 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models and Fair Use
Mar 28, 2023Existing foundation models are trained on copyrighted material. Deploying these models can pose both legal and ethical risks when data creators fail to receive appropriate attribution or compensation. In the United States and several other countries, copyrighted content may be used to build foundation models without incurring liability due to the fair use doctrine. However, there is a caveat: If the model produces output that is similar to copyrighted data, particularly in scenarios that affect the market of that data, fair use may no longer apply to the output of the model. In this work, we emphasize that fair use is not guaranteed, and additional work may be necessary to keep model development and deployment squarely in the realm of fair use. First, we survey the potential risks of developing and deploying foundation models based on copyrighted content. We review relevant U.S. case law, drawing parallels to existing and potential applications for generating text, source code, and visual art. Experiments confirm that popular foundation models can generate content considerably similar to copyrighted material. Second, we discuss technical mitigations that can help foundation models stay in line with fair use. We argue that more research is needed to align mitigation strategies with the current state of the law. Lastly, we suggest that the law and technical mitigations should co-evolve. For example, coupled with other policy mechanisms, the law could more explicitly consider safe harbors when strong technical tools are used to mitigate infringement harms. This co-evolution may help strike a balance between intellectual property and innovation, which speaks to the original goal of fair use. But we emphasize that the strategies we describe here are not a panacea and more work is needed to develop policies that address the potential harms of foundation models.
Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks
Feb 11, 2023Recent advances in instruction-following large language models (LLMs) have led to dramatic improvements in a range of NLP tasks. Unfortunately, we find that the same improved capabilities amplify the dual-use risks for malicious purposes of these models. Dual-use is difficult to prevent as instruction-following capabilities now enable standard attacks from computer security. The capabilities of these instruction-following LLMs provide strong economic incentives for dual-use by malicious actors. In particular, we show that instruction-following LLMs can produce targeted malicious content, including hate speech and scams, bypassing in-the-wild defenses implemented by LLM API vendors. Our analysis shows that this content can be generated economically and at cost likely lower than with human effort alone. Together, our findings suggest that LLMs will increasingly attract more sophisticated adversaries and attacks, and addressing these attacks may require new approaches to mitigations.
Exploring the Limits of Differentially Private Deep Learning with Group-wise Clipping
Dec 03, 2022Differentially private deep learning has recently witnessed advances in computational efficiency and privacy-utility trade-off. We explore whether further improvements along the two axes are possible and provide affirmative answers leveraging two instantiations of \emph{group-wise clipping}. To reduce the compute time overhead of private learning, we show that \emph{per-layer clipping}, where the gradient of each neural network layer is clipped separately, allows clipping to be performed in conjunction with backpropagation in differentially private optimization. This results in private learning that is as memory-efficient and almost as fast per training update as non-private learning for many workflows of interest. While per-layer clipping with constant thresholds tends to underperform standard flat clipping, per-layer clipping with adaptive thresholds matches or outperforms flat clipping under given training epoch constraints, hence attaining similar or better task performance within less wall time. To explore the limits of scaling (pretrained) models in differentially private deep learning, we privately fine-tune the 175 billion-parameter GPT-3. We bypass scaling challenges associated with clipping gradients that are distributed across multiple devices with \emph{per-device clipping} that clips the gradient of each model piece separately on its host device. Privately fine-tuning GPT-3 with per-device clipping achieves a task performance at $\epsilon=1$ better than what is attainable by non-privately fine-tuning the largest GPT-2 on a summarization task.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
ImplantFormer: Vision Transformer based Implant Position Regression Using Dental CBCT Data
Oct 29, 2022Implant prosthesis is the most optimum treatment of dentition defect or dentition loss, which usually involves a surgical guide design process to decide the position of implant. However, such design heavily relies on the subjective experiences of dentist. To relieve this problem, in this paper, a transformer based Implant Position Regression Network, ImplantFormer, is proposed to automatically predict the implant position based on the oral CBCT data. The 3D CBCT data is firstly transformed into a series of 2D transverse plane slice views. ImplantFormer is then proposed to predict the position of implant based on the 2D slices of crown images. Convolutional stem and decoder are designed to coarsely extract image feature before the operation of patch embedding and integrate multi-levels feature map for robust prediction. The predictions of our network at tooth crown area are finally projected back to the positions at tooth root. As both long-range relationship and local features are involved, our approach can better represent global information and achieves better location performance than the state-of-the-art detectors. Experimental results on a dataset of 128 patients, collected from Shenzhen University General Hospital, show that our ImplantFormer achieves superior performance than benchmarks.
