 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA system identification approach to clustering vector autoregressive time series
May 20, 2025Clustering of time series based on their underlying dynamics is keeping attracting researchers due to its impacts on assisting complex system modelling. Most current time series clustering methods handle only scalar time series, treat them as white noise, or rely on domain knowledge for high-quality feature construction, where the autocorrelation pattern/feature is mostly ignored. Instead of relying on heuristic feature/metric construction, the system identification approach allows treating vector time series clustering by explicitly considering their underlying autoregressive dynamics. We first derive a clustering algorithm based on a mixture autoregressive model. Unfortunately it turns out to have significant computational problems. We then derive a `small-noise' limiting version of the algorithm, which we call k-LMVAR (Limiting Mixture Vector AutoRegression), that is computationally manageable. We develop an associated BIC criterion for choosing the number of clusters and model order. The algorithm performs very well in comparative simulations and also scales well computationally.
Multi-Constraint Safe Reinforcement Learning via Closed-form Solution for Log-Sum-Exp Approximation of Control Barrier Functions
May 01, 2025



The safety of training task policies and their subsequent application using reinforcement learning (RL) methods has become a focal point in the field of safe RL. A central challenge in this area remains the establishment of theoretical guarantees for safety during both the learning and deployment processes. Given the successful implementation of Control Barrier Function (CBF)-based safety strategies in a range of control-affine robotic systems, CBF-based safe RL demonstrates significant promise for practical applications in real-world scenarios. However, integrating these two approaches presents several challenges. First, embedding safety optimization within the RL training pipeline requires that the optimization outputs be differentiable with respect to the input parameters, a condition commonly referred to as differentiable optimization, which is non-trivial to solve. Second, the differentiable optimization framework confronts significant efficiency issues, especially when dealing with multi-constraint problems. To address these challenges, this paper presents a CBF-based safe RL architecture that effectively mitigates the issues outlined above. The proposed approach constructs a continuous AND logic approximation for the multiple constraints using a single composite CBF. By leveraging this approximation, a close-form solution of the quadratic programming is derived for the policy network in RL, thereby circumventing the need for differentiable optimization within the end-to-end safe RL pipeline. This strategy significantly reduces computational complexity because of the closed-form solution while maintaining safety guarantees. Simulation results demonstrate that, in comparison to existing approaches relying on differentiable optimization, the proposed method significantly reduces training computational costs while ensuring provable safety throughout the training process.
Towards Intelligent Edge Sensing for ISCC Network: Joint Multi-Tier DNN Partitioning and Beamforming Design
Apr 30, 2025



The combination of Integrated Sensing and Communication (ISAC) and Mobile Edge Computing (MEC) enables devices to simultaneously sense the environment and offload data to the base stations (BS) for intelligent processing, thereby reducing local computational burdens. However, transmitting raw sensing data from ISAC devices to the BS often incurs substantial fronthaul overhead and latency. This paper investigates a three-tier collaborative inference framework enabled by Integrated Sensing, Communication, and Computing (ISCC), where cloud servers, MEC servers, and ISAC devices cooperatively execute different segments of a pre-trained deep neural network (DNN) for intelligent sensing. By offloading intermediate DNN features, the proposed framework can significantly reduce fronthaul transmission load. Furthermore, multiple-input multiple-output (MIMO) technology is employed to enhance both sensing quality and offloading efficiency. To minimize the overall sensing task inference latency across all ISAC devices, we jointly optimize the DNN partitioning strategy, ISAC beamforming, and computational resource allocation at the MEC servers and devices, subject to sensing beampattern constraints. We also propose an efficient two-layer optimization algorithm. In the inner layer, we derive closed-form solutions for computational resource allocation using the Karush-Kuhn-Tucker conditions. Moreover, we design the ISAC beamforming vectors via an iterative method based on the majorization-minimization and weighted minimum mean square error techniques. In the outer layer, we develop a cross-entropy based probabilistic learning algorithm to determine an optimal DNN partitioning strategy. Simulation results demonstrate that the proposed framework substantially outperforms existing two-tier schemes in inference latency.
