 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on the Trustworthiness of Large Language Models in Healthcare
Feb 21, 2025The application of large language models (LLMs) in healthcare has the potential to revolutionize clinical decision-making, medical research, and patient care. As LLMs are increasingly integrated into healthcare systems, several critical challenges must be addressed to ensure their reliable and ethical deployment. These challenges include truthfulness, where models generate misleading information; privacy, with risks of unintentional data retention; robustness, requiring defenses against adversarial attacks; fairness, addressing biases in clinical outcomes; explainability, ensuring transparent decision-making; and safety, mitigating risks of misinformation and medical errors. Recently, researchers have begun developing benchmarks and evaluation frameworks to systematically assess the trustworthiness of LLMs. However, the trustworthiness of LLMs in healthcare remains underexplored, lacking a systematic review that provides a comprehensive understanding and future insights into this area. This survey bridges this gap by providing a comprehensive overview of the recent research of existing methodologies and solutions aimed at mitigating the above risks in healthcare. By focusing on key trustworthiness dimensions including truthfulness, privacy and safety, robustness, fairness and bias, and explainability, we present a thorough analysis of how these issues impact the reliability and ethical use of LLMs in healthcare. This paper highlights ongoing efforts and offers insights into future research directions to ensure the safe and trustworthy deployment of LLMs in healthcare.
Towards Reasoning Ability of Small Language Models
Feb 17, 2025Reasoning has long been viewed as an emergent property of large language models (LLMs), appearing at or above a certain scale ($\sim$100B parameters). However, recent studies challenge this assumption, showing that small language models (SLMs) can also achieve competitive reasoning performance. SLMs are increasingly favored for their efficiency and deployability. However, there is a lack of systematic study on the reasoning abilities of diverse SLMs, including those trained from scratch or derived from LLMs through quantization, pruning, and distillation. This raises a critical question: Can SLMs achieve reasoning abilities comparable to LLMs? In this work, we systematically survey, benchmark, and analyze 72 SLMs from six model families across 14 reasoning benchmarks. For reliable evaluation, we examine four evaluation methods and compare four LLM judges against human evaluations on 800 data points. We repeat all experiments three times to ensure a robust performance assessment. Additionally, we analyze the impact of different prompting strategies in small models. Beyond accuracy, we also evaluate model robustness under adversarial conditions and intermediate reasoning steps. Our findings challenge the assumption that scaling is the only way to achieve strong reasoning. Instead, we foresee a future where SLMs with strong reasoning capabilities can be developed through structured training or post-training compression. They can serve as efficient alternatives to LLMs for reasoning-intensive tasks.
Joint Pricing and Resource Allocation: An Optimal Online-Learning Approach
Jan 29, 2025We study an online learning problem on dynamic pricing and resource allocation, where we make joint pricing and inventory decisions to maximize the overall net profit. We consider the stochastic dependence of demands on the price, which complicates the resource allocation process and introduces significant non-convexity and non-smoothness to the problem. To solve this problem, we develop an efficient algorithm that utilizes a "Lower-Confidence Bound (LCB)" meta-strategy over multiple OCO agents. Our algorithm achieves $\tilde{O}(\sqrt{Tmn})$ regret (for $m$ suppliers and $n$ consumers), which is optimal with respect to the time horizon $T$. Our results illustrate an effective integration of statistical learning methodologies with complex operations research problems.
