 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualizing Multiple Tasks via Learning to Decompose
Jun 15, 2021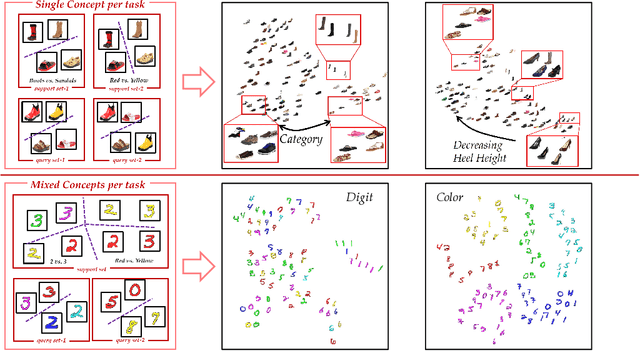

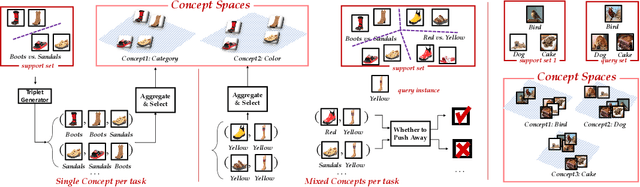

One single instance could possess multiple portraits and reveal diverse relationships with others according to different contexts. Those ambiguities increase the difficulty of learning a generalizable model when there exists one concept or mixed concepts in a task. We propose a general approach Learning to Decompose Network (LeadNet) for both two cases, which contextualizes a model through meta-learning multiple maps for concepts discovery -- the representations of instances are decomposed and adapted conditioned on the contexts. Through taking a holistic view over multiple latent components over instances in a sampled pseudo task, LeadNet learns to automatically select the right concept via incorporating those rich semantics inside and between objects. LeadNet demonstrates its superiority in various applications, including exploring multiple views of confusing tasks, out-of-distribution recognition, and few-shot image classification.
Distilling Virtual Examples for Long-tailed Recognition
Mar 28, 2021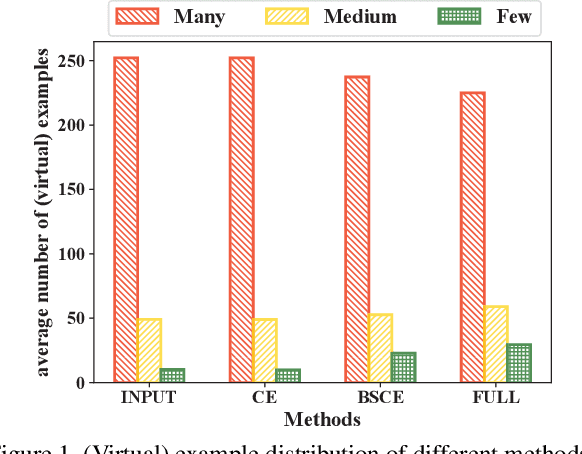
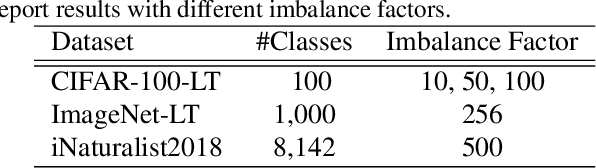
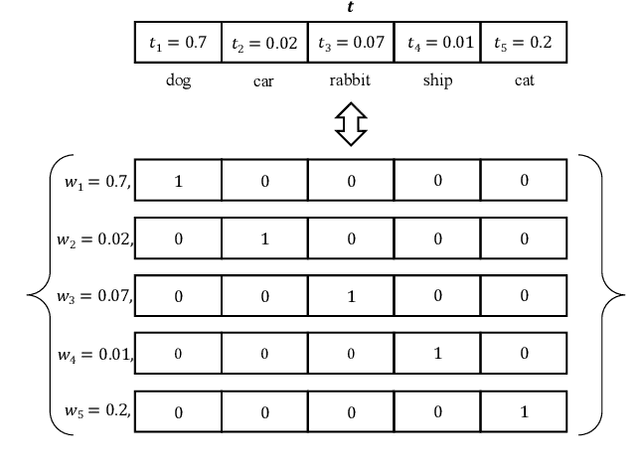
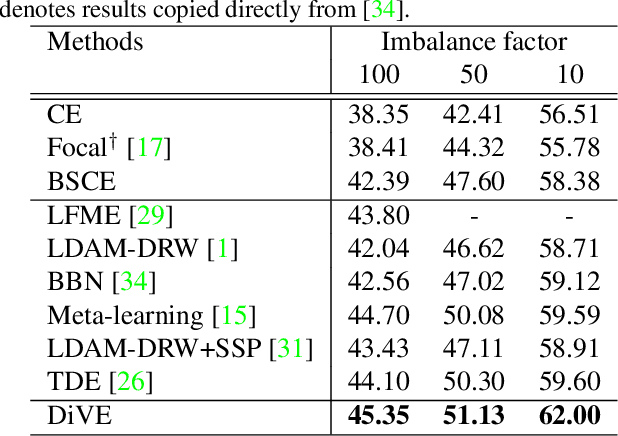
In this paper, we tackle the long-tailed visual recognition problem from the knowledge distillation perspective by proposing a Distill the Virtual Examples (DiVE) method. Specifically, by treating the predictions of a teacher model as virtual examples, we prove that distilling from these virtual examples is equivalent to label distribution learning under certain constraints. We show that when the virtual example distribution becomes flatter than the original input distribution, the under-represented tail classes will receive significant improvements, which is crucial in long-tailed