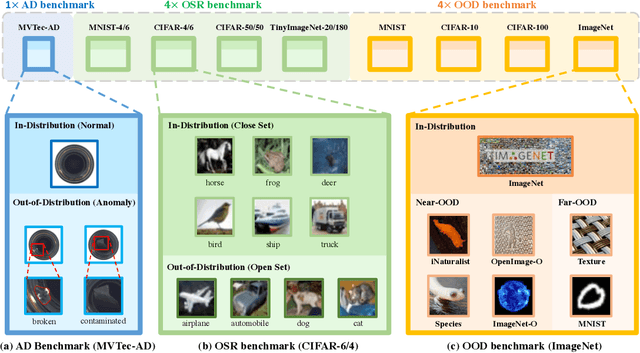
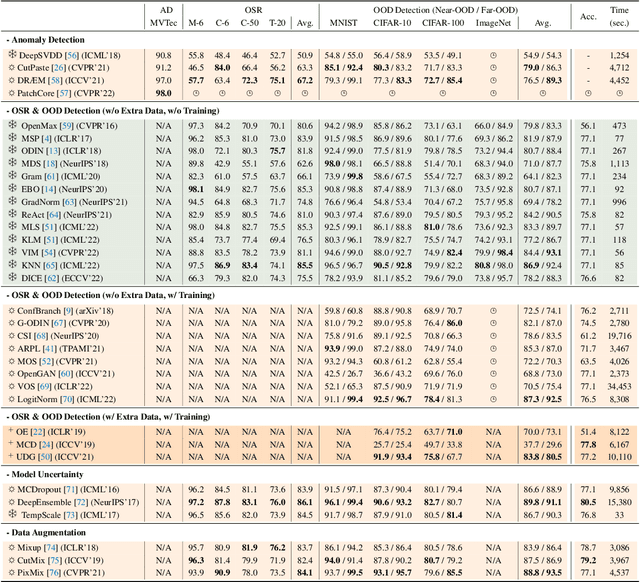
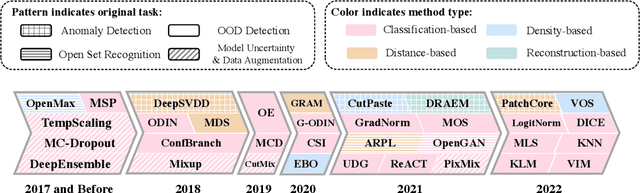
Out-of-distribution (OOD) detection is vital to safety-critical machine learning applications and has thus been extensively studied, with a plethora of methods developed in the literature. However, the field currently lacks a unified, strictly formulated, and comprehensive benchmark, which often results in unfair comparisons and inconclusive results. From the problem setting perspective, OOD detection is closely related to neighboring fields including anomaly detection (AD), open set recognition (OSR), and model uncertainty, since methods developed for one domain are often applicable to each other. To help the community to improve the evaluation and advance, we build a unified, well-structured codebase called OpenOOD, which implements over 30 methods developed in relevant fields and provides a comprehensive benchmark under the recently proposed generalized OOD detection framework. With a comprehensive comparison of these methods, we are gratified that the field has progressed significantly over the past few years, where both preprocessing methods and the orthogonal post-hoc methods show strong potential.
Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild
Mar 08, 2022
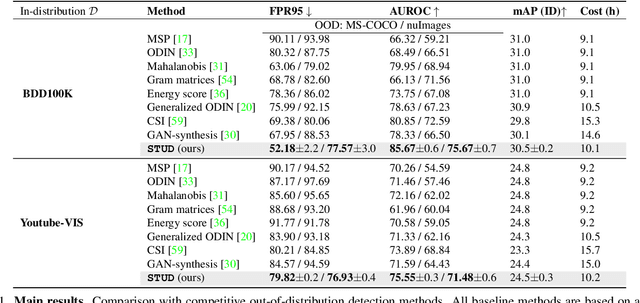
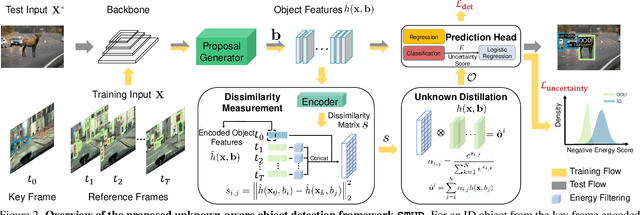
Building reliable object detectors that can detect out-of-distribution (OOD) objects is critical yet underexplored. One of the key challenges is that models lack supervision signals from unknown data, producing overconfident predictions on OOD objects. We propose a new unknown-aware object detection framework through Spatial-Temporal Unknown Distillation (STUD), which distills unknown objects from videos in the wild and meaningfully regularizes the model's decision boundary. STUD first identifies the unknown candidate object proposals in the spatial dimension, and then aggregates the candidates across multiple video frames to form a diverse set of unknown objects near the decision boundary. Alongside, we employ an energy-based uncertainty regularization loss, which contrastively shapes the uncertainty space between the in-distribution and distilled unknown objects. STUD establishes the state-of-the-art performance on OOD detection tasks for object detection, reducing the FPR95 score by over 10% compared to the previous best method. Code is available at https://github.com/deeplearning-wisc/stud.
