 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedVerse: Efficient and Reliable Medical Reasoning via DAG-Structured Parallel Execution
Feb 07, 2026Large language models (LLMs) have demonstrated strong performance and rapid progress in a wide range of medical reasoning tasks. However, their sequential autoregressive decoding forces inherently parallel clinical reasoning, such as differential diagnosis, into a single linear reasoning path, limiting both efficiency and reliability for complex medical problems. To address this, we propose MedVerse, a reasoning framework for complex medical inference that reformulates medical reasoning as a parallelizable directed acyclic graph (DAG) process based on Petri net theory. The framework adopts a full-stack design across data, model architecture, and system execution. For data creation, we introduce the MedVerse Curator, an automated pipeline that synthesizes knowledge-grounded medical reasoning paths and transforms them into Petri net-structured representations. At the architectural level, we propose a topology-aware attention mechanism with adaptive position indices that supports parallel reasoning while preserving logical consistency. Systematically, we develop a customized inference engine that supports parallel execution without additional overhead. Empirical evaluations show that MedVerse improves strong general-purpose LLMs by up to 8.9%. Compared to specialized medical LLMs, MedVerse achieves comparable performance while delivering a 1.3x reduction in inference latency and a 1.7x increase in generation throughput, enabled by its parallel decoding capability.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Rethinking Genomic Modeling Through Optical Character Recognition
Feb 02, 2026Recent genomic foundation models largely adopt large language model architectures that treat DNA as a one-dimensional token sequence. However, exhaustive sequential reading is structurally misaligned with sparse and discontinuous genomic semantics, leading to wasted computation on low-information background and preventing understanding-driven compression for long contexts. Here, we present OpticalDNA, a vision-based framework that reframes genomic modeling as Optical Character Recognition (OCR)-style document understanding. OpticalDNA renders DNA into structured visual layouts and trains an OCR-capable vision--language model with a \emph{visual DNA encoder} and a \emph{document decoder}, where the encoder produces compact, reconstructible visual tokens for high-fidelity compression. Building on this representation, OpticalDNA defines prompt-conditioned objectives over core genomic primitives-reading, region grounding, subsequence retrieval, and masked span completion-thereby learning layout-aware DNA representations that retain fine-grained genomic information under a reduced effective token budget. Across diverse genomic benchmarks, OpticalDNA consistently outperforms recent baselines; on sequences up to 450k bases, it achieves the best overall performance with nearly $20\times$ fewer effective tokens, and surpasses models with up to $985\times$ more activated parameters while tuning only 256k \emph{trainable} parameters.
MemWeaver: Weaving Hybrid Memories for Traceable Long-Horizon Agentic Reasoning
Jan 26, 2026Large language model-based agents operating in long-horizon interactions require memory systems that support temporal consistency, multi-hop reasoning, and evidence-grounded reuse across sessions. Existing approaches largely rely on unstructured retrieval or coarse abstractions, which often lead to temporal conflicts, brittle reasoning, and limited traceability. We propose MemWeaver, a unified memory framework that consolidates long-term agent experiences into three interconnected components: a temporally grounded graph memory for structured relational reasoning, an experience memory that abstracts recurring interaction patterns from repeated observations, and a passage memory that preserves original textual evidence. MemWeaver employs a dual-channel retrieval strategy that jointly retrieves structured knowledge and supporting evidence to construct compact yet information-dense contexts for reasoning. Experiments on the LoCoMo benchmark demonstrate that MemWeaver substantially improves multi-hop and temporal reasoning accuracy while reducing input context length by over 95\% compared to long-context baselines.
Scientific production in the era of Large Language Models
Jan 19, 2026Large Language Models (LLMs) are rapidly reshaping scientific research. We analyze these changes in multiple, large-scale datasets with 2.1M preprints, 28K peer review reports, and 246M online accesses to scientific documents. We find: 1) scientists adopting LLMs to draft manuscripts demonstrate a large increase in paper production, ranging from 23.7-89.3% depending on scientific field and author background, 2) LLM use has reversed the relationship between writing complexity and paper quality, leading to an influx of manuscripts that are linguistically complex but substantively underwhelming, and 3) LLM adopters access and cite more diverse prior work, including books and younger, less-cited documents. These findings highlight a stunning shift in scientific production that will likely require a change in how journals, funding agencies, and tenure committees evaluate scientific works.