recognition. The proposed DiVE method can explicitly tune the virtual example distribution to become flat. Extensive experiments on three benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed DiVE method can significantly outperform state-of-the-art methods. Furthermore, additional analyses and experiments verify the virtual example interpretation, and demonstrate the effectiveness of tailored designs in DiVE for long-tailed problems.
Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification
Mar 26, 2021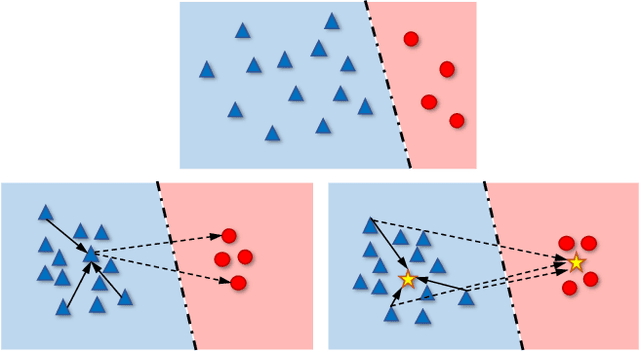
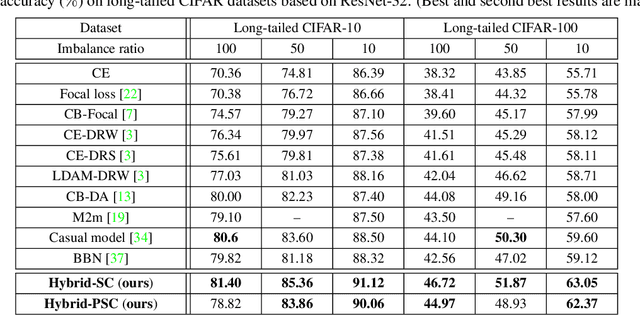
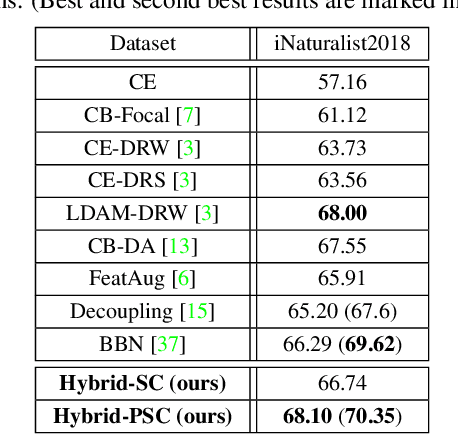

Learning discriminative image representations plays a vital role in long-tailed image classification because it can ease the classifier learning in imbalanced cases. Given the promising performance contrastive learning has shown recently in representation learning, in this work, we explore effective supervised contrastive learning strategies and tailor them to learn better image representations from imbalanced data in order to boost the classification accuracy thereon. Specifically, we propose a novel hybrid network structure being composed of a supervised contrastive loss to learn image representations and a cross-entropy loss to learn classifiers, where the learning is progressively transited from feature learning to the classifier learning to embody the idea that better features make better classifiers. We explore two variants of contrastive loss for feature learning, which vary in the forms but share a common idea of pulling the samples from the same class together in the normalized embedding space and pushing the samples from different classes apart. One of them is the recently proposed supervised contrastive (SC) loss, which is designed on top of the state-of-the-art unsupervised contrastive loss by incorporating positive samples from the same class. The other is a prototypical supervised contrastive (PSC) learning strategy which addresses the intensive memory consumption in standard SC loss and thus shows more promise under limited memory budget. Extensive experiments on three long-tailed classification datasets demonstrate the advantage of the proposed contrastive learning based hybrid networks in long-tailed classification.
Tips and Tricks for Webly-Supervised Fine-Grained Recognition: Learning from the WebFG 2020 Challenge
Dec 29, 2020
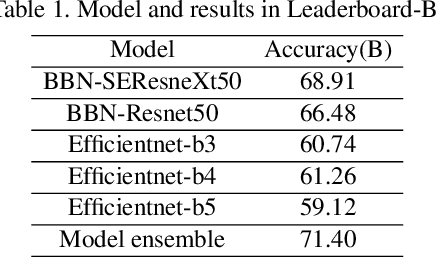

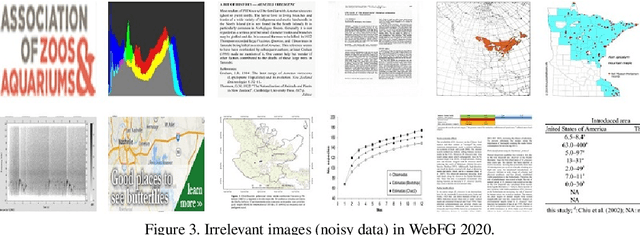
WebFG 2020 is an international challenge hosted by Nanjing University of Science and Technology, University of Edinburgh, Nanjing University, The University of Adelaide, Waseda University, etc. This challenge mainly pays attention to the webly-supervised fine-grained recognition problem. In the literature, existing deep learning methods highly rely on large-scale and high-quality labeled training data, which poses a limitation to their practicability and scalability in real world applications. In particular, for fine-grained recognition, a visual task that requires professional knowledge for labeling, the cost of acquiring labeled training data is quite high. It causes extreme difficulties to obtain a large amount of high-quality training data. Therefore, utilizing free web data to train fine-grained recognition models has attracted increasing attentions from researchers in the fine-grained community. This challenge expects participants to develop webly-supervised fine-grained recognition methods, which leverages web images in training fine-grained recognition models to ease the extreme dependence of deep learning methods on large-scale manually labeled datasets and to enhance their practicability and scalability. In this technical report, we have pulled together the top WebFG 2020 solutions of total 54 competing teams, and discuss what methods worked best across the set of winning teams, and what surprisingly did not help.