VOS: Learning What You Don't Know by Virtual Outlier Synthesis
Feb 04, 2022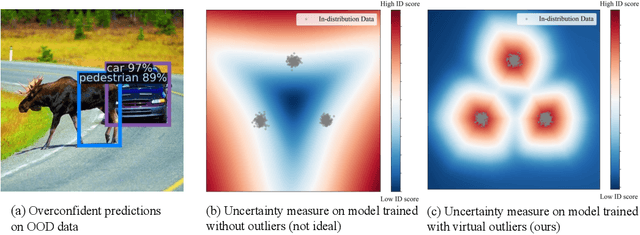
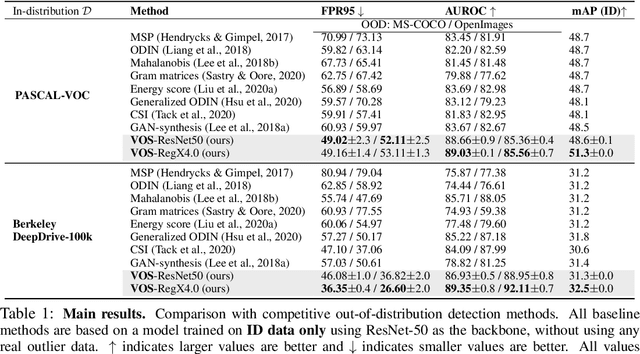
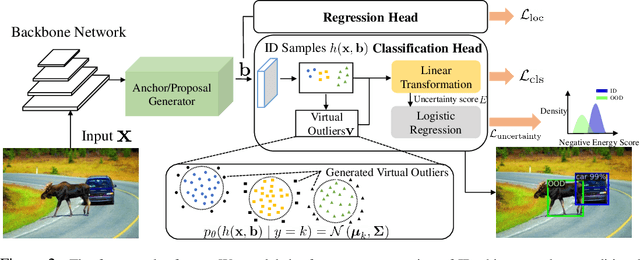
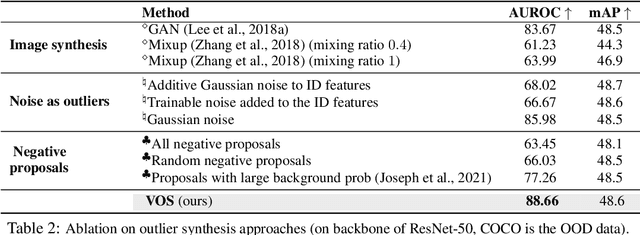
Out-of-distribution (OOD) detection has received much attention lately due to its importance in the safe deployment of neural networks. One of the key challenges is that models lack supervision signals from unknown data, and as a result, can produce overconfident predictions on OOD data. Previous approaches rely on real outlier datasets for model regularization, which can be costly and sometimes infeasible to obtain in practice. In this paper, we present VOS, a novel framework for OOD detection by adaptively synthesizing virtual outliers that can meaningfully regularize the model's decision boundary during training. Specifically, VOS samples virtual outliers from the low-likelihood region of the class-conditional distribution estimated in the feature space. Alongside, we introduce a novel unknown-aware training objective, which contrastively shapes the uncertainty space between the ID data and synthesized outlier data. VOS achieves state-of-the-art performance on both object detection and image classification models, reducing the FPR95 by up to 7.87% compared to the previous best method. Code is available at https://github.com/deeplearning-wisc/vos.
PI-GNN: A Novel Perspective on Semi-Supervised Node Classification against Noisy Labels
Jun 14, 2021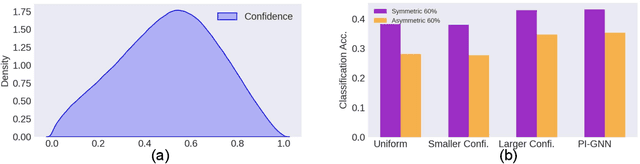
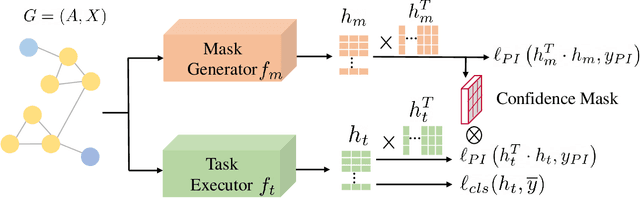
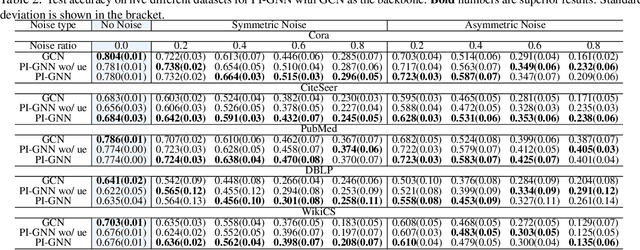
Semi-supervised node classification, as a fundamental problem in graph learning, leverages unlabeled nodes along with a small portion of labeled nodes for training. Existing methods rely heavily on high-quality labels, which, however, are expensive to obtain in real-world applications since certain noises are inevitably involved during the labeling process. It hence poses an unavoidable challenge for the learning algorithm to generalize well. In this paper, we propose a novel robust learning objective dubbed pairwise interactions (PI) for the model, such as Graph Neural Network (GNN) to combat noisy labels. Unlike classic robust training approaches that operate on the pointwise interactions between node and class label pairs, PI explicitly forces the embeddings for node pairs that hold a positive PI label to be close to each other, which can be applied to both labeled and unlabeled nodes. We design several instantiations for PI labels based on the graph structure and the node class labels, and further propose a new uncertainty-aware training technique to mitigate the negative effect of the sub-optimal PI labels. Extensive experiments on different datasets and GNN architectures demonstrate the effectiveness of PI, yielding a promising improvement over the state-of-the-art methods.