 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modality Data Augmentation for End-to-End Sign Language Translation
May 22, 2023



End-to-end sign language translation (SLT) aims to convert sign language videos into spoken language texts directly without intermediate representations. It has been a challenging task due to the modality gap between sign videos and texts and the data scarcity of labeled data. To tackle these challenges, we propose a novel Cross-modality Data Augmentation (XmDA) framework to transfer the powerful gloss-to-text translation capabilities to end-to-end sign language translation (i.e. video-to-text) by exploiting pseudo gloss-text pairs from the sign gloss translation model. Specifically, XmDA consists of two key components, namely, cross-modality mix-up and cross-modality knowledge distillation. The former explicitly encourages the alignment between sign video features and gloss embeddings to bridge the modality gap. The latter utilizes the generation knowledge from gloss-to-text teacher models to guide the spoken language text generation. Experimental results on two widely used SLT datasets, i.e., PHOENIX-2014T and CSL-Daily, demonstrate that the proposed XmDA framework significantly and consistently outperforms the baseline models. Extensive analyses confirm our claim that XmDA enhances spoken language text generation by reducing the representation distance between videos and texts, as well as improving the processing of low-frequency words and long sentences.
Exploring Human-Like Translation Strategy with Large Language Models
May 06, 2023Large language models (LLMs) have demonstrated impressive capabilities in general scenarios, exhibiting a level of aptitude that approaches, in some aspects even surpasses, human-level intelligence. Among their numerous skills, the translation abilities of LLMs have received considerable attention. In contrast to traditional machine translation that focuses solely on source-target mapping, LLM-based translation can potentially mimic the human translation process that takes many preparatory steps to ensure high-quality translation. This work aims to explore this possibility by proposing the MAPS framework, which stands for Multi-Aspect Prompting and Selection. Specifically, we enable LLMs to first analyze the given source text and extract three aspects of translation-related knowledge: keywords, topics and relevant demonstrations to guide the translation process. To filter out the noisy and unhelpful knowledge, we employ a selection mechanism based on quality estimation. Experiments suggest that MAPS brings significant and consistent improvements over text-davinci-003 and Alpaca on eight translation directions from the latest WMT22 test sets. Our further analysis shows that the extracted knowledge is critical in resolving up to 59% of hallucination mistakes in translation. Code is available at https://github.com/zwhe99/MAPS-mt.
ParroT: Translating During Chat Using Large Language Models
Apr 20, 2023



Large language models (LLMs) like ChatGPT and GPT-4 have exhibited remarkable abilities on a wide range of natural language processing (NLP) tasks, including various machine translation abilities accomplished during chat. However, these models are only accessible through restricted APIs, which creates barriers to new research and advancements in the field. Therefore, we propose the $\mathbf{ParroT}$ framework to enhance and regulate the translation abilities during chat based on open-sourced LLMs (i.e., LLaMA-7b, BLOOMZ-7b-mt) and human written translation and evaluation data. Specifically, ParroT reformulates translation data into the instruction-following style, and introduces a "$\mathbf{Hint}$" field for incorporating extra requirements to regulate the translation process. Accordingly, we propose three instruction types for finetuning ParroT models, including translation instruction, contrastive instruction, and error-guided instruction. We can finetune either the full models or partial parameters via low rank adaptation (LoRA). Experiments on Flores subsets and WMT22 test sets suggest that translation instruction improves the translation performance of vanilla LLMs significantly while error-guided instruction can lead to a further improvement, which demonstrates the importance of learning from low-quality translations annotated by human. Meanwhile, the ParroT models can also preserve the ability on general tasks with the Alpaca multi-task dataset involved in finetuning. Please refer to our Github project for more implementation details: https://github.com/wxjiao/ParroT
Adaptive Hybrid Spatial-Temporal Graph Neural Network for Cellular Traffic Prediction
Feb 28, 2023



Cellular traffic prediction is an indispensable part for intelligent telecommunication networks. Nevertheless, due to the frequent user mobility and complex network scheduling mechanisms, cellular traffic often inherits complicated spatial-temporal patterns, making the prediction incredibly challenging. Although recent advanced algorithms such as graph-based prediction approaches have been proposed, they frequently model spatial dependencies based on static or dynamic graphs and neglect the coexisting multiple spatial correlations induced by traffic generation. Meanwhile, some works lack the consideration of the diverse cellular traffic patterns, result in suboptimal prediction results. In this paper, we propose a novel deep learning network architecture, Adaptive Hybrid Spatial-Temporal Graph Neural Network (AHSTGNN), to tackle the cellular traffic prediction problem. First, we apply adaptive hybrid graph learning to learn the compound spatial correlations among cell towers. Second, we implement a Temporal Convolution Module with multi-periodic temporal data input to capture the nonlinear temporal dependencies. In addition, we introduce an extra Spatial-Temporal Adaptive Module to conquer the heterogeneity lying in cell towers. Our experiments on two real-world cellular traffic datasets show AHSTGNN outperforms the state-of-the-art by a significant margin, illustrating the superior scalability of our method for spatial-temporal cellular traffic prediction.