Salvage Reusable Samples from Noisy Data for Robust Learning
Aug 06, 2020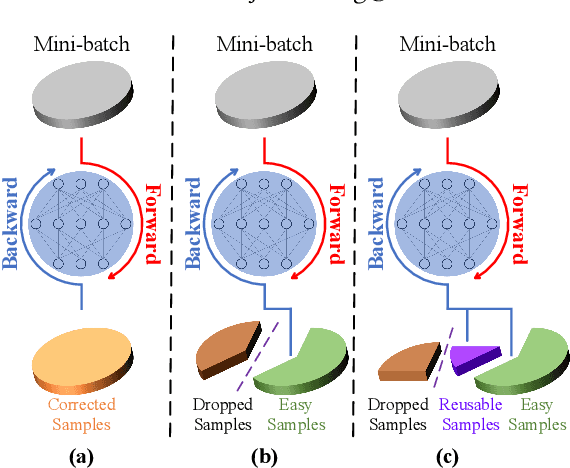
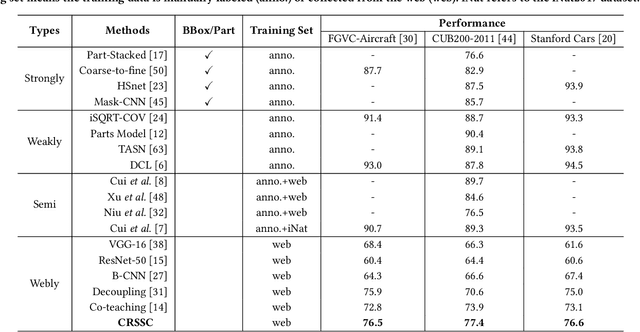
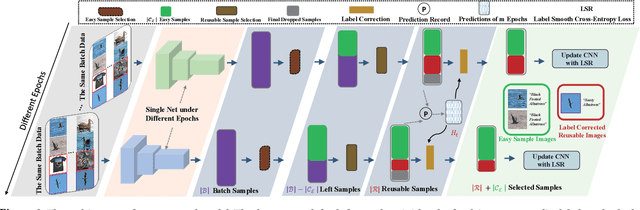
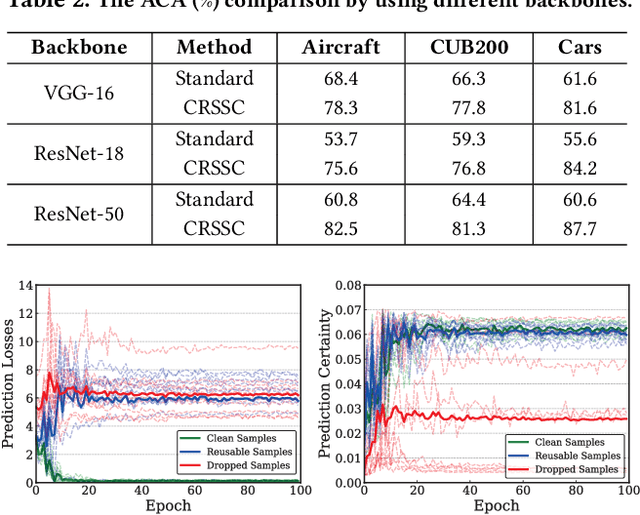
Due to the existence of label noise in web images and the high memorization capacity of deep neural networks, training deep fine-grained (FG) models directly through web images tends to have an inferior recognition ability. In the literature, to alleviate this issue, loss correction methods try to estimate the noise transition matrix, but the inevitable false correction would cause severe accumulated errors. Sample selection methods identify clean ("easy") samples based on the fact that small losses can alleviate the accumulated errors. However, "hard" and mislabeled examples that can both boost the robustness of FG models are also dropped. To this end, we propose a certainty-based reusable sample selection and correction approach, termed as CRSSC, for coping with label noise in training deep FG models with web images. Our key idea is to additionally identify and correct reusable samples, and then leverage them together with clean examples to update the networks. We demonstrate the superiority of the proposed approach from both theoretical and experimental perspectives.
ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
Aug 04, 2020
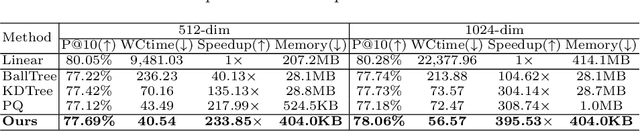
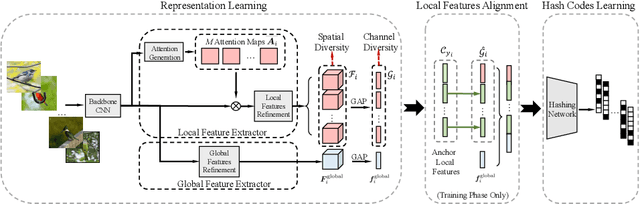
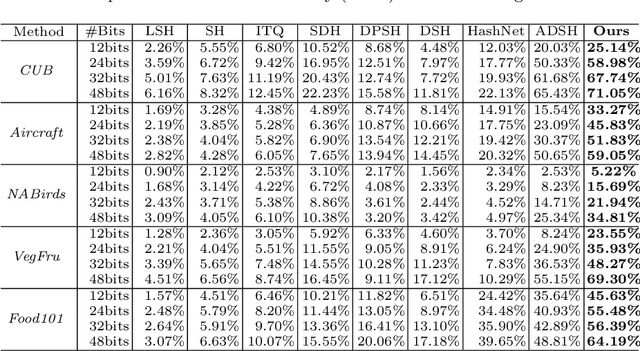
Retrieving content relevant images from a large-scale fine-grained dataset could suffer from intolerably slow query speed and highly redundant storage cost, due to high-dimensional real-valued embeddings which aim to distinguish subtle visual differences of fine-grained objects. In this paper, we study the novel fine-grained hashing topic to generate compact binary codes for fine-grained images, leveraging the search and storage efficiency of hash learning to alleviate the aforementioned problems. Specifically, we propose a unified end-to-end trainable network, termed as ExchNet. Based on attention mechanisms and proposed attention constraints, it can firstly obtain both local and global features to represent object parts and whole fine-grained objects, respectively. Furthermore, to ensure the discriminative ability and semantic meaning's consistency of these part-level features across images, we design a local feature alignment approach by performing a feature exchanging operation. Later, an alternative learning algorithm is employed to optimize the whole ExchNet and then generate the final binary hash codes. Validated by extensive experiments, our proposal consistently outperforms state-of-the-art generic hashing methods on five fine-grained datasets, which shows our effectiveness. Moreover, compared with other approximate nearest neighbor methods, ExchNet achieves the best speed-up and storage reduction, revealing its efficiency and practicality.
Hierarchical Context Embedding for Region-based Object Detection
Aug 04, 2020
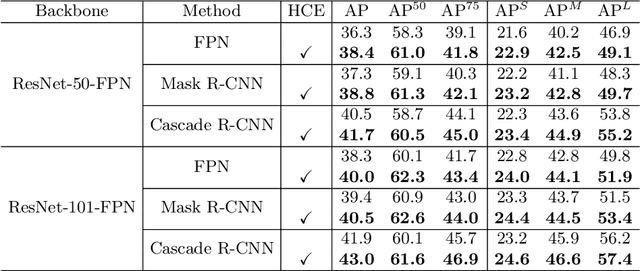
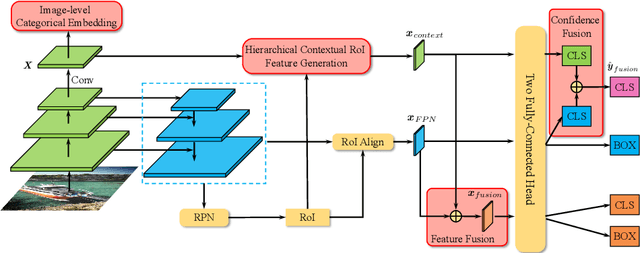
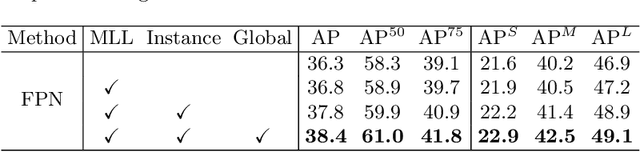
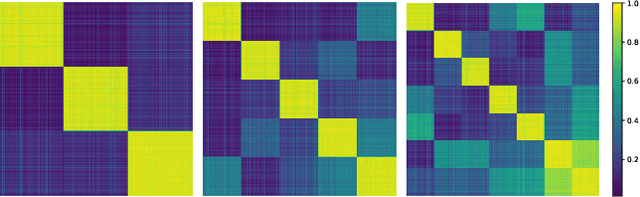
State-of-the-art two-stage object detectors apply a classifier to a sparse set of object proposals, relying on region-wise features extracted by RoIPool or RoIAlign as inputs. The region-wise features, in spite of aligning well with the proposal locations, may still lack the crucial context information which is necessary for filtering out noisy background detections, as well as recognizing objects possessing no distinctive appearances. To address this issue, we present a simple but effective Hierarchical Context Embedding (HCE) framework, which can be applied as a plug-and-play component, to facilitate the classification ability of a series of region-based detectors by mining contextual cues. Specifically, to advance the recognition of context-dependent object categories, we propose an image-level categorical embedding module which leverages the holistic image-level context