 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022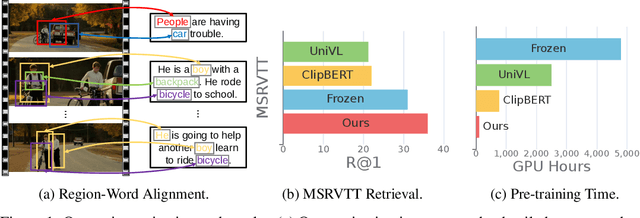
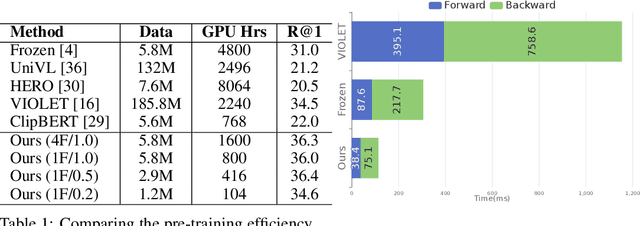
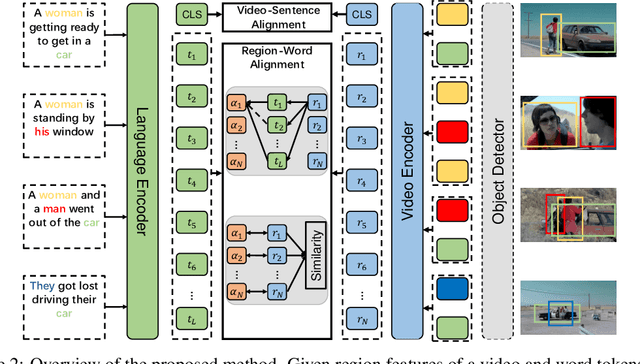

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
All in One: Exploring Unified Video-Language Pre-training
Mar 14, 2022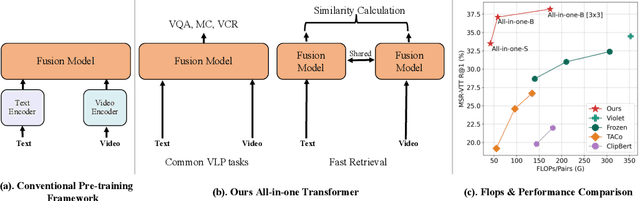
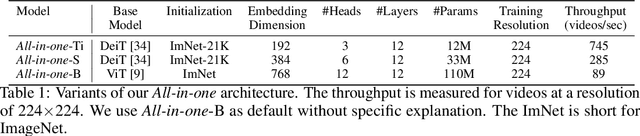
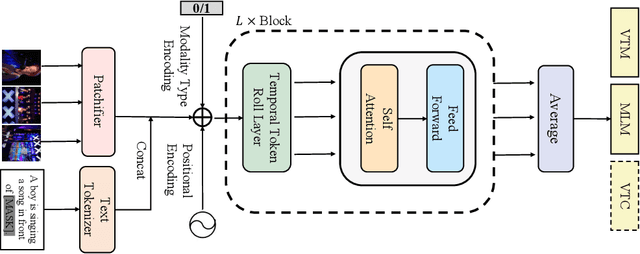
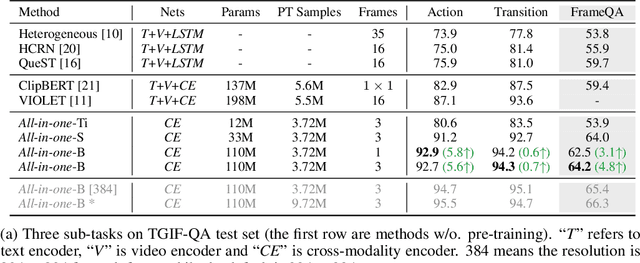
Mainstream Video-Language Pre-training models \cite{actbert,clipbert,violet} consist of three parts, a video encoder, a text encoder, and a video-text fusion Transformer. They pursue better performance via utilizing heavier unimodal encoders or multimodal fusion Transformers, resulting in increased parameters with lower efficiency in downstream tasks. In this work, we for the first time introduce an end-to-end video-language model, namely \textit{all-in-one Transformer}, that embeds raw video and textual signals into joint representations using a unified backbone architecture. We argue that the unique temporal information of video data turns out to be a key barrier hindering the design of a modality-agnostic Transformer. To overcome the challenge, we introduce a novel and effective token rolling operation to encode temporal representations from video clips in a non-parametric manner. The careful design enables the representation learning of both video-text multimodal inputs and unimodal inputs using a unified backbone model. Our pre-trained all-in-one Transformer is transferred to various downstream video-text tasks after fine-tuning, including text-video retrieval, video-question answering, multiple choice and visual commonsense reasoning. State-of-the-art performances with the minimal model FLOPs on nine datasets demonstrate the superiority of our method compared to the competitive counterparts. The code and pretrained model have been released in https://github.com/showlab/all-in-one.