Is ChatGPT A Good Translator? A Preliminary Study
Jan 20, 2023This report provides a preliminary evaluation of ChatGPT for machine translation, including translation prompt, multilingual translation, and translation robustness. We adopt the prompts advised by ChatGPT to trigger its translation ability and find that the candidate prompts generally work well and show minor performance differences. By evaluating on a number of benchmark test sets, we find that ChatGPT performs competitively with commercial translation products (e.g., Google Translate) on high-resource European languages but lags behind significantly on lowresource or distant languages. As for the translation robustness, ChatGPT does not perform as well as the commercial systems on biomedical abstracts or Reddit comments but is potentially a good translator for spoken language. Scripts and data: https://github.com/wxjiao/Is-ChatGPT-A-Good-Translator
Hyperbolic Cosine Transformer for LiDAR 3D Object Detection
Nov 10, 2022Recently, Transformer has achieved great success in computer vision. However, it is constrained because the spatial and temporal complexity grows quadratically with the number of large points in 3D object detection applications. Previous point-wise methods are suffering from time consumption and limited receptive fields to capture information among points. In this paper, we propose a two-stage hyperbolic cosine transformer (ChTR3D) for 3D object detection from LiDAR point clouds. The proposed ChTR3D refines proposals by applying cosh-attention in linear computation complexity to encode rich contextual relationships among points. The cosh-attention module reduces the space and time complexity of the attention operation. The traditional softmax operation is replaced by non-negative ReLU activation and hyperbolic-cosine-based operator with re-weighting mechanism. Extensive experiments on the widely used KITTI dataset demonstrate that, compared with vanilla attention, the cosh-attention significantly improves the inference speed with competitive performance. Experiment results show that, among two-stage state-of-the-art methods using point-level features, the proposed ChTR3D is the fastest one.
