 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Intention to Execution: Probing the Generalization Boundaries of Vision-Language-Action Models
Jun 11, 2025One promise that Vision-Language-Action (VLA) models hold over traditional imitation learning for robotics is to leverage the broad generalization capabilities of large Vision-Language Models (VLMs) to produce versatile, "generalist" robot policies. However, current evaluations of VLAs remain insufficient. Traditional imitation learning benchmarks are unsuitable due to the lack of language instructions. Emerging benchmarks for VLAs that incorporate language often come with limited evaluation tasks and do not intend to investigate how much VLM pretraining truly contributes to the generalization capabilities of the downstream robotic policy. Meanwhile, much research relies on real-world robot setups designed in isolation by different institutions, which creates a barrier for reproducibility and accessibility. To address this gap, we introduce a unified probing suite of 50 simulation-based tasks across 10 subcategories spanning language instruction, vision, and objects. We systematically evaluate several state-of-the-art VLA architectures on this suite to understand their generalization capability. Our results show that while VLM backbones endow VLAs with robust perceptual understanding and high level planning, which we refer to as good intentions, this does not reliably translate into precise motor execution: when faced with out-of-distribution observations, policies often exhibit coherent intentions, but falter in action execution. Moreover, finetuning on action data can erode the original VLM's generalist reasoning abilities. We release our task suite and evaluation code to serve as a standardized benchmark for future VLAs and to drive research on closing the perception-to-action gap. More information, including the source code, can be found at https://ai4ce.github.io/INT-ACT/
GARF: Learning Generalizable 3D Reassembly for Real-World Fractures
Apr 07, 20253D reassembly is a challenging spatial intelligence task with broad applications across scientific domains. While large-scale synthetic datasets have fueled promising learning-based approaches, their generalizability to different domains is limited. Critically, it remains uncertain whether models trained on synthetic datasets can generalize to real-world fractures where breakage patterns are more complex. To bridge this gap, we propose GARF, a generalizable 3D reassembly framework for real-world fractures. GARF leverages fracture-aware pretraining to learn fracture features from individual fragments, with flow matching enabling precise 6-DoF alignments. At inference time, we introduce one-step preassembly, improving robustness to unseen objects and varying numbers of fractures. In collaboration with archaeologists, paleoanthropologists, and ornithologists, we curate Fractura, a diverse dataset for vision and learning communities, featuring real-world fracture types across ceramics, bones, eggshells, and lithics. Comprehensive experiments have shown our approach consistently outperforms state-of-the-art methods on both synthetic and real-world datasets, achieving 82.87\% lower rotation error and 25.15\% higher part accuracy. This sheds light on training on synthetic data to advance real-world 3D puzzle solving, demonstrating its strong generalization across unseen object shapes and diverse fracture types.
VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model
Oct 11, 2024Vision Language Models (VLMs) have recently been adopted in robotics for their capability in common sense reasoning and generalizability. Existing work has applied VLMs to generate task and motion planning from natural language instructions and simulate training data for robot learning. In this work, we explore using VLM to interpret human demonstration videos and generate robot task planning. Our method integrates keyframe selection, visual perception, and VLM reasoning into a pipeline. We named it SeeDo because it enables the VLM to ''see'' human demonstrations and explain the corresponding plans to the robot for it to ''do''. To validate our approach, we collected a set of long-horizon human videos demonstrating pick-and-place tasks in three diverse categories and designed a set of metrics to comprehensively benchmark SeeDo against several baselines, including state-of-the-art video-input VLMs. The experiments demonstrate SeeDo's superior performance. We further deployed the generated task plans in both a simulation environment and on a real robot arm.
FusionSense: Bridging Common Sense, Vision, and Touch for Robust Sparse-View Reconstruction
Oct 10, 2024



Humans effortlessly integrate common-sense knowledge with sensory input from vision and touch to understand their surroundings. Emulating this capability, we introduce FusionSense, a novel 3D reconstruction framework that enables robots to fuse priors from foundation models with highly sparse observations from vision and tactile sensors. FusionSense addresses three key challenges: (i) How can robots efficiently acquire robust global shape information about the surrounding scene and objects? (ii) How can robots strategically select touch points on the object using geometric and common-sense priors? (iii) How can partial observations such as tactile signals improve the overall representation of the object? Our framework employs 3D Gaussian Splatting as a core representation and incorporates a hierarchical optimization strategy involving global structure construction, object visual hull pruning and local geometric constraints. This advancement results in fast and robust perception in environments with traditionally challenging objects that are transparent, reflective, or dark, enabling more downstream manipulation or navigation tasks. Experiments on real-world data suggest that our framework outperforms previously state-of-the-art sparse-view methods. All code and data are open-sourced on the project website.