to learn object-level concepts. Then, novel RoI features are generated by exploiting hierarchically embedded context information beneath both whole images and interested regions, which are also complementary to conventional RoI features. Moreover, to make full use of our hierarchical contextual RoI features, we propose the early-and-late fusion strategies (i.e., feature fusion and confidence fusion), which can be combined to boost the classification accuracy of region-based detectors. Comprehensive experiments demonstrate that our HCE framework is flexible and generalizable, leading to significant and consistent improvements upon various region-based detectors, including FPN, Cascade R-CNN and Mask R-CNN.
Learning Semantically Enhanced Feature for Fine-Grained Image Classification
Jul 05, 2020
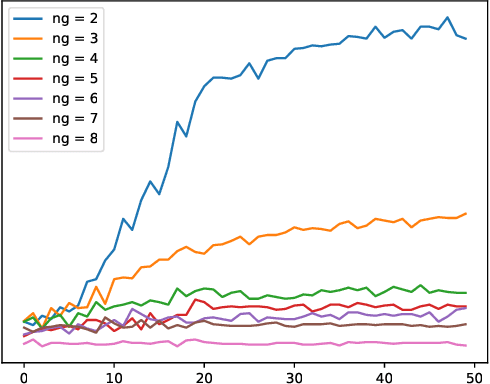

We aim to provide a computationally cheap yet effective approach for fine-grained image classification (FGIC) in this letter. Unlike previous methods that rely on complex part localization modules, our approach learns fine-grained features by improving the semantics of sub-features of a global feature. Specifically, we first achieve the sub-feature semantic by arranging feature channels of a CNN into different groups through channel permutation. Meanwhile, to enhance the discriminability of sub-features, the groups are guided to be activated on object parts with strong discriminability by a weighted combination regularization. This process brings only 1.7% additional parameters to its ResNet-50 backbone. Moreover, our approach can be easily integrated into the backbone model as a plug-and-play module for end-to-end training with only image-level supervision. Experiments verified the effectiveness of our approach and validated its comparable performance to the state-of-the-art methods. Code is available at https://github.com/cswluo/SEF
PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks
May 02, 2020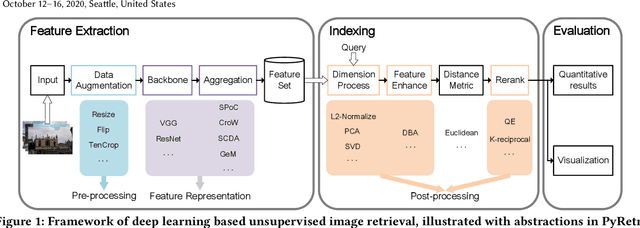
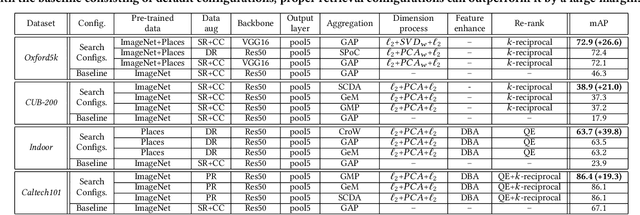

Despite significant progress of applying deep learning methods to the field of content-based image retrieval, there has not been a software library that covers these methods in a unified manner. In order to fill this gap, we introduce PyRetri, an open source library for deep learning based unsupervised image retrieval. The library encapsulates the retrieval process in several stages and provides functionality that covers various prominent methods for each stage. The idea underlying its design is to provide a unified platform for deep learning based image retrieval research, with high usability and extensibility. To the best of our knowledge, this is the first open-source library for unsupervised image retrieval by deep learning.