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe
Oct 25, 2022



Privacy concerns have attracted increasing attention in data-driven products and services. Existing legislation forbids arbitrary processing of personal data collected from individuals. Generating synthetic versions of such data with a formal privacy guarantee such as differential privacy (DP) is considered to be a solution to address privacy concerns. In this direction, we show a simple, practical, and effective recipe in the text domain: simply fine-tuning a generative language model with DP allows us to generate useful synthetic text while mitigating privacy concerns. Through extensive empirical analyses, we demonstrate that our method produces synthetic data that is competitive in terms of utility with its non-private counterpart and meanwhile provides strong protection against potential privacy leakages.
A Closer Look at the Calibration of Differentially Private Learners
Oct 15, 2022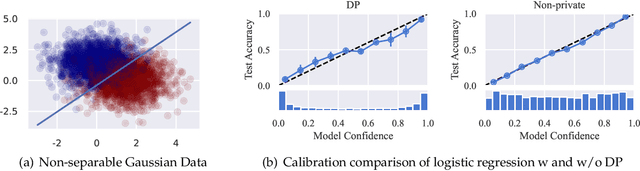
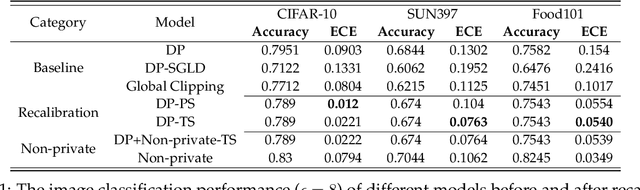
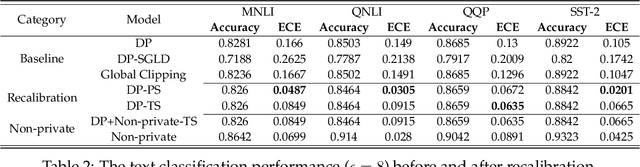
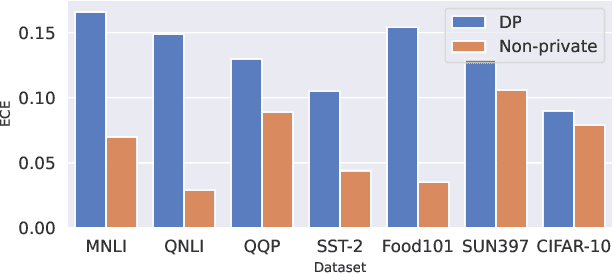
We systematically study the calibration of classifiers trained with differentially private stochastic gradient descent (DP-SGD) and observe miscalibration across a wide range of vision and language tasks. Our analysis identifies per-example gradient clipping in DP-SGD as a major cause of miscalibration, and we show that existing approaches for improving calibration with differential privacy only provide marginal improvements in calibration error while occasionally causing large degradations in accuracy. As a solution, we show that differentially private variants of post-processing calibration methods such as temperature scaling and Platt scaling are surprisingly effective and have negligible utility cost to the overall model. Across 7 tasks, temperature scaling and Platt scaling with DP-SGD result in an average 3.1-fold reduction in the in-domain expected calibration error and only incur at most a minor percent drop in accuracy.