Tencent AI Lab - Shanghai Jiao Tong University Low-Resource Translation System for the WMT22 Translation Task
Oct 17, 2022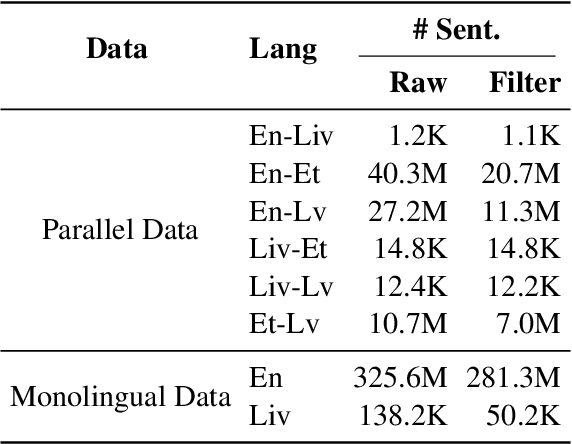
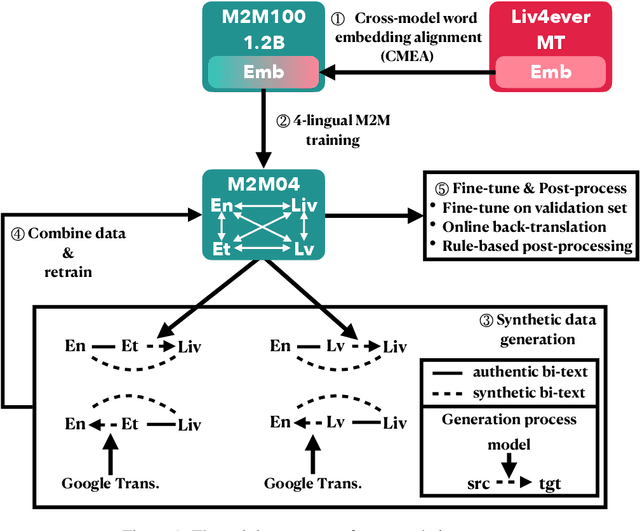
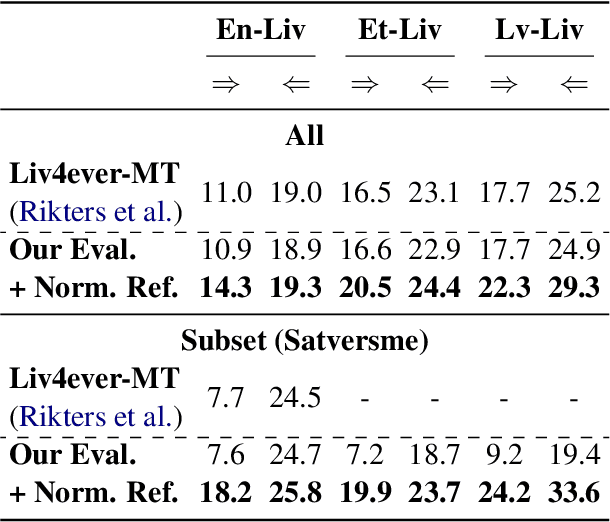
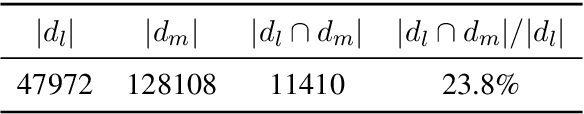
This paper describes Tencent AI Lab - Shanghai Jiao Tong University (TAL-SJTU) Low-Resource Translation systems for the WMT22 shared task. We participate in the general translation task on English$\Leftrightarrow$Livonian. Our system is based on M2M100 with novel techniques that adapt it to the target language pair. (1) Cross-model word embedding alignment: inspired by cross-lingual word embedding alignment, we successfully transfer a pre-trained word embedding to M2M100, enabling it to support Livonian. (2) Gradual adaptation strategy: we exploit Estonian and Latvian as auxiliary languages for many-to-many translation training and then adapt to English-Livonian. (3) Data augmentation: to enlarge the parallel data for English-Livonian, we construct pseudo-parallel data with Estonian and Latvian as pivot languages. (4) Fine-tuning: to make the most of all available data, we fine-tune the model with the validation set and online back-translation, further boosting the performance. In model evaluation: (1) We find that previous work underestimated the translation performance of Livonian due to inconsistent Unicode normalization, which may cause a discrepancy of up to 14.9 BLEU score. (2) In addition to the standard validation set, we also employ round-trip BLEU to evaluate the models, which we find more appropriate for this task. Finally, our unconstrained system achieves BLEU scores of 17.0 and 30.4 for English to/from Livonian.