* This is the author's version of the work. The definitive version was published in Science on 18 Dec 2025, DOI: 10.1126/science.adw3000. Link to the Final Published Version: https://www.science.org/doi/10.1126/science.adw3000
Song Aesthetics Evaluation with Multi-Stem Attention and Hierarchical Uncertainty Modeling
Jan 18, 2026Music generative artificial intelligence (AI) is rapidly expanding music content, necessitating automated song aesthetics evaluation. However, existing studies largely focus on speech, audio or singing quality, leaving song aesthetics underexplored. Moreover, conventional approaches often predict a precise Mean Opinion Score (MOS) value directly, which struggles to capture the nuances of human perception in song aesthetics evaluation. This paper proposes a song-oriented aesthetics evaluation framework, featuring two novel modules: 1) Multi-Stem Attention Fusion (MSAF) builds bidirectional cross-attention between mixture-vocal and mixture-accompaniment pairs, fusing them to capture complex musical features; 2) Hierarchical Granularity-Aware Interval Aggregation (HiGIA) learns multi-granularity score probability distributions, aggregates them into a score interval, and applies a regression within the interval to produce the final score. We evaluated on two datasets of full-length songs: SongEval dataset (AI-generated) and an internal aesthetics dataset (human-created), and compared with two state-of-the-art (SOTA) models. Results show that the proposed method achieves stronger performance for multi-dimensional song aesthetics evaluation.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Tracking and Understanding Object Transformations
Nov 06, 2025Real-world objects frequently undergo state transformations. From an apple being cut into pieces to a butterfly emerging from its cocoon, tracking through these changes is important for understanding real-world objects and dynamics. However, existing methods often lose track of the target object after transformation, due to significant changes in object appearance. To address this limitation, we introduce the task of Track Any State: tracking objects through transformations while detecting and describing state changes, accompanied by a new benchmark dataset, VOST-TAS. To tackle this problem, we present TubeletGraph, a zero-shot system that recovers missing objects after transformation and maps out how object states are evolving over time. TubeletGraph first identifies potentially overlooked tracks, and determines whether they should be integrated based on semantic and proximity priors. Then, it reasons about the added tracks and generates a state graph describing each observed transformation. TubeletGraph achieves state-of-the-art tracking performance under transformations, while demonstrating deeper understanding of object transformations and promising capabilities in temporal grounding and semantic reasoning for complex object transformations. Code, additional results, and the benchmark dataset are available at https://tubelet-graph.github.io.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025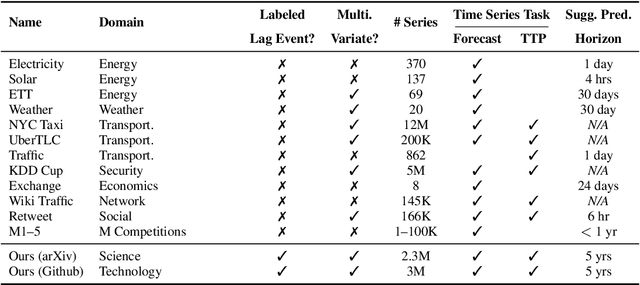


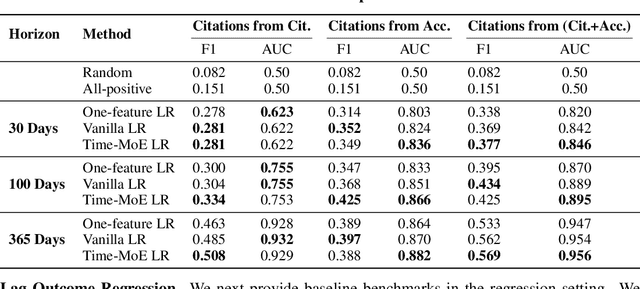
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion Language Models
Oct 16, 2025



Language models with recurrent depth, also referred to as universal or looped when considering transformers, are defined by the capacity to increase their computation through the repetition of layers. Recent efforts in pretraining have demonstrated that these architectures can scale to modern language modeling tasks while exhibiting advantages in reasoning tasks. In this work, we examine the relationship between recurrent-depth models and diffusion language models. Building on their similarities, we develop a new diffusion forcing sampler for these models to accelerate generation. The sampler advances by decoding new tokens at every forward pass of the model, while the latent states of these tokens can be further refined in parallel through recurrence. Theoretically, generation with our sampler is strictly more expressive than the baseline autoregressive generation using the same time budget on modern hardware. Moreover, this sampler, based on principles from diffusion literature, can be directly applied to existing 3.5B recurrent-depth transformers without any tuning, leading to up to a 5x speedup. Consequently, our findings not only provide an efficient mechanism for parallelizing the extra computation in recurrent-depth models at inference, but also suggest that such models can be naturally viewed as strong continuous, though causal, diffusion language models.