LiveIdeaBench: Evaluating LLMs' Scientific Creativity and Idea Generation with Minimal Context
Dec 23, 2024

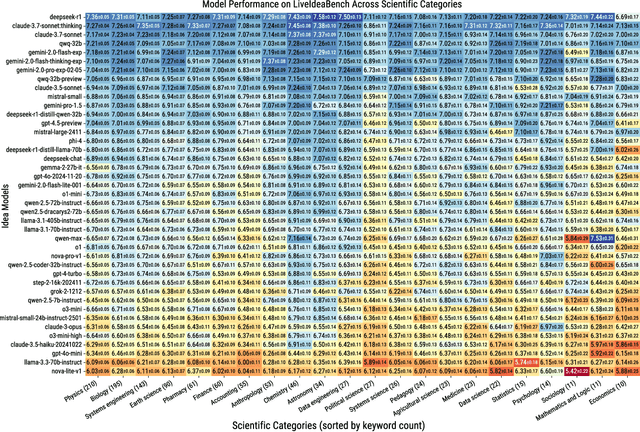
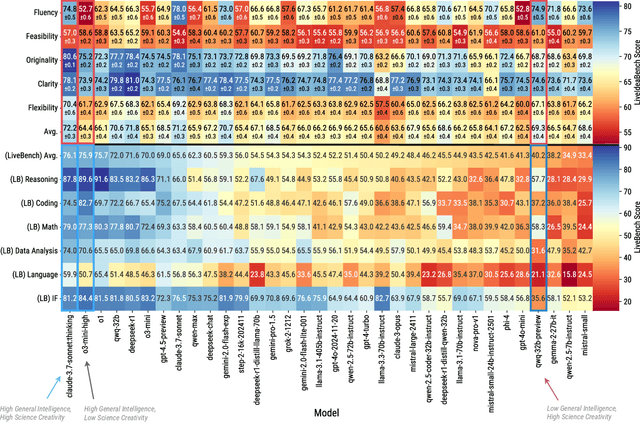
While Large Language Models (LLMs) have demonstrated remarkable capabilities in scientific tasks, existing evaluation frameworks primarily assess their performance using rich contextual inputs, overlooking their ability to generate novel ideas from minimal information. We introduce LiveIdeaBench, a comprehensive benchmark that evaluates LLMs' scientific creativity and divergent thinking capabilities using single-keyword prompts. Drawing from Guilford's creativity theory, our framework employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across four key dimensions: originality, feasibility, fluency, and flexibility. Through extensive experimentation with 20 leading models across 1,180 keywords spanning 18 scientific domains, we reveal that scientific creative ability shows distinct patterns from general intelligence metrics. Notably, our results demonstrate that models like QwQ-32B-preview achieve comparable creative performance to top-tier models like o1-preview, despite significant gaps in their general intelligence scores. These findings highlight the importance of specialized evaluation frameworks for scientific creativity and suggest that the development of creative capabilities in LLMs may follow different trajectories than traditional problem-solving abilities.
Generating Unseen Nonlinear Evolution in Sea Surface Temperature Using a Deep Learning-Based Latent Space Data Assimilation Framework
Dec 18, 2024



Advances in data assimilation (DA) methods have greatly improved the accuracy of Earth system predictions. To fuse multi-source data and reconstruct the nonlinear evolution missing from observations, geoscientists are developing future-oriented DA methods. In this paper, we redesign a purely data-driven latent space DA framework (DeepDA) that employs a generative artificial intelligence model to capture the nonlinear evolution in sea surface temperature. Under variational constraints, DeepDA embedded with nonlinear features can effectively fuse heterogeneous data. The results show that DeepDA remains highly stable in capturing and generating nonlinear evolutions even when a large amount of observational information is missing. It can be found that when only 10% of the observation information is available, the error increase of DeepDA does not exceed 40%. Furthermore, DeepDA has been shown to be robust in the fusion of real observations and ensemble simulations. In particular, this paper provides a mechanism analysis of the nonlinear evolution generated by DeepDA from the perspective of physical patterns, which reveals the inherent explainability of our DL model in capturing multi-scale ocean signals.
SusGen-GPT: A Data-Centric LLM for Financial NLP and Sustainability Report Generation
Dec 14, 2024The rapid growth of the financial sector and the rising focus on Environmental, Social, and Governance (ESG) considerations highlight the need for advanced NLP tools. However, open-source LLMs proficient in both finance and ESG domains remain scarce. To address this gap, we introduce SusGen-30K, a category-balanced dataset comprising seven financial NLP tasks and ESG report generation, and propose TCFD-Bench, a benchmark for evaluating sustainability report generation. Leveraging this dataset, we developed SusGen-GPT, a suite of models achieving state-of-the-art performance across six adapted and two off-the-shelf tasks, trailing GPT-4 by only 2% despite using 7-8B parameters compared to GPT-4's 1,700B. Based on this, we propose the SusGen system, integrated with Retrieval-Augmented Generation (RAG), to assist in sustainability report generation. This work demonstrates the efficiency of our approach, advancing research in finance and ESG.
Self-Ensembling Gaussian Splatting for Few-shot Novel View Synthesis
Oct 31, 2024



3D Gaussian Splatting (3DGS) has demonstrated remarkable effectiveness for novel view synthesis (NVS). However, the 3DGS model tends to overfit when trained with sparse posed views, limiting its generalization capacity for broader pose variations. In this paper, we alleviate the overfitting problem by introducing a self-ensembling Gaussian Splatting (SE-GS) approach. We present two Gaussian Splatting models named the $\mathbf{\Sigma}$-model and the $\mathbf{\Delta}$-model. The $\mathbf{\Sigma}$-model serves as the primary model that generates novel-view images during inference. At the training stage, the $\mathbf{\Sigma}$-model is guided away from specific local optima by an uncertainty-aware perturbing strategy. We dynamically perturb the $\mathbf{\Delta}$-model based on the uncertainties of novel-view renderings across different training steps, resulting in diverse temporal models sampled from the Gaussian parameter space without additional training costs. The geometry of the $\mathbf{\Sigma}$-model is regularized by penalizing discrepancies between the $\mathbf{\Sigma}$-model and the temporal samples. Therefore, our SE-GS conducts an effective and efficient regularization across a large number of Gaussian Splatting models, resulting in a robust ensemble, the $\mathbf{\Sigma}$-model. Experimental results on the LLFF, Mip-NeRF360, DTU, and MVImgNet datasets show that our approach improves NVS quality with few-shot training views, outperforming existing state-of-the-art methods. The code is released at https://github.com/sailor-z/SE-GS.