Learning To Recognize Procedural Activities with Distant Supervision
Jan 26, 2022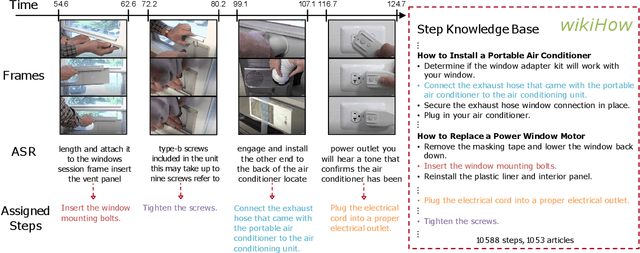

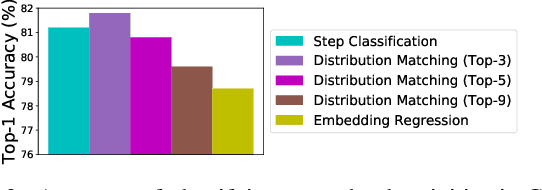

In this paper we consider the problem of classifying fine-grained, multi-step activities (e.g., cooking different recipes, making disparate home improvements, creating various forms of arts and crafts) from long videos spanning up to several minutes. Accurately categorizing these activities requires not only recognizing the individual steps that compose the task but also capturing their temporal dependencies. This problem is dramatically different from traditional action classification, where models are typically optimized on videos that span only a few seconds and that are manually trimmed to contain simple atomic actions. While step annotations could enable the training of models to recognize the individual steps of procedural activities, existing large-scale datasets in this area do not include such segment labels due to the prohibitive cost of manually annotating temporal boundaries in long videos. To address this issue, we propose to automatically identify steps in instructional videos by leveraging the distant supervision of a textual knowledge base (wikiHow) that includes detailed descriptions of the steps needed for the execution of a wide variety of complex activities. Our method uses a language model to match noisy, automatically-transcribed speech from the video to step descriptions in the knowledge base. We demonstrate that video models trained to recognize these automatically-labeled steps (without manual supervision) yield a representation that achieves superior generalization performance on four downstream tasks: recognition of procedural activities, step classification, step forecasting and egocentric video classification.