 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Autoformalization Using Direct Dependency Retrieval
Nov 15, 2025The convergence of deep learning and formal mathematics has spurred research in formal verification. Statement autoformalization, a crucial first step in this process, aims to translate informal descriptions into machine-verifiable representations but remains a significant challenge. The core difficulty lies in the fact that existing methods often suffer from a lack of contextual awareness, leading to hallucination of formal definitions and theorems. Furthermore, current retrieval-augmented approaches exhibit poor precision and recall for formal library dependency retrieval, and lack the scalability to effectively leverage ever-growing public datasets. To bridge this gap, we propose a novel retrieval-augmented framework based on DDR (\textit{Direct Dependency Retrieval}) for statement autoformalization. Our DDR method directly generates candidate library dependencies from natural language mathematical descriptions and subsequently verifies their existence within the formal library via an efficient suffix array check. Leveraging this efficient search mechanism, we constructed a dependency retrieval dataset of over 500,000 samples and fine-tuned a high-precision DDR model. Experimental results demonstrate that our DDR model significantly outperforms SOTA methods in both retrieval precision and recall. Consequently, an autoformalizer equipped with DDR shows consistent performance advantages in both single-attempt accuracy and multi-attempt stability compared to models using traditional selection-based RAG methods.
STAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Sep 07, 2022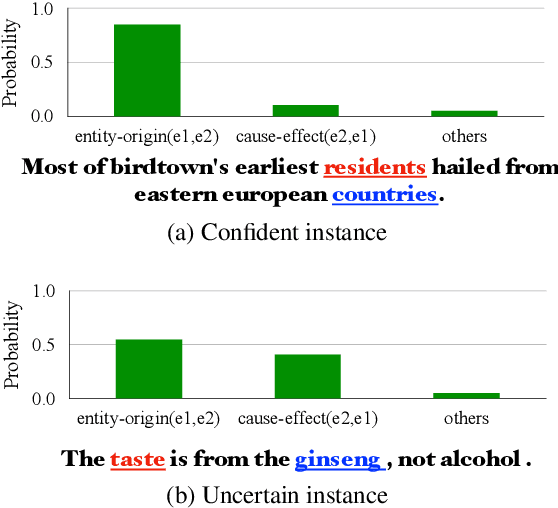
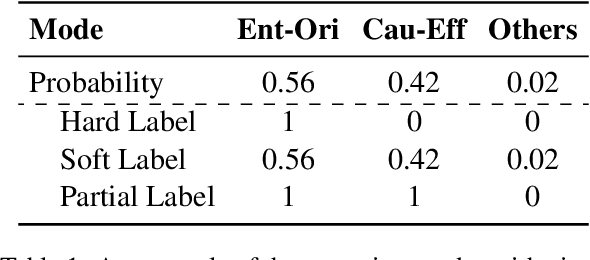
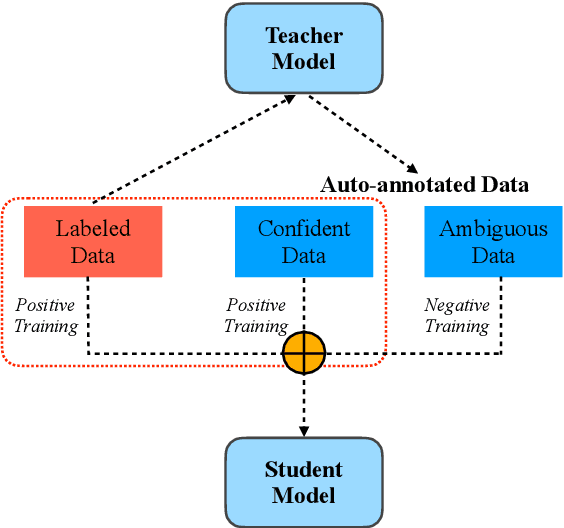
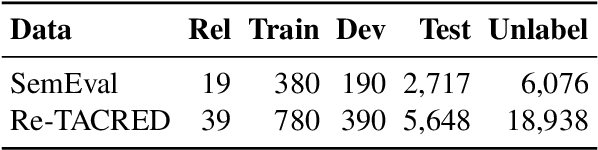
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD