 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeaXDrive: Feasibility-aware Trajectory-Centric Diffusion Planning for End-to-End Autonomous Driving
Apr 14, 2026End-to-end diffusion planning has shown strong potential for autonomous driving, but the physical feasibility of generated trajectories remains insufficiently addressed. In particular, generated trajectories may exhibit local geometric irregularities, violate trajectory-level kinematic constraints, or deviate from the drivable area, indicating that the commonly used noise-centric formulation in diffusion planning is not yet well aligned with the trajectory space where feasibility is more naturally characterized. To address this issue, we propose FeaXDrive, a feasibility-aware trajectory-centric diffusion planning method for end-to-end autonomous driving. The core idea is to treat the clean trajectory as the unified object for feasibility-aware modeling throughout the diffusion process. Built on this trajectory-centric formulation, FeaXDrive integrates adaptive curvature-constrained training to improve intrinsic geometric and kinematic feasibility, drivable-area guidance within reverse diffusion sampling to enhance consistency with the drivable area, and feasibility-aware GRPO post-training to further improve planning performance while balancing trajectory-space feasibility. Experiments on the NAVSIM benchmark show that FeaXDrive achieves strong closed-loop planning performance while substantially improving trajectory-space feasibility. These findings highlight the importance of explicitly modeling trajectory-space feasibility in end-to-end diffusion planning and provide a step toward more reliable and physically grounded autonomous driving planners.
An interactive enhanced driving dataset for autonomous driving
Feb 24, 2026The evolution of autonomous driving towards full automation demands robust interactive capabilities; however, the development of Vision-Language-Action (VLA) models is constrained by the sparsity of interactive scenarios and inadequate multimodal alignment in existing data. To this end, this paper proposes the Interactive Enhanced Driving Dataset (IEDD). We develop a scalable pipeline to mine million-level interactive segments from naturalistic driving data based on interactive trajectories, and design metrics to quantify the interaction processes. Furthermore, the IEDD-VQA dataset is constructed by generating synthetic Bird's Eye View (BEV) videos where semantic actions are strictly aligned with structured language. Benchmark results evaluating ten mainstream Vision Language Models (VLMs) are provided to demonstrate the dataset's reuse value in assessing and fine-tuning the reasoning capabilities of autonomous driving models.
FSP-Diff: Full-Spectrum Prior-Enhanced DualDomain Latent Diffusion for Ultra-Low-Dose Spectral CT Reconstruction
Feb 08, 2026Spectral computed tomography (CT) with photon-counting detectors holds immense potential for material discrimination and tissue characterization. However, under ultra-low-dose conditions, the sharply degraded signal-to-noise ratio (SNR) in energy-specific projections poses a significant challenge, leading to severe artifacts and loss of structural details in reconstructed images. To address this, we propose FSP-Diff, a full-spectrum prior-enhanced dual-domain latent diffusion framework for ultra-low-dose spectral CT reconstruction. Our framework integrates three core strategies: 1) Complementary Feature Construction: We integrate direct image reconstructions with projection-domain denoised results. While the former preserves latent textural nuances amidst heavy noise, the latter provides a stable structural scaffold to balance detail fidelity and noise suppression. 2) Full-Spectrum Prior Integration: By fusing multi-energy projections into a high-SNR full-spectrum image, we establish a unified structural reference that guides the reconstruction across all energy bins. 3) Efficient Latent Diffusion Synthesis: To alleviate the high computational burden of high-dimensional spectral data, multi-path features are embedded into a compact latent space. This allows the diffusion process to facilitate interactive feature fusion in a lower-dimensional manifold, achieving accelerated reconstruction while maintaining fine-grained detail restoration. Extensive experiments on simulated and real-world datasets demonstrate that FSP-Diff significantly outperforms state-of-the-art methods in both image quality and computational efficiency, underscoring its potential for clinically viable ultra-low-dose spectral CT imaging.
WaterClear-GS: Optical-Aware Gaussian Splatting for Underwater Reconstruction and Restoration
Jan 27, 2026Underwater 3D reconstruction and appearance restoration are hindered by the complex optical properties of water, such as wavelength-dependent attenuation and scattering. Existing Neural Radiance Fields (NeRF)-based methods struggle with slow rendering speeds and suboptimal color restoration, while 3D Gaussian Splatting (3DGS) inherently lacks the capability to model complex volumetric scattering effects. To address these issues, we introduce WaterClear-GS, the first pure 3DGS-based framework that explicitly integrates underwater optical properties of local attenuation and scattering into Gaussian primitives, eliminating the need for an auxiliary medium network. Our method employs a dual-branch optimization strategy to ensure underwater photometric consistency while naturally recovering water-free appearances. This strategy is enhanced by depth-guided geometry regularization and perception-driven image loss, together with exposure constraints, spatially-adaptive regularization, and physically guided spectral regularization, which collectively enforce local 3D coherence and maintain natural visual perception. Experiments on standard benchmarks and our newly collected dataset demonstrate that WaterClear-GS achieves outstanding performance on both novel view synthesis (NVS) and underwater image restoration (UIR) tasks, while maintaining real-time rendering. The code will be available at https://buaaxrzhang.github.io/WaterClear-GS/.