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024



Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
EgoPAT3Dv2: Predicting 3D Action Target from 2D Egocentric Vision for Human-Robot Interaction
Mar 08, 2024



A robot's ability to anticipate the 3D action target location of a hand's movement from egocentric videos can greatly improve safety and efficiency in human-robot interaction (HRI). While previous research predominantly focused on semantic action classification or 2D target region prediction, we argue that predicting the action target's 3D coordinate could pave the way for more versatile downstream robotics tasks, especially given the increasing prevalence of headset devices. This study expands EgoPAT3D, the sole dataset dedicated to egocentric 3D action target prediction. We augment both its size and diversity, enhancing its potential for generalization. Moreover, we substantially enhance the baseline algorithm by introducing a large pre-trained model and human prior knowledge. Remarkably, our novel algorithm can now achieve superior prediction outcomes using solely RGB images, eliminating the previous need for 3D point clouds and IMU input. Furthermore, we deploy our enhanced baseline algorithm on a real-world robotic platform to illustrate its practical utility in straightforward HRI tasks. The demonstrations showcase the real-world applicability of our advancements and may inspire more HRI use cases involving egocentric vision. All code and data are open-sourced and can be found on the project website.
Metric-Free Exploration for Topological Mapping by Task and Motion Imitation in Feature Space
Mar 16, 2023We propose DeepExplorer, a simple and lightweight metric-free exploration method for topological mapping of unknown environments. It performs task and motion planning (TAMP) entirely in image feature space. The task planner is a recurrent network using the latest image observation sequence to hallucinate a feature as the next-best exploration goal. The motion planner then utilizes the current and the hallucinated features to generate an action taking the agent towards that goal. The two planners are jointly trained via deeply-supervised imitation learning from expert demonstrations. During exploration, we iteratively call the two planners to predict the next action, and the topological map is built by constantly appending the latest image observation and action to the map and using visual place recognition (VPR) for loop closing. The resulting topological map efficiently represents an environment's connectivity and traversability, so it can be used for tasks such as visual navigation. We show DeepExplorer's exploration efficiency and strong sim2sim generalization capability on large-scale simulation datasets like Gibson and MP3D. Its effectiveness is further validated via the image-goal navigation performance on the resulting topological map. We further show its strong zero-shot sim2real generalization capability in real-world experiments. The source code is available at \url{https://ai4ce.github.io/DeepExplorer/}.