Sample hardness based gradient loss for long-tailed cervical cell detection
Aug 07, 2022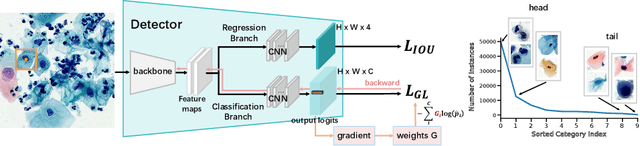
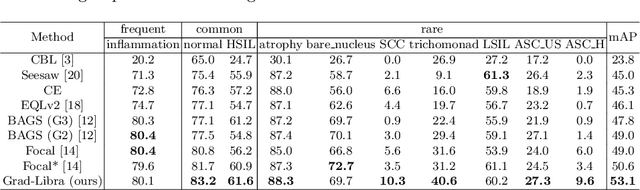
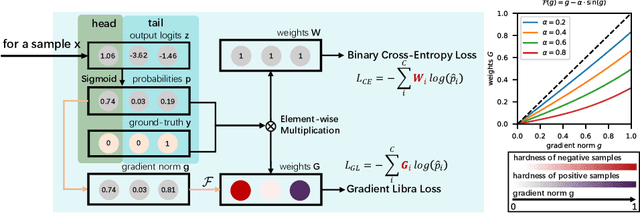
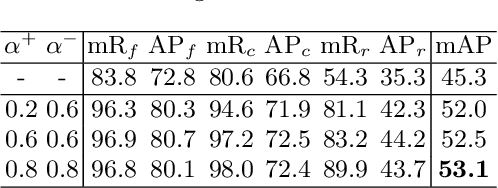
Due to the difficulty of cancer samples collection and annotation, cervical cancer datasets usually exhibit a long-tailed data distribution. When training a detector to detect the cancer cells in a WSI (Whole Slice Image) image captured from the TCT (Thinprep Cytology Test) specimen, head categories (e.g. normal cells and inflammatory cells) typically have a much larger number of samples than tail categories (e.g. cancer cells). Most existing state-of-the-art long-tailed learning methods in object detection focus on category distribution statistics to solve the problem in the long-tailed scenario without considering the "hardness" of each sample. To address this problem, in this work we propose a Grad-Libra Loss that leverages the gradients to dynamically calibrate the degree of hardness of each sample for different categories, and re-balance the gradients of positive and negative samples. Our loss can thus help the detector to put more emphasis on those hard samples in both head and tail categories. Extensive experiments on a long-tailed TCT WSI image dataset show that the mainstream detectors, e.g. RepPoints, FCOS, ATSS, YOLOF, etc. trained using our proposed Gradient-Libra Loss, achieved much higher (7.8%) mAP than that trained using cross-entropy classification loss.
When Does Differentially Private Learning Not Suffer in High Dimensions?
Jul 09, 2022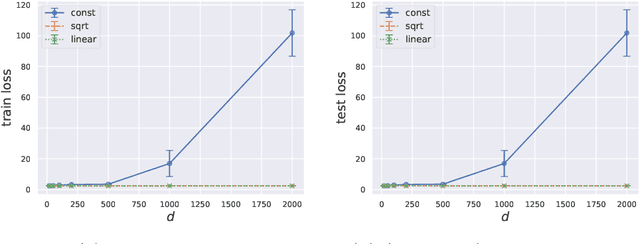
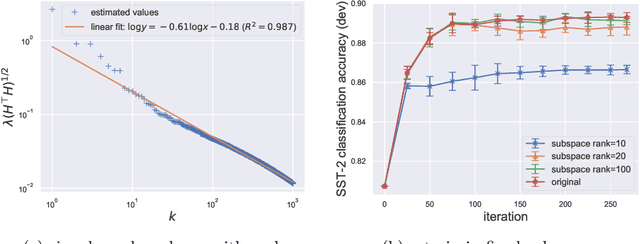
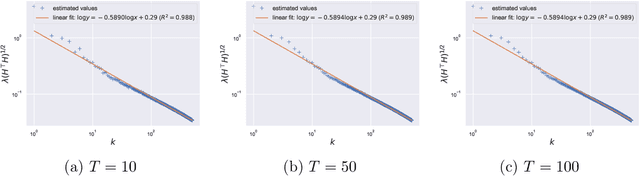
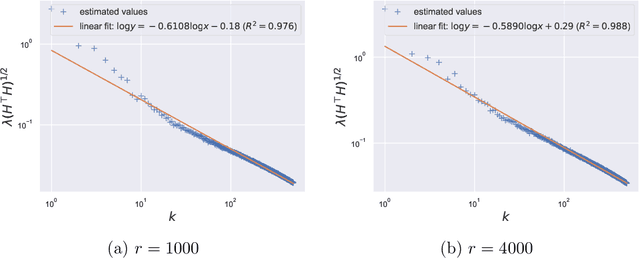
Large pretrained models can be privately fine-tuned to achieve performance approaching that of non-private models. A common theme in these results is the surprising observation that high-dimensional models can achieve favorable privacy-utility trade-offs. This seemingly contradicts known results on the model-size dependence of differentially private convex learning and raises the following research question: When does the performance of differentially private learning not degrade with increasing model size? We identify that the magnitudes of gradients projected onto subspaces is a key