A Communication-Latency-Aware Co-Simulation Platform for Safety and Comfort Evaluation of Cloud-Controlled ICVs
Jun 09, 2025Testing cloud-controlled intelligent connected vehicles (ICVs) requires simulation environments that faithfully emulate both vehicle behavior and realistic communication latencies. This paper proposes a latency-aware co-simulation platform integrating CarMaker and Vissim to evaluate safety and comfort under real-world vehicle-to-cloud (V2C) latency conditions. Two communication latency models, derived from empirical 5G measurements in China and Hungary, are incorporated and statistically modeled using Gamma distributions. A proactive conflict module (PCM) is proposed to dynamically control background vehicles and generate safety-critical scenarios. The platform is validated through experiments involving an exemplary system under test (SUT) across six testing conditions combining two PCM modes (enabled/disabled) and three latency conditions (none, China, Hungary). Safety and comfort are assessed using metrics including collision rate, distance headway, post-encroachment time, and the spectral characteristics of longitudinal acceleration. Results show that the PCM effectively increases driving environment criticality, while V2C latency primarily affects ride comfort. These findings confirm the platform's effectiveness in systematically evaluating cloud-controlled ICVs under diverse testing conditions.
Biological Sequence with Language Model Prompting: A Survey
Mar 06, 2025Large Language models (LLMs) have emerged as powerful tools for addressing challenges across diverse domains. Notably, recent studies have demonstrated that large language models significantly enhance the efficiency of biomolecular analysis and synthesis, attracting widespread attention from academics and medicine. In this paper, we systematically investigate the application of prompt-based methods with LLMs to biological sequences, including DNA, RNA, proteins, and drug discovery tasks. Specifically, we focus on how prompt engineering enables LLMs to tackle domain-specific problems, such as promoter sequence prediction, protein structure modeling, and drug-target binding affinity prediction, often with limited labeled data. Furthermore, our discussion highlights the transformative potential of prompting in bioinformatics while addressing key challenges such as data scarcity, multimodal fusion, and computational resource limitations. Our aim is for this paper to function both as a foundational primer for newcomers and a catalyst for continued innovation within this dynamic field of study.
Real-world Troublemaker: A 5G Cloud-controlled Track Testing Framework for Automated Driving Systems in Safety-critical Interaction Scenarios
Feb 23, 2025Track testing plays a critical role in the safety evaluation of autonomous driving systems (ADS), as it provides a real-world interaction environment. However, the inflexibility in motion control of object targets and the absence of intelligent interactive testing methods often result in pre-fixed and limited testing scenarios. To address these limitations, we propose a novel 5G cloud-controlled track testing framework, Real-world Troublemaker. This framework overcomes the rigidity of traditional pre-programmed control by leveraging 5G cloud-controlled object targets integrated with the Internet of Things (IoT) and vehicle teleoperation technologies. Unlike conventional testing methods that rely on pre-set conditions, we propose a dynamic game strategy based on a quadratic risk interaction utility function, facilitating intelligent interactions with the vehicle under test (VUT) and creating a more realistic and dynamic interaction environment. The proposed framework has been successfully implemented at the Tongji University Intelligent Connected Vehicle Evaluation Base. Field test results demonstrate that Troublemaker can perform dynamic interactive testing of ADS accurately and effectively. Compared to traditional methods, Troublemaker improves scenario reproduction accuracy by 65.2\%, increases the diversity of interaction strategies by approximately 9.2 times, and enhances exposure frequency of safety-critical scenarios by 3.5 times in unprotected left-turn scenarios.
SI-FID: Only One Objective Indicator for Evaluating Stitched Images
Apr 22, 2024



Image quality evaluation accurately is vital in developing image stitching algorithms as it directly reflects the algorithms progress. However, commonly used objective indicators always produce inconsistent and even conflicting results with subjective indicators. To enhance the consistency between objective and subjective evaluations, this paper introduces a novel indicator the Frechet Distance for Stitched Images (SI-FID). To be specific, our training network employs the contrastive learning architecture overall. We employ data augmentation approaches that serve as noise to distort images in the training set. Both the initial and distorted training sets are then input into the pre-training model for fine-tuning. We then evaluate the altered FID after introducing interference to the test set and examine if the noise can improve the consistency between objective and subjective evaluation results. The rank correlation coefficient is utilized to measure the consistency. SI-FID is an altered FID that generates the highest rank correlation coefficient under the effect of a certain noise. The experimental results demonstrate that the rank correlation coefficient obtained by SI-FID is at least 25% higher than other objective indicators, which means achieving evaluation results closer to human subjective evaluation.