Scaling Back-Translation with Domain Text Generation for Sign Language Gloss Translation
Oct 13, 2022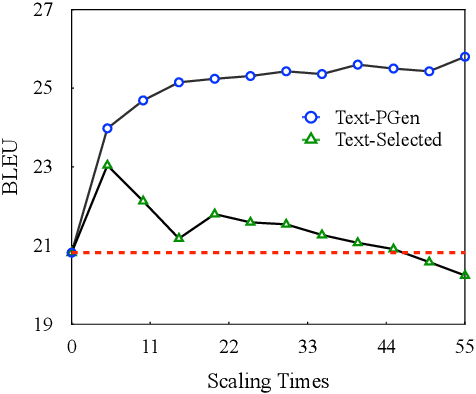
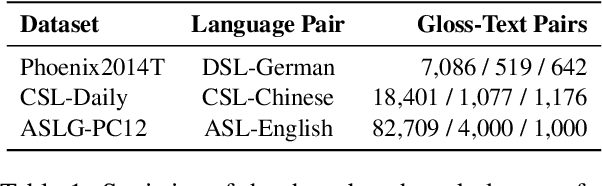
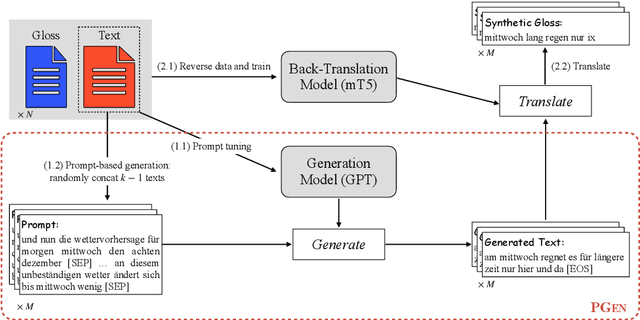
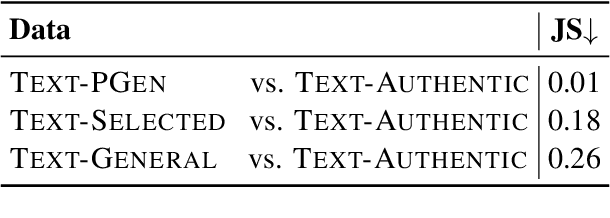
Sign language gloss translation aims to translate the sign glosses into spoken language texts, which is challenging due to the scarcity of labeled gloss-text parallel data. Back translation (BT), which generates pseudo-parallel data by translating in-domain spoken language texts into sign glosses, has been applied to alleviate the data scarcity problem. However, the lack of large-scale high-quality domain spoken language text data limits the effect of BT. In this paper, to overcome the limitation, we propose a Prompt based domain text Generation (PGEN) approach to produce the large-scale in-domain spoken language text data. Specifically, PGEN randomly concatenates sentences from the original in-domain spoken language text data as prompts to induce a pre-trained language model (i.e., GPT-2) to generate spoken language texts in a similar style. Experimental results on three benchmarks of sign language gloss translation in varied languages demonstrate that BT with spoken language texts generated by PGEN significantly outperforms the compared methods. In addition, as the scale of spoken language texts generated by PGEN increases, the BT technique can achieve further improvements, demonstrating the effectiveness of our approach. We release the code and data for facilitating future research in this field.
STAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Sep 07, 2022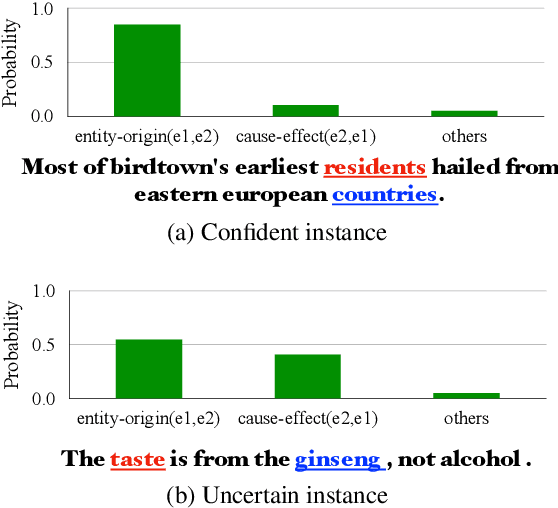
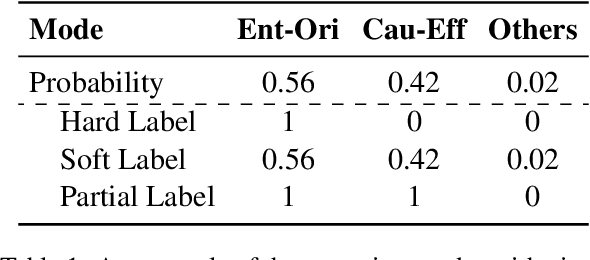
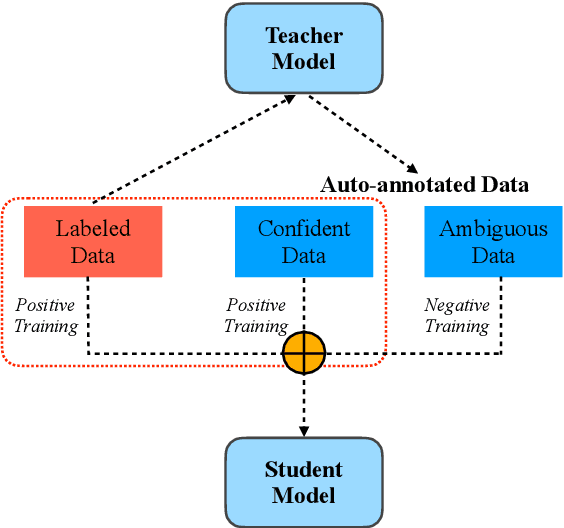