Logits DeConfusion with CLIP for Few-Shot Learning
Apr 16, 2025



With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. Our MAF extracts features from different levels and fuses them uniformly to enhance feature representation. Our ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results show that our method can significantly improve the classification performance and alleviate the inter-class confusion problem. The code is available at https://github.com/LiShuo1001/LDC.
Safe Navigation in Uncertain Crowded Environments Using Risk Adaptive CVaR Barrier Functions
Apr 09, 2025Robot navigation in dynamic, crowded environments poses a significant challenge due to the inherent uncertainties in the obstacle model. In this work, we propose a risk-adaptive approach based on the Conditional Value-at-Risk Barrier Function (CVaR-BF), where the risk level is automatically adjusted to accept the minimum necessary risk, achieving a good performance in terms of safety and optimization feasibility under uncertainty. Additionally, we introduce a dynamic zone-based barrier function which characterizes the collision likelihood by evaluating the relative state between the robot and the obstacle. By integrating risk adaptation with this new function, our approach adaptively expands the safety margin, enabling the robot to proactively avoid obstacles in highly dynamic environments. Comparisons and ablation studies demonstrate that our method outperforms existing social navigation approaches, and validate the effectiveness of our proposed framework.
Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning
Apr 04, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks requiring complex reasoning. However, the effects of scaling on their reasoning abilities remain insufficiently understood. In this paper, we introduce a synthetic multihop reasoning environment designed to closely replicate the structure and distribution of real-world large-scale knowledge graphs. Our reasoning task involves completing missing edges in the graph, which requires advanced multi-hop reasoning and mimics real-world reasoning scenarios. To evaluate this, we pretrain language models (LMs) from scratch solely on triples from the incomplete graph and assess their ability to infer the missing edges. Interestingly, we observe that overparameterization can impair reasoning performance due to excessive memorization. We investigate different factors that affect this U-shaped loss curve, including graph structure, model size, and training steps. To predict the optimal model size for a specific knowledge graph, we find an empirical scaling that linearly maps the knowledge graph search entropy to the optimal model size. This work provides new insights into the relationship between scaling and reasoning in LLMs, shedding light on possible ways to optimize their performance for reasoning tasks.
ASMA-Tune: Unlocking LLMs' Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Mar 14, 2025Analysis and comprehension of assembly code are crucial in various applications, such as reverse engineering. However, the low information density and lack of explicit syntactic structures in assembly code pose significant challenges. Pioneering approaches with masked language modeling (MLM)-based methods have been limited by facilitating natural language interaction. While recent methods based on decoder-focused large language models (LLMs) have significantly enhanced semantic representation, they still struggle to capture the nuanced and sparse semantics in assembly code. In this paper, we propose Assembly Augmented Tuning (ASMA-Tune), an end-to-end structural-semantic instruction-tuning framework. Our approach synergizes encoder architectures with decoder-based LLMs through projector modules to enable comprehensive code understanding. Experiments show that ASMA-Tune outperforms existing benchmarks, significantly enhancing assembly code comprehension and instruction-following abilities. Our model and dataset are public at https://github.com/wxy3596/ASMA-Tune.
CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
Mar 12, 2025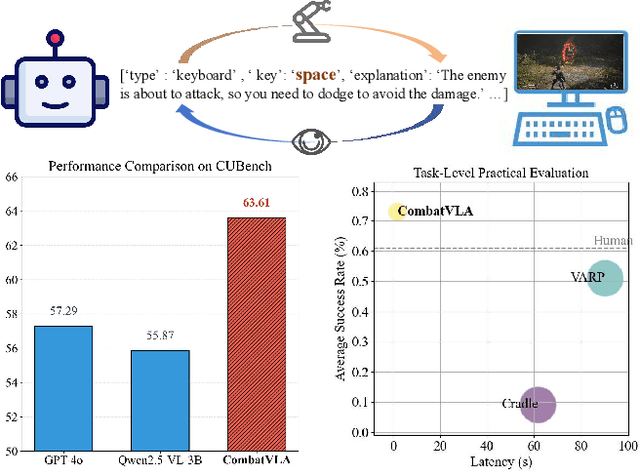
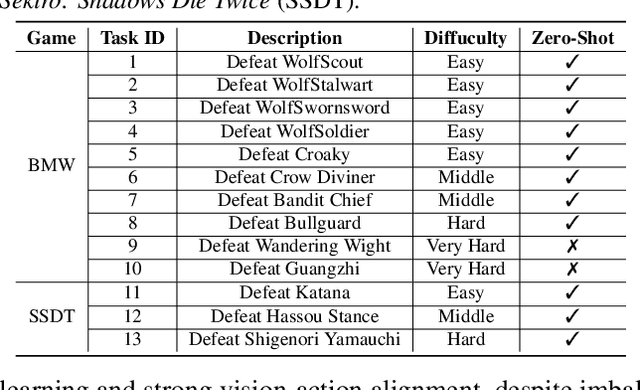
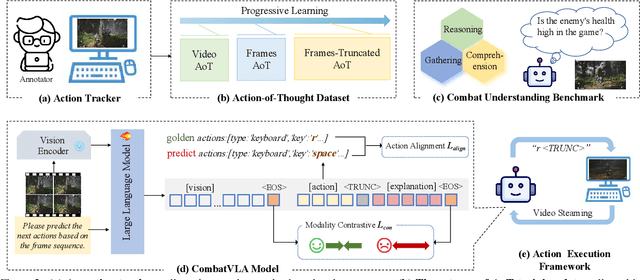
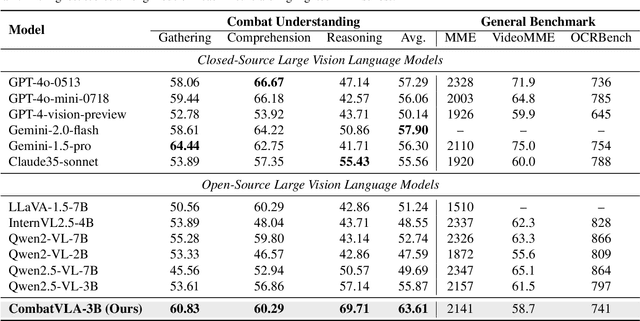
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.
GM-MoE: Low-Light Enhancement with Gated-Mechanism Mixture-of-Experts
Mar 10, 2025Low-light enhancement has wide applications in autonomous driving, 3D reconstruction, remote sensing, surveillance, and so on, which can significantly improve information utilization. However, most existing methods lack generalization and are limited to specific tasks such as image recovery. To address these issues, we propose \textbf{Gated-Mechanism Mixture-of-Experts (GM-MoE)}, the first framework to introduce a mixture-of-experts network for low-light image enhancement. GM-MoE comprises a dynamic gated weight conditioning network and three sub-expert networks, each specializing in a distinct enhancement task. Combining a self-designed gated mechanism that dynamically adjusts the weights of the sub-expert networks for different data domains. Additionally, we integrate local and global feature fusion within sub-expert networks to enhance image quality by capturing multi-scale features. Experimental results demonstrate that the GM-MoE achieves superior generalization with respect to 25 compared approaches, reaching state-of-the-art performance on PSNR on 5 benchmarks and SSIM on 4 benchmarks, respectively.
AugRefer: Advancing 3D Visual Grounding via Cross-Modal Augmentation and Spatial Relation-based Referring
Jan 16, 2025



3D visual grounding (3DVG), which aims to correlate a natural language description with the target object within a 3D scene, is a significant yet challenging task. Despite recent advancements in this domain, existing approaches commonly encounter a shortage: a limited amount and diversity of text3D pairs available for training. Moreover, they fall short in effectively leveraging different contextual clues (e.g., rich spatial relations within the 3D visual space) for grounding. To address these limitations, we propose AugRefer, a novel approach for advancing 3D visual grounding. AugRefer introduces cross-modal augmentation designed to extensively generate diverse text-3D pairs by placing objects into 3D scenes and creating accurate and semantically rich descriptions using foundation models. Notably, the resulting pairs can be utilized by any existing 3DVG methods for enriching their training data. Additionally, AugRefer presents a language-spatial adaptive decoder that effectively adapts the potential referring objects based on the language description and various 3D spatial relations. Extensive experiments on three benchmark datasets clearly validate the effectiveness of AugRefer.