 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Dec 11, 2025Procedural memory enables large language model (LLM) agents to internalize "how-to" knowledge, theoretically reducing redundant trial-and-error. However, existing frameworks predominantly suffer from a "passive accumulation" paradigm, treating memory as a static append-only archive. To bridge the gap between static storage and dynamic reasoning, we propose $\textbf{ReMe}$ ($\textit{Remember Me, Refine Me}$), a comprehensive framework for experience-driven agent evolution. ReMe innovates across the memory lifecycle via three mechanisms: 1) $\textit{multi-faceted distillation}$, which extracts fine-grained experiences by recognizing success patterns, analyzing failure triggers and generating comparative insights; 2) $\textit{context-adaptive reuse}$, which tailors historical insights to new contexts via scenario-aware indexing; and 3) $\textit{utility-based refinement}$, which autonomously adds valid memories and prunes outdated ones to maintain a compact, high-quality experience pool. Extensive experiments on BFCL-V3 and AppWorld demonstrate that ReMe establishes a new state-of-the-art in agent memory system. Crucially, we observe a significant memory-scaling effect: Qwen3-8B equipped with ReMe outperforms larger, memoryless Qwen3-14B, suggesting that self-evolving memory provides a computation-efficient pathway for lifelong learning. We release our code and the $\texttt{reme.library}$ dataset to facilitate further research.
AgentEvolver: Towards Efficient Self-Evolving Agent System
Nov 13, 2025Autonomous agents powered by large language models (LLMs) have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
Less is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning
May 29, 2025Scaling laws motivate the development of Time Series Foundation Models (TSFMs) that pre-train vast parameters and achieve remarkable zero-shot forecasting performance. Surprisingly, even after fine-tuning, TSFMs cannot consistently outperform smaller, specialized models trained on full-shot downstream data. A key question is how to realize effective adaptation of TSFMs for a target forecasting task. Through empirical studies on various TSFMs, the pre-trained models often exhibit inherent sparsity and redundancy in computation, suggesting that TSFMs have learned to activate task-relevant network substructures to accommodate diverse forecasting tasks. To preserve this valuable prior knowledge, we propose a structured pruning method to regularize the subsequent fine-tuning process by focusing it on a more relevant and compact parameter space. Extensive experiments on seven TSFMs and six benchmarks demonstrate that fine-tuning a smaller, pruned TSFM significantly improves forecasting performance compared to fine-tuning original models. This "prune-then-finetune" paradigm often enables TSFMs to achieve state-of-the-art performance and surpass strong specialized baselines.
Ground Every Sentence: Improving Retrieval-Augmented LLMs with Interleaved Reference-Claim Generation
Jul 01, 2024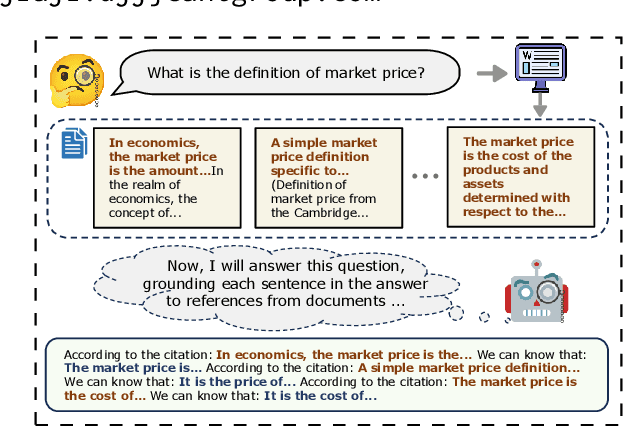
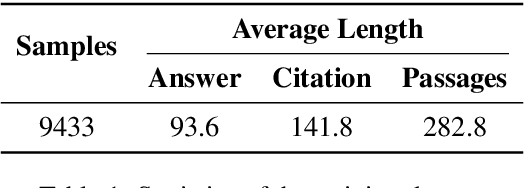
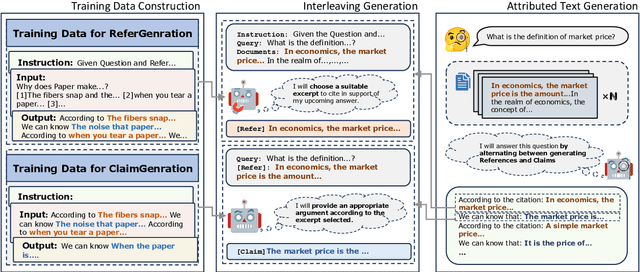
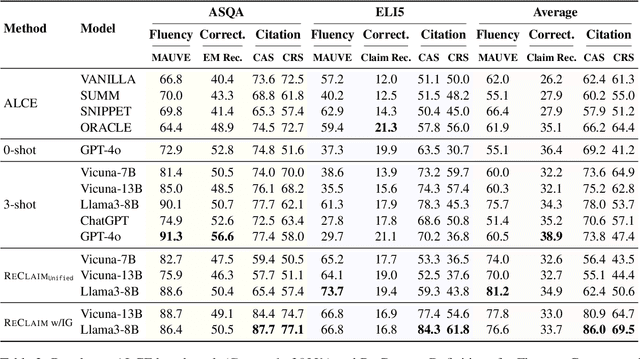
Retrieval-Augmented Generation (RAG) has been widely adopted to enhance Large Language Models (LLMs) in knowledge-intensive tasks. Recently, Attributed Text Generation (ATG) has attracted growing attention, which provides citations to support the model's responses in RAG, so as to enhance the credibility of LLM-generated content and facilitate verification. Prior methods mainly adopt coarse-grained attributions, linking to passage-level references or providing paragraph-level citations. However, these methods still fall short in verifiability and require certain time costs for fact checking. This paper proposes a fine-grained ATG method called ReClaim(Refer & Claim), which alternates the generation of references and answers step by step. Unlike traditional coarse-grained attribution, ReClaim allows the model to add sentence-level fine-grained citations to each answer sentence in long-form question-answering tasks. Our experiments encompass various training and inference methods and multiple LLMs, verifying the effectiveness of our approach.