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
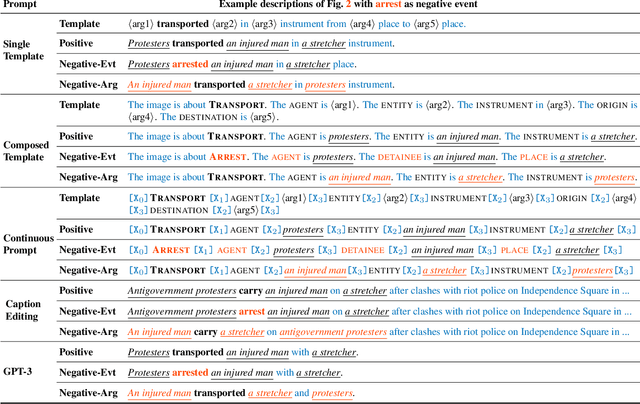
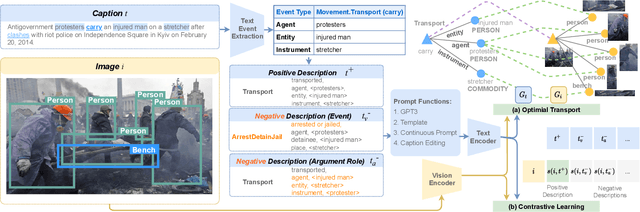

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
MuMuQA: Multimedia Multi-Hop News Question Answering via Cross-Media Knowledge Extraction and Grounding
Dec 20, 2021

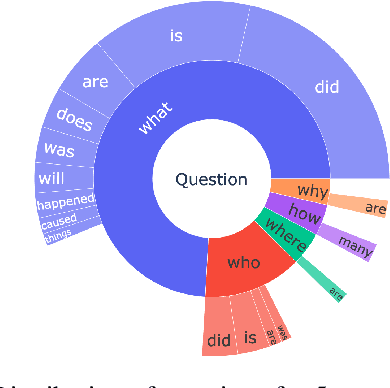
Recently, there has been an increasing interest in building question answering (QA) models that reason across multiple modalities, such as text and images. However, QA using images is often limited to just picking the answer from a pre-defined set of options. In addition, images in the real world, especially in news, have objects that are co-referential to the text, with complementary information from both modalities. In this paper, we present a new QA evaluation benchmark with 1,384 questions over news articles that require cross-media grounding of objects in images onto text. Specifically, the task involves multi-hop questions that require reasoning over image-caption pairs to identify the grounded visual object being referred to and then predicting a span from the news body text to answer the question. In addition, we introduce a novel multimedia data augmentation framework, based on cross-media knowledge extraction and synthetic question-answer generation, to automatically augment data that