Heterogeneous Team Coordination on Partially Observable Graphs with Realistic Communication
Oct 29, 2024


Team Coordination on Graphs with Risky Edges (\textsc{tcgre}) is a recently proposed problem, in which robots find paths to their goals while considering possible coordination to reduce overall team cost. However, \textsc{tcgre} assumes that the \emph{entire} environment is available to a \emph{homogeneous} robot team with \emph{ubiquitous} communication. In this paper, we study an extended version of \textsc{tcgre}, called \textsc{hpr-tcgre}, with three relaxations: Heterogeneous robots, Partial observability, and Realistic communication. To this end, we form a new combinatorial optimization problem on top of \textsc{tcgre}. After analysis, we divide it into two sub-problems, one for robots moving individually, another for robots in groups, depending on their communication availability. Then, we develop an algorithm that exploits real-time partial maps to solve local shortest path(s) problems, with a A*-like sub-goal(s) assignment mechanism that explores potential coordination opportunities for global interests. Extensive experiments indicate that our algorithm is able to produce team coordination behaviors in order to reduce overall cost even with our three relaxations.
MIBench: A Comprehensive Benchmark for Model Inversion Attack and Defense
Oct 07, 2024Model Inversion (MI) attacks aim at leveraging the output information of target models to reconstruct privacy-sensitive training data, raising widespread concerns on privacy threats of Deep Neural Networks (DNNs). Unfortunately, in tandem with the rapid evolution of MI attacks, the lack of a comprehensive, aligned, and reliable benchmark has emerged as a formidable challenge. This deficiency leads to inadequate comparisons between different attack methods and inconsistent experimental setups. In this paper, we introduce the first practical benchmark for model inversion attacks and defenses to address this critical gap, which is named \textit{MIBench}. This benchmark serves as an extensible and reproducible modular-based toolbox and currently integrates a total of 16 state-of-the-art attack and defense methods. Moreover, we furnish a suite of assessment tools encompassing 9 commonly used evaluation protocols to facilitate standardized and fair evaluation and analysis. Capitalizing on this foundation, we conduct extensive experiments from multiple perspectives to holistically compare and analyze the performance of various methods across different scenarios, which overcomes the misalignment issues and discrepancy prevalent in previous works. Based on the collected attack methods and defense strategies, we analyze the impact of target resolution, defense robustness, model predictive power, model architectures, transferability and loss function. Our hope is that this \textit{MIBench} could provide a unified, practical and extensible toolbox and is widely utilized by researchers in the field to rigorously test and compare their novel methods, ensuring equitable evaluations and thereby propelling further advancements in the future development.
Causality-based Subject and Task Fingerprints using fMRI Time-series Data
Sep 26, 2024Recently, there has been a revived interest in system neuroscience causation models due to their unique capability to unravel complex relationships in multi-scale brain networks. In this paper, our goal is to verify the feasibility and effectiveness of using a causality-based approach for fMRI fingerprinting. Specifically, we propose an innovative method that utilizes the causal dynamics activities of the brain to identify the unique cognitive patterns of individuals (e.g., subject fingerprint) and fMRI tasks (e.g., task fingerprint). The key novelty of our approach stems from the development of a two-timescale linear state-space model to extract 'spatio-temporal' (aka causal) signatures from an individual's fMRI time series data. To the best of our knowledge, we pioneer and subsequently quantify, in this paper, the concept of 'causal fingerprint.' Our method is well-separated from other fingerprint studies as we quantify fingerprints from a cause-and-effect perspective, which are then incorporated with a modal decomposition and projection method to perform subject identification and a GNN-based (Graph Neural Network) model to perform task identification. Finally, we show that the experimental results and comparisons with non-causality-based methods demonstrate the effectiveness of the proposed methods. We visualize the obtained causal signatures and discuss their biological relevance in light of the existing understanding of brain functionalities. Collectively, our work paves the way for further studies on causal fingerprints with potential applications in both healthy controls and neurodegenerative diseases.