 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Image Fusion via Intervention-Stable Feature Learning
Mar 24, 2026Multi-modal image fusion integrates complementary information from different modalities into a unified representation. Current methods predominantly optimize statistical correlations between modalities, often capturing dataset-induced spurious associations that degrade under distribution shifts. In this paper, we propose an intervention-based framework inspired by causal principles to identify robust cross-modal dependencies. Drawing insights from Pearl's causal hierarchy, we design three principled intervention strategies to probe different aspects of modal relationships: i) complementary masking with spatially disjoint perturbations tests whether modalities can genuinely compensate for each other's missing information, ii) random masking of identical regions identifies feature subsets that remain informative under partial observability, and iii) modality dropout evaluates the irreplaceable contribution of each modality. Based on these interventions, we introduce a Causal Feature Integrator (CFI) that learns to identify and prioritize intervention-stable features maintaining importance across different perturbation patterns through adaptive invariance gating, thereby capturing robust modal dependencies rather than spurious correlations. Extensive experiments demonstrate that our method achieves SOTA performance on both public benchmarks and downstream high-level vision tasks.
Residual Prior-driven Frequency-aware Network for Image Fusion
Jul 09, 2025



Image fusion aims to integrate complementary information across modalities to generate high-quality fused images, thereby enhancing the performance of high-level vision tasks. While global spatial modeling mechanisms show promising results, constructing long-range feature dependencies in the spatial domain incurs substantial computational costs. Additionally, the absence of ground-truth exacerbates the difficulty of capturing complementary features effectively. To tackle these challenges, we propose a Residual Prior-driven Frequency-aware Network, termed as RPFNet. Specifically, RPFNet employs a dual-branch feature extraction framework: the Residual Prior Module (RPM) extracts modality-specific difference information from residual maps, thereby providing complementary priors for fusion; the Frequency Domain Fusion Module (FDFM) achieves efficient global feature modeling and integration through frequency-domain convolution. Additionally, the Cross Promotion Module (CPM) enhances the synergistic perception of local details and global structures through bidirectional feature interaction. During training, we incorporate an auxiliary decoder and saliency structure loss to strengthen the model's sensitivity to modality-specific differences. Furthermore, a combination of adaptive weight-based frequency contrastive loss and SSIM loss effectively constrains the solution space, facilitating the joint capture of local details and global features while ensuring the retention of complementary information. Extensive experiments validate the fusion performance of RPFNet, which effectively integrates discriminative features, enhances texture details and salient objects, and can effectively facilitate the deployment of the high-level vision task.
Quantification of Robotic Surgeries with Vision-Based Deep Learning
May 06, 2022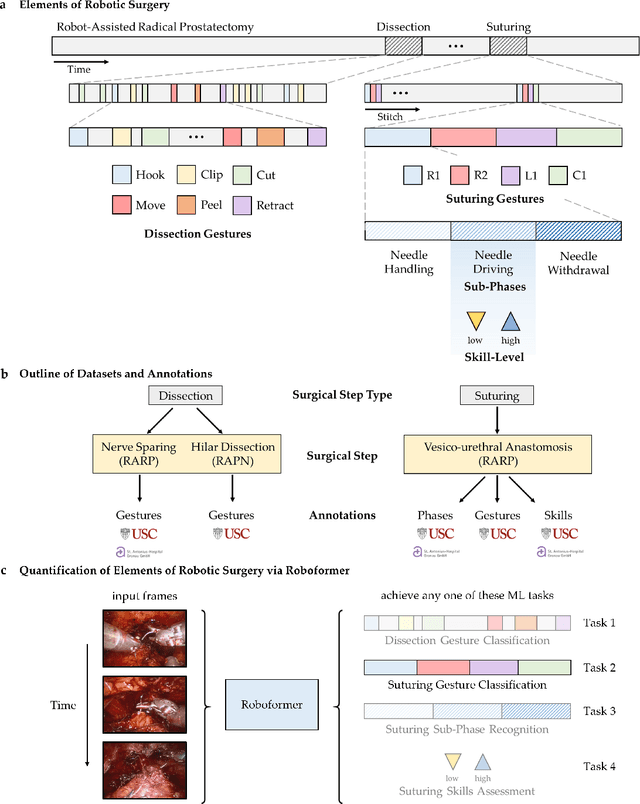
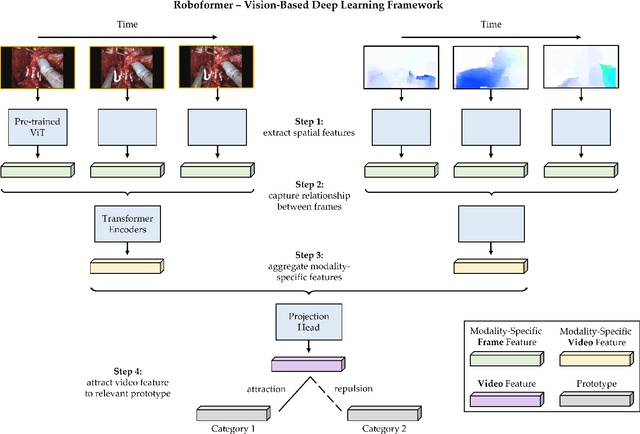
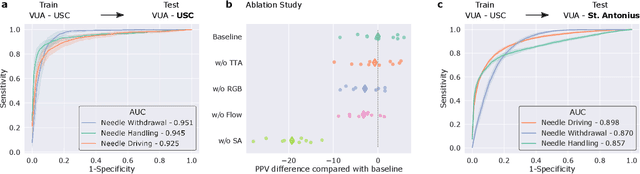
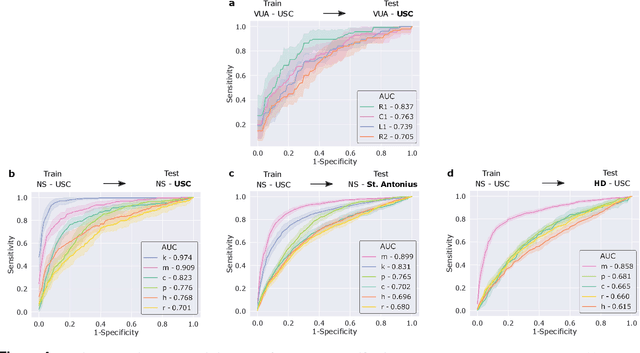
Surgery is a high-stakes domain where surgeons must navigate critical anatomical structures and actively avoid potential complications while achieving the main task at hand. Such surgical activity has been shown to affect long-term patient outcomes. To better understand this relationship, whose mechanics remain unknown for the majority of surgical procedures, we hypothesize that the core elements of surgery must first be quantified in a reliable, objective, and scalable manner. We believe this is a prerequisite for the provision of surgical feedback and modulation of surgeon performance in pursuit of improved patient outcomes. To holistically quantify surgeries, we propose a unified deep learning framework, entitled Roboformer, which operates exclusively on videos recorded during surgery to independently achieve multiple tasks: surgical phase recognition (the what of surgery), gesture classification and skills assessment (the how of surgery). We validated our framework on four video-based datasets of two commonly-encountered types of steps (dissection and suturing) within minimally-invasive robotic surgeries. We demonstrated that our framework can generalize well to unseen videos, surgeons, medical centres, and surgical procedures. We also found that our framework, which naturally lends itself to explainable findings, identified relevant information when achieving a particular task. These findings are likely to instill surgeons with more confidence in our framework's behaviour, increasing the likelihood of clinical adoption, and thus paving the way for more targeted surgical feedback.