can provide weak supervision for this task. We evaluate both pipeline-based and end-to-end pretraining-based multimedia QA models on our benchmark, and show that they achieve promising performance, while considerably lagging behind human performance hence leaving large room for future work on this challenging new task.
Video-Text Pre-training with Learned Regions
Dec 06, 2021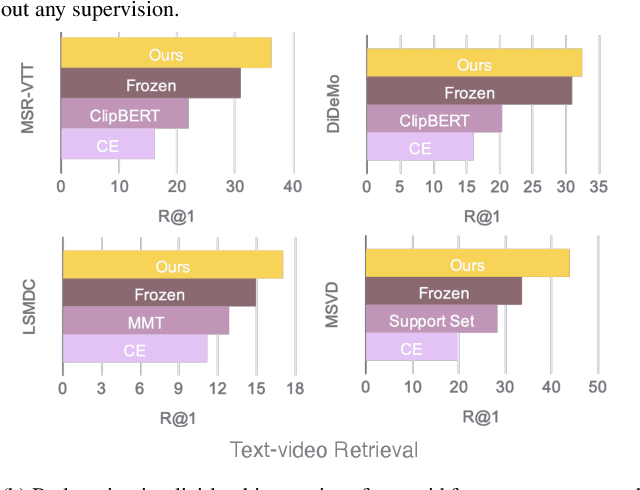
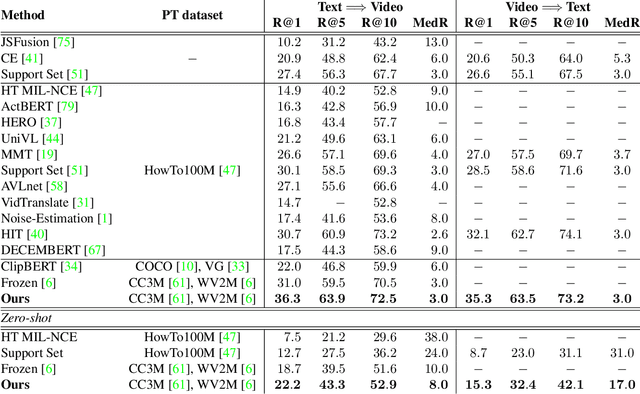
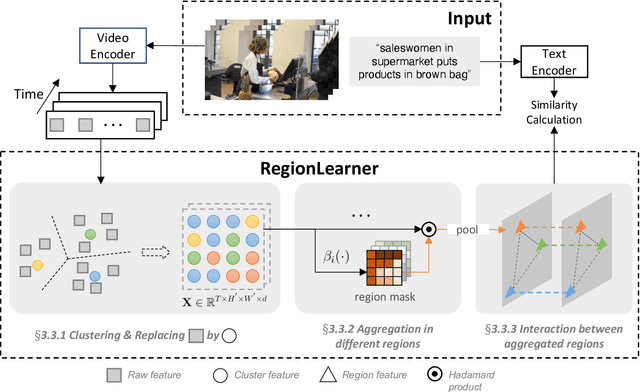
Video-Text pre-training aims at learning transferable representations from large-scale video-text pairs via aligning the semantics between visual and textual information. State-of-the-art approaches extract visual features from raw pixels in an end-to-end fashion. However, these methods operate at frame-level directly and thus overlook the spatio-temporal structure of objects in video, which yet has a strong synergy with nouns in textual descriptions. In this work, we propose a simple yet effective module for video-text representation learning, namely RegionLearner, which can take into account the structure of objects during pre-training on large-scale video-text pairs. Given a video, our module (1) first quantizes visual features into semantic clusters, then (2) generates learnable masks and uses them to aggregate the features belonging to the same semantic region, and finally (3) models the interactions between different aggregated regions. In contrast to using off-the-shelf object detectors, our proposed module does not require explicit supervision and is much more computationally