Exploring Categorical Regularization for Domain Adaptive Object Detection
Mar 20, 2020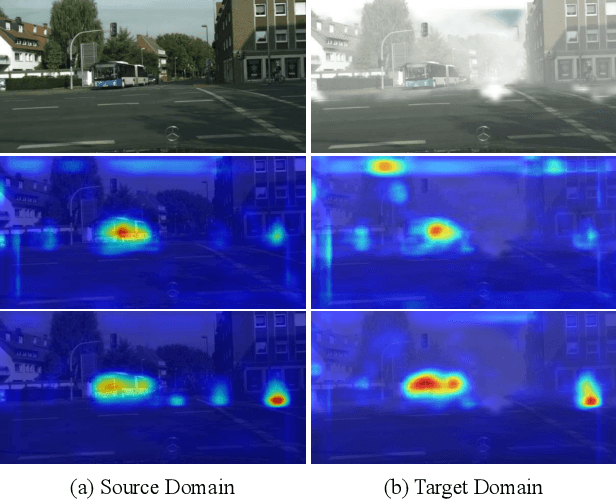
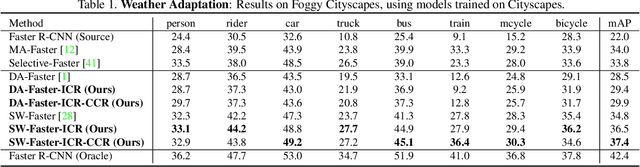
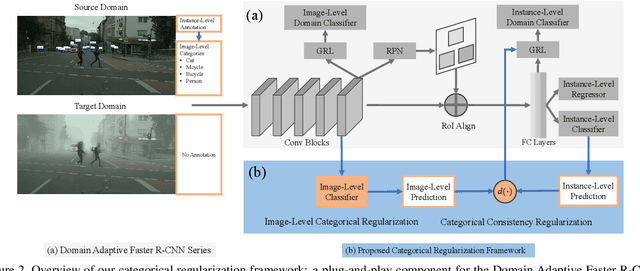
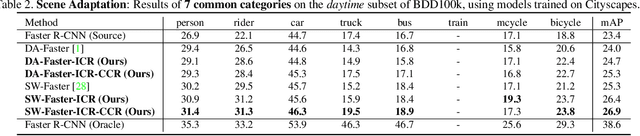
In this paper, we tackle the domain adaptive object detection problem, where the main challenge lies in significant domain gaps between source and target domains. Previous work seeks to plainly align image-level and instance-level shifts to eventually minimize the domain discrepancy. However, they still overlook to match crucial image regions and important instances across domains, which will strongly affect domain shift mitigation. In this work, we propose a simple but effective categorical regularization framework for alleviating this issue. It can be applied as a plug-and-play component on a series of Domain Adaptive Faster R-CNN methods which are prominent for dealing with domain adaptive detection. Specifically, by integrating an image-level multi-label classifier upon the detection backbone, we can obtain the sparse but crucial image regions corresponding to categorical information, thanks to the weakly localization ability of the classification manner. Meanwhile, at the instance level, we leverage the categorical consistency between image-level predictions (by the classifier) and instance-level predictions (by the detection head) as a regularization factor to automatically hunt for the hard aligned instances of target domains. Extensive experiments of various domain shift scenarios show that our method obtains a significant performance gain over original Domain Adaptive Faster R-CNN detectors. Furthermore, qualitative visualization and analyses can demonstrate the ability of our method for attending on the key regions/instances targeting on domain adaptation. Our code is open-source and available at \url{https://github.com/Megvii-Nanjing/CR-DA-DET}.