SGA: A Graph Augmentation Method for Signed Graph Neural Networks
Oct 15, 2023



Signed Graph Neural Networks (SGNNs) are vital for analyzing complex patterns in real-world signed graphs containing positive and negative links. However, three key challenges hinder current SGNN-based signed graph representation learning: sparsity in signed graphs leaves latent structures undiscovered, unbalanced triangles pose representation difficulties for SGNN models, and real-world signed graph datasets often lack supplementary information like node labels and features. These constraints limit the potential of SGNN-based representation learning. We address these issues with data augmentation techniques. Despite many graph data augmentation methods existing for unsigned graphs, none are tailored for signed graphs. Our paper introduces the novel Signed Graph Augmentation framework (SGA), comprising three main components. First, we employ the SGNN model to encode the signed graph, extracting latent structural information for candidate augmentation structures. Second, we evaluate these candidate samples (edges) and select the most beneficial ones for modifying the original training set. Third, we propose a novel augmentation perspective that assigns varying training difficulty to training samples, enabling the design of a new training strategy. Extensive experiments on six real-world datasets (Bitcoin-alpha, Bitcoin-otc, Epinions, Slashdot, Wiki-elec, and Wiki-RfA) demonstrate that SGA significantly improves performance across multiple benchmarks. Our method outperforms baselines by up to 22.2% in AUC for SGCN on Wiki-RfA, 33.3% in F1-binary, 48.8% in F1-micro, and 36.3% in F1-macro for GAT on Bitcoin-alpha in link sign prediction.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020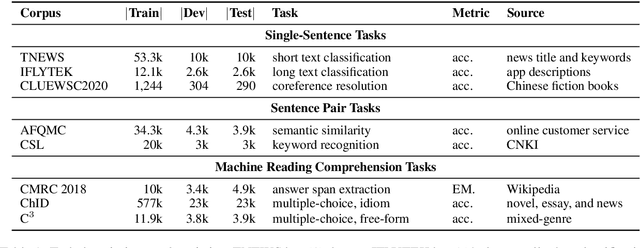
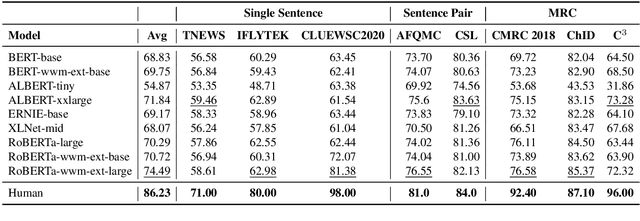
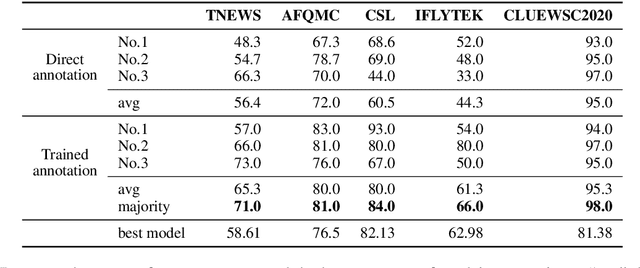
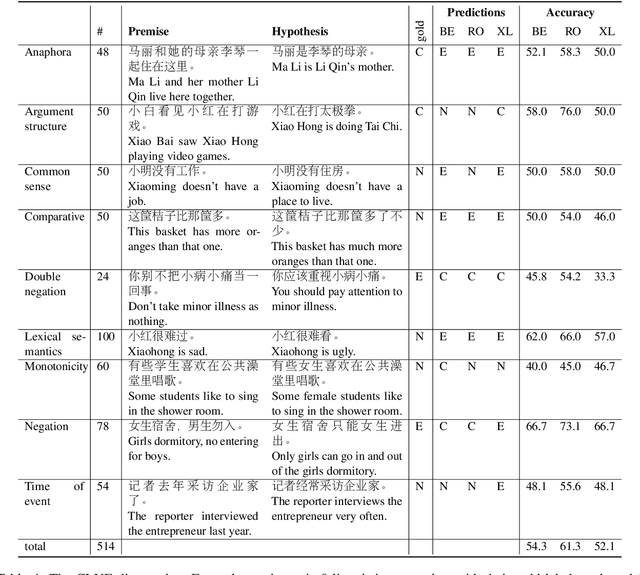
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.