factor that determines performance. To precisely characterize this for private convex learning, we introduce a condition on the objective that we term restricted Lipschitz continuity and derive improved bounds for the excess empirical and population risks that are dimension-independent under additional conditions. We empirically show that in private fine-tuning of large language models, gradients evaluated near a local optimum are mostly controlled by a few principal components. This behavior is similar to conditions under which we obtain dimension-independent bounds in convex settings. Our theoretical and empirical results together provide a possible explanation for recent successes in large-scale private fine-tuning.
Large Language Models Can Be Strong Differentially Private Learners
Oct 12, 2021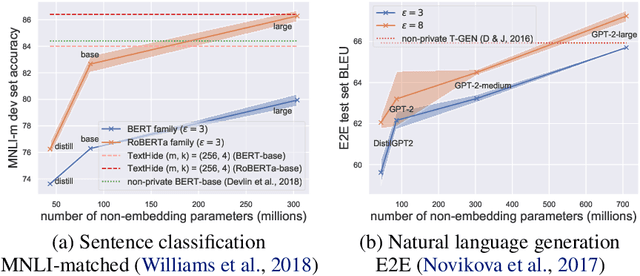
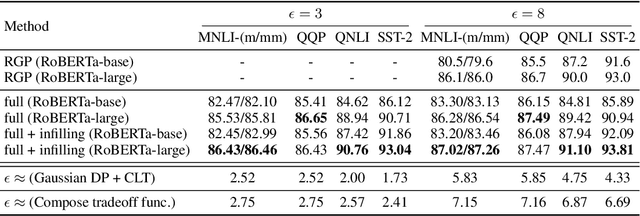
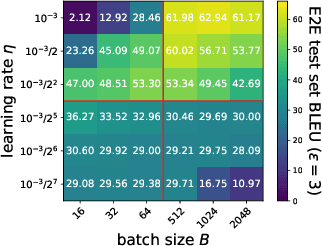
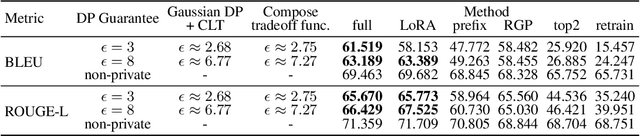
Differentially Private (DP) learning has seen limited success for building large deep learning models of text, and attempts at straightforwardly applying Differentially Private Stochastic Gradient Descent (DP-SGD) to NLP tasks have resulted in large performance drops and high computational overhead. We show that this performance drop can be mitigated with (1) the use of large pretrained models; (2) hyperparameters that suit DP optimization; and (3) fine-tuning objectives aligned with the pretraining procedure. With these factors set right, we obtain private NLP models that outperform state-of-the-art private training approaches and strong non-private baselines -- by directly fine-tuning pretrained models with DP optimization on moderately-sized corpora. To address the computational challenge of running DP-SGD with large Transformers, we propose a memory saving technique that allows clipping in DP-SGD to run without instantiating per-example gradients for any layer in the model. The technique enables privately training Transformers with almost the same memory cost as non-private training at a modest run-time overhead. Contrary to conventional wisdom that DP optimization fails at learning high-dimensional models (due to noise that scales with dimension) empirical results reveal that private learning with pretrained models tends to not suffer from dimension-dependent performance degradation.