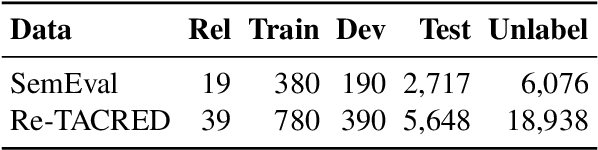
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD
Semantic Segmentation of Fruits on Multi-sensor Fused Data in Natural Orchards
Aug 04, 2022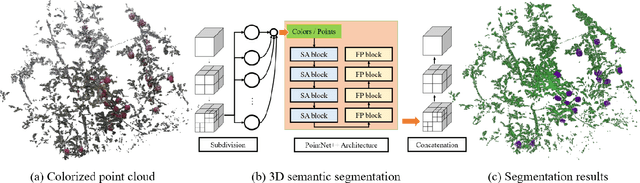
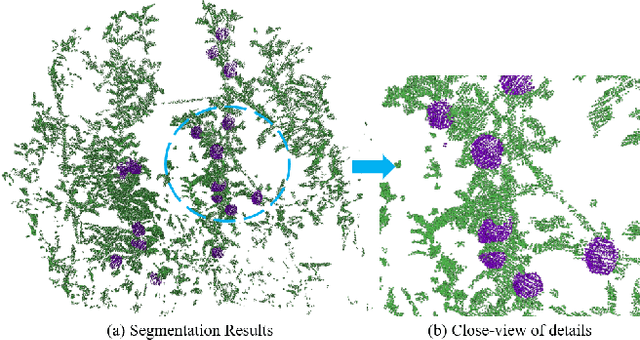


Semantic segmentation is a fundamental task for agricultural robots to understand the surrounding environments in natural orchards. The recent development of the LiDAR techniques enables the robot to acquire accurate range measurements of the view in the unstructured orchards. Compared to RGB images, 3D point clouds have geometrical properties. By combining the LiDAR and camera, rich information on geometries and textures can be obtained. In this work, we propose a deep-learning-based segmentation method to perform accurate semantic segmentation on fused data from a LiDAR-Camera visual sensor. Two critical problems are explored and solved in this work. The first one is how to efficiently fused the texture and geometrical features from multi-sensor data. The second one is how to efficiently train the 3D segmentation network under severely imbalance class conditions. Moreover, an implementation of 3D segmentation in orchards including LiDAR-Camera data fusion, data collection and labelling, network training, and model inference is introduced in detail. In the experiment, we comprehensively analyze the network setup when dealing with highly unstructured and noisy point clouds acquired from an apple orchard. Overall, our proposed method achieves 86.2% mIoU on the segmentation of fruits on the high-resolution point cloud (100k-200k points). The experiment results show that the proposed method can perform accurate segmentation in real orchard environments.