Dynamic Placement of Rapidly Deployable Mobile Sensor Robots Using Machine Learning and Expected Value of Information
Nov 15, 2021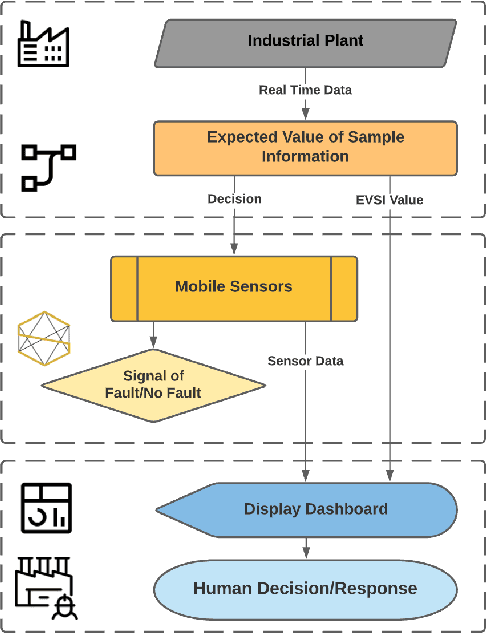
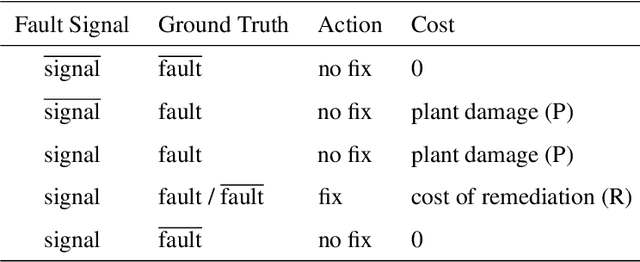
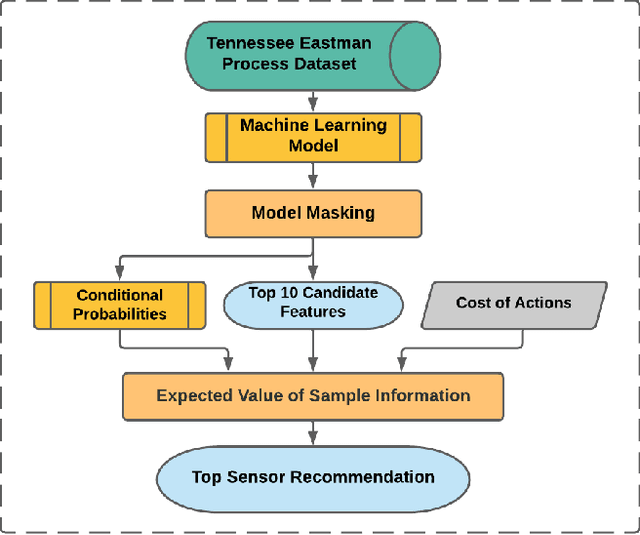
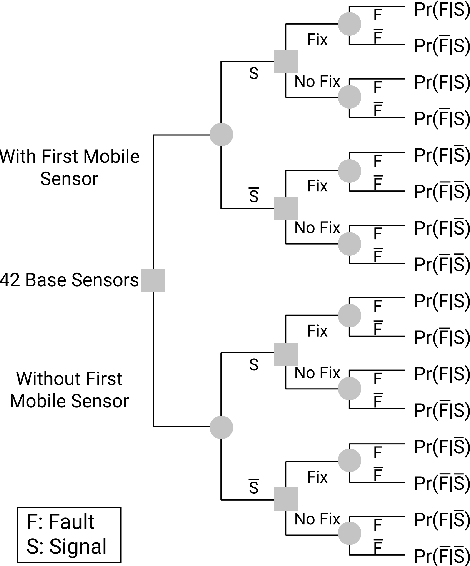
Although the Industrial Internet of Things has increased the number of sensors permanently installed in industrial plants, there will be gaps in coverage due to broken sensors or sparse density in very large plants, such as in the petrochemical industry. Modern emergency response operations are beginning to use Small Unmanned Aerial Systems (sUAS) that have the ability to drop sensor robots to precise locations. sUAS can provide longer-term persistent monitoring that aerial drones are unable to provide. Despite the relatively low cost of these assets, the choice of which robotic sensing systems to deploy to which part of an industrial process in a complex plant environment during emergency response remains challenging. This paper describes a framework for optimizing the deployment of emergency sensors as a preliminary step towards realizing the responsiveness of robots in disaster circumstances. AI techniques (Long short-term memory, 1-dimensional convolutional neural network, logistic regression, and random forest) identify regions where sensors would be most valued without requiring humans to enter the potentially dangerous area. In the case study described, the cost function for optimization considers costs of false-positive and false-negative errors. Decisions on mitigation include implementing repairs or shutting down the plant. The Expected Value of Information (EVI) is used to identify the most valuable type and location of physical sensors to be deployed to increase the decision-analytic value of a sensor network. This method is applied to a case study using the Tennessee Eastman process data set of a chemical plant, and we discuss implications of our findings for operation, distribution, and decision-making of sensors in plant emergency and resilience scenarios.
Multi-modal Ensemble Models for Predicting Video Memorability
Feb 01, 2021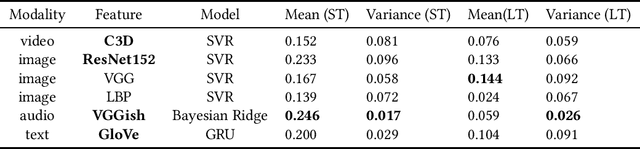
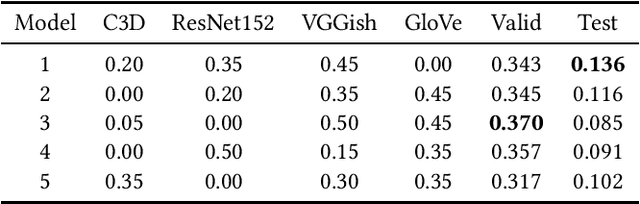
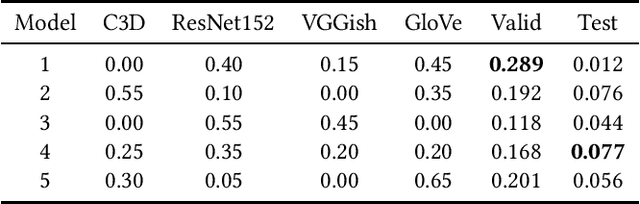
Modeling media memorability has been a consistent challenge in the field of machine learning. The Predicting Media Memorability task in MediaEval2020 is the latest benchmark among similar challenges addressing this topic. Building upon techniques developed in previous iterations of the challenge, we developed ensemble methods with the use of extracted video, image, text, and audio features. Critically, in this work we introduce and demonstrate the efficacy and high generalizability of extracted audio embeddings as a feature for the task of predicting media memorability.