efficient. We pre-train the proposed approach on the public WebVid2M and CC3M datasets. Extensive evaluations on four downstream video-text retrieval benchmarks clearly demonstrate the effectiveness of our RegionLearner. The code will be available at https://github.com/ruiyan1995/Region_Learner.
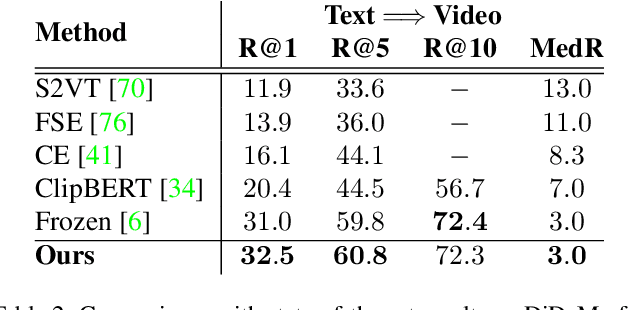
Object-aware Video-language Pre-training for Retrieval
Dec 06, 2021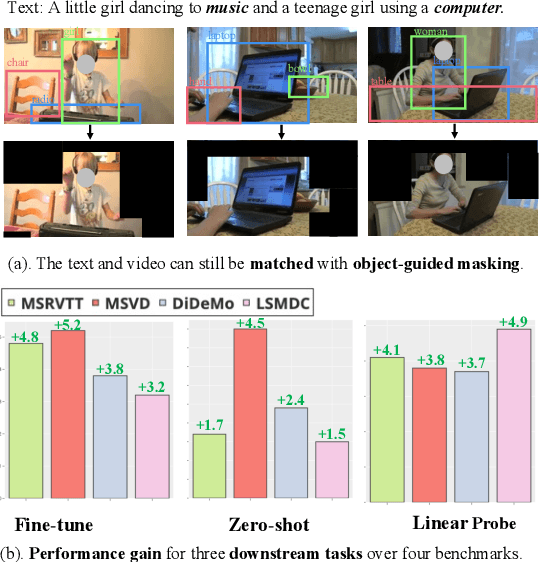
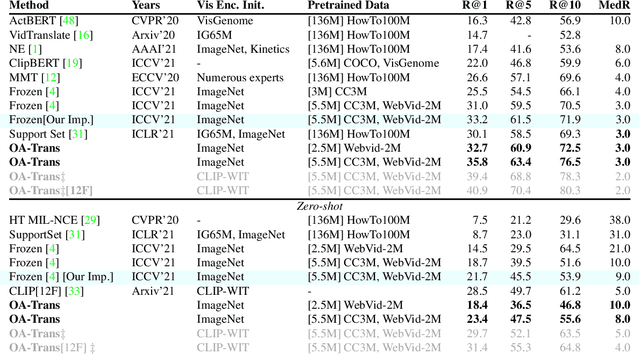
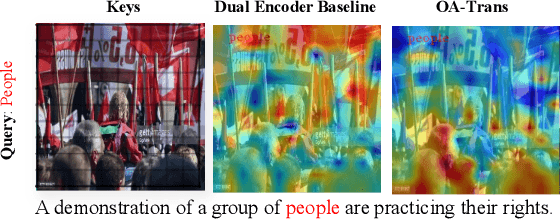
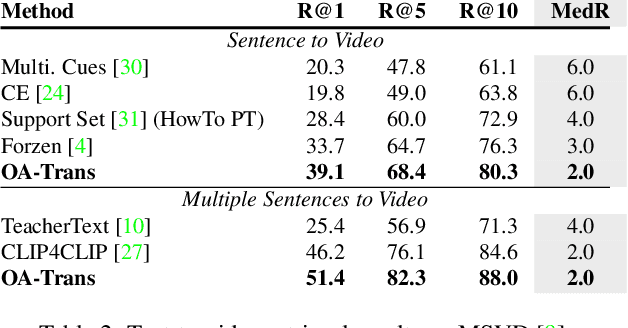
Recently, by introducing large-scale dataset and strong transformer network, video-language pre-training has shown great success especially for retrieval. Yet, existing video-language transformer models do not explicitly fine-grained semantic align. In this work, we present Object-aware Transformers, an object-centric approach that extends video-language transformer to incorporate object representations. The key idea is to leverage the bounding boxes and object tags to guide the training process. We evaluate our model on three standard sub-tasks of video-text matching on four widely used benchmarks. We also provide deep analysis and detailed ablation about the proposed method. We show clear improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a video-language architecture. The code will be released at \url{https://github.com/FingerRec/OA-Transformer}.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021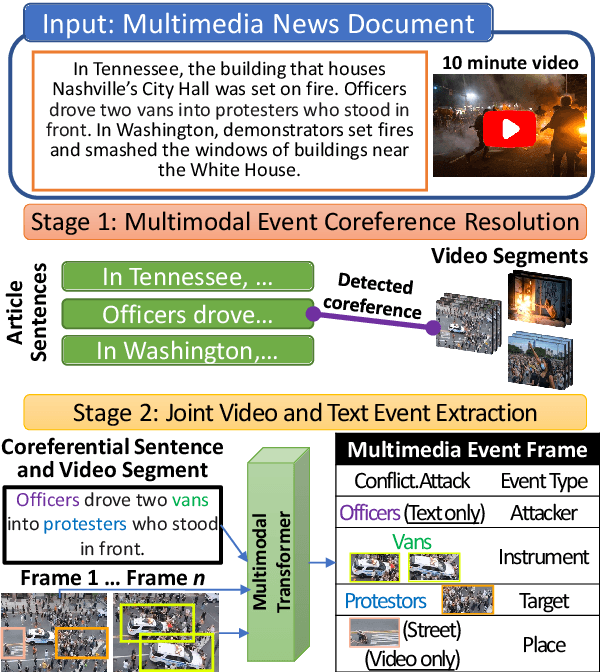


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.
