 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
May 10, 2026We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
CAAL: Confidence-Aware Active Learning for Heteroscedastic Atmospheric Regression
Feb 12, 2026Quantifying the impacts of air pollution on health and climate relies on key atmospheric particle properties such as toxicity and hygroscopicity. However, these properties typically require complex observational techniques or expensive particle-resolved numerical simulations, limiting the availability of labeled data. We therefore estimate these hard-to-measure particle properties from routinely available observations (e.g., air pollutant concentrations and meteorological conditions). Because routine observations only indirectly reflect particle composition and structure, the mapping from routine observations to particle properties is noisy and input-dependent, yielding a heteroscedastic regression setting. With a limited and costly labeling budget, the central challenge is to select which samples to measure or simulate. While active learning is a natural approach, most acquisition strategies rely on predictive uncertainty. Under heteroscedastic noise, this signal conflates reducible epistemic uncertainty with irreducible aleatoric uncertainty, causing limited budgets to be wasted in noise-dominated regions. To address this challenge, we propose a confidence-aware active learning framework (CAAL) for efficient and robust sample selection in heteroscedastic settings. CAAL consists of two components: a decoupled uncertainty-aware training objective that separately optimises the predictive mean and noise level to stabilise uncertainty estimation, and a confidence-aware acquisition function that dynamically weights epistemic uncertainty using predicted aleatoric uncertainty as a reliability signal. Experiments on particle-resolved numerical simulations and real atmospheric observations show that CAAL consistently outperforms standard AL baselines. The proposed framework provides a practical and general solution for the efficient expansion of high-cost atmospheric particle property databases.
Local Intrinsic Dimension of Representations Predicts Alignment and Generalization in AI Models and Human Brain
Jan 30, 2026Recent work has found that neural networks with stronger generalization tend to exhibit higher representational alignment with one another across architectures and training paradigms. In this work, we show that models with stronger generalization also align more strongly with human neural activity. Moreover, generalization performance, model--model alignment, and model--brain alignment are all significantly correlated with each other. We further show that these relationships can be explained by a single geometric property of learned representations: the local intrinsic dimension of embeddings. Lower local dimension is consistently associated with stronger model--model alignment, stronger model--brain alignment, and better generalization, whereas global dimension measures fail to capture these effects. Finally, we find that increasing model capacity and training data scale systematically reduces local intrinsic dimension, providing a geometric account of the benefits of scaling. Together, our results identify local intrinsic dimension as a unifying descriptor of representational convergence in artificial and biological systems.
Understanding Generalization from Embedding Dimension and Distributional Convergence
Jan 30, 2026Deep neural networks often generalize well despite heavy over-parameterization, challenging classical parameter-based analyses. We study generalization from a representation-centric perspective and analyze how the geometry of learned embeddings controls predictive performance for a fixed trained model. We show that population risk can be bounded by two factors: (i) the intrinsic dimension of the embedding distribution, which determines the convergence rate of empirical embedding distribution to the population distribution in Wasserstein distance, and (ii) the sensitivity of the downstream mapping from embeddings to predictions, characterized by Lipschitz constants. Together, these yield an embedding-dependent error bound that does not rely on parameter counts or hypothesis class complexity. At the final embedding layer, architectural sensitivity vanishes and the bound is dominated by embedding dimension, explaining its strong empirical correlation with generalization performance. Experiments across architectures and datasets validate the theory and demonstrate the utility of embedding-based diagnostics.
Scale-Invariance Drives Convergence in AI and Brain Representations
Jun 13, 2025Despite variations in architecture and pretraining strategies, recent studies indicate that large-scale AI models often converge toward similar internal representations that also align with neural activity. We propose that scale-invariance, a fundamental structural principle in natural systems, is a key driver of this convergence. In this work, we propose a multi-scale analytical framework to quantify two core aspects of scale-invariance in AI representations: dimensional stability and structural similarity across scales. We further investigate whether these properties can predict alignment performance with functional Magnetic Resonance Imaging (fMRI) responses in the visual cortex. Our analysis reveals that embeddings with more consistent dimension and higher structural similarity across scales align better with fMRI data. Furthermore, we find that the manifold structure of fMRI data is more concentrated, with most features dissipating at smaller scales. Embeddings with similar scale patterns align more closely with fMRI data. We also show that larger pretraining datasets and the inclusion of language modalities enhance the scale-invariance properties of embeddings, further improving neural alignment. Our findings indicate that scale-invariance is a fundamental structural principle that bridges artificial and biological representations, providing a new framework for evaluating the structural quality of human-like AI systems.
Reinforcement Learning (RL) Meets Urban Climate Modeling: Investigating the Efficacy and Impacts of RL-Based HVAC Control
May 11, 2025Reinforcement learning (RL)-based heating, ventilation, and air conditioning (HVAC) control has emerged as a promising technology for reducing building energy consumption while maintaining indoor thermal comfort. However, the efficacy of such strategies is influenced by the background climate and their implementation may potentially alter both the indoor climate and local urban climate. This study proposes an integrated framework combining RL with an urban climate model that incorporates a building energy model, aiming to evaluate the efficacy of RL-based HVAC control across different background climates, impacts of RL strategies on indoor climate and local urban climate, and the transferability of RL strategies across cities. Our findings reveal that the reward (defined as a weighted combination of energy consumption and thermal comfort) and the impacts of RL strategies on indoor climate and local urban climate exhibit marked variability across cities with different background climates. The sensitivity of reward weights and the transferability of RL strategies are also strongly influenced by the background climate. Cities in hot climates tend to achieve higher rewards across most reward weight configurations that balance energy consumption and thermal comfort, and those cities with more varying atmospheric temperatures demonstrate greater RL strategy transferability. These findings underscore the importance of thoroughly evaluating RL-based HVAC control strategies in diverse climatic contexts. This study also provides a new insight that city-to-city learning will potentially aid the deployment of RL-based HVAC control.
Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Apr 05, 2024



The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
STAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Sep 07, 2022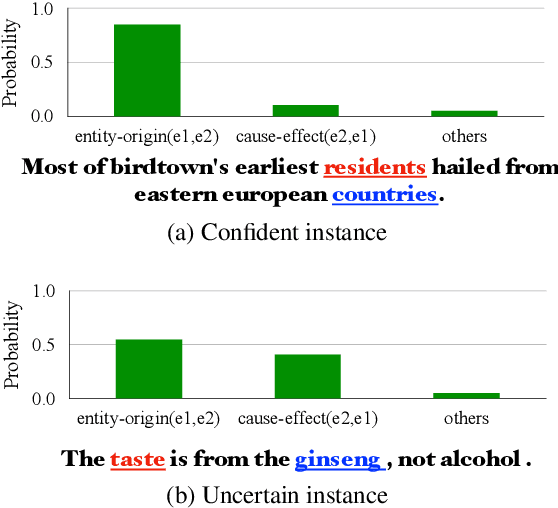
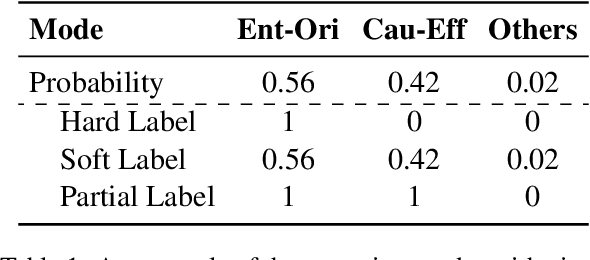