Co-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
Mar 23, 2021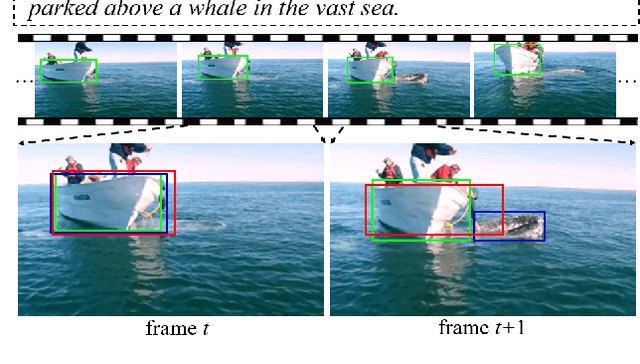
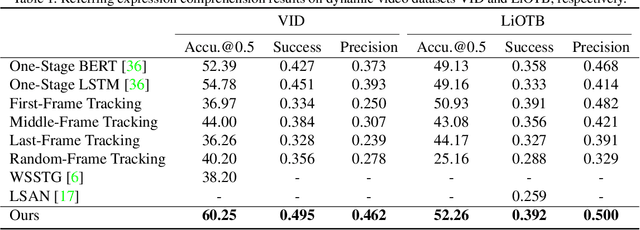
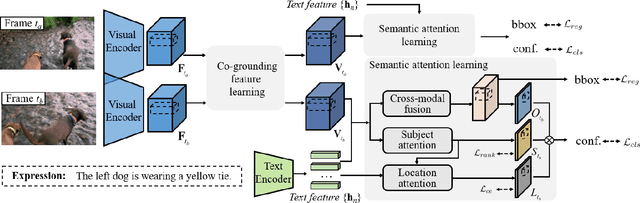
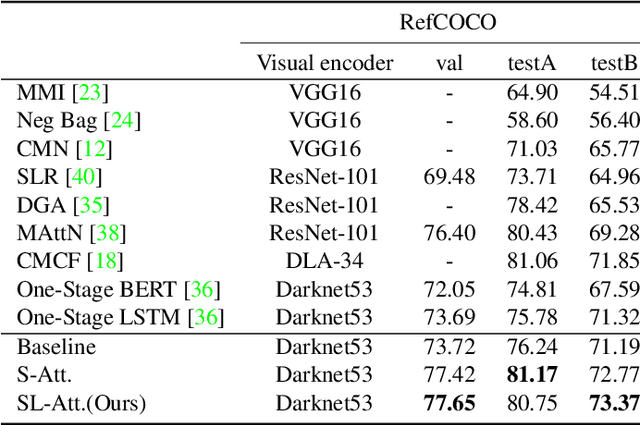
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, \textbf{co-grounding}, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and LiOTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
Jan 29, 2021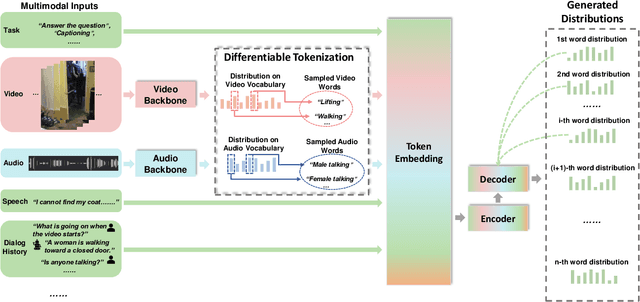



We present \textsc{Vx2Text}, a framework for text generation from multimodal inputs consisting of video plus text, speech, or audio. In order to leverage transformer networks, which have been shown to be effective at modeling language, each modality is first converted into a set of language embeddings by a learnable tokenizer. This allows our approach to perform multimodal fusion in the language space, thus eliminating the need for ad-hoc cross-modal fusion modules. To address the non-differentiability of tokenization on continuous inputs (e.g., video or audio), we utilize a relaxation scheme that enables end-to-end training. Furthermore, unlike prior encoder-only models, our network includes an autoregressive decoder to generate open-ended text from the multimodal embeddings fused by the language encoder. This renders our approach fully generative and makes it directly applicable to different "video+$x$ to text" problems without the need to design specialized network heads for each task. The proposed framework is not only conceptually simple but also remarkably effective: experiments demonstrate that our approach based on a single architecture outperforms the state-of-the-art on three video-based text-generation tasks -- captioning, question answering and audio-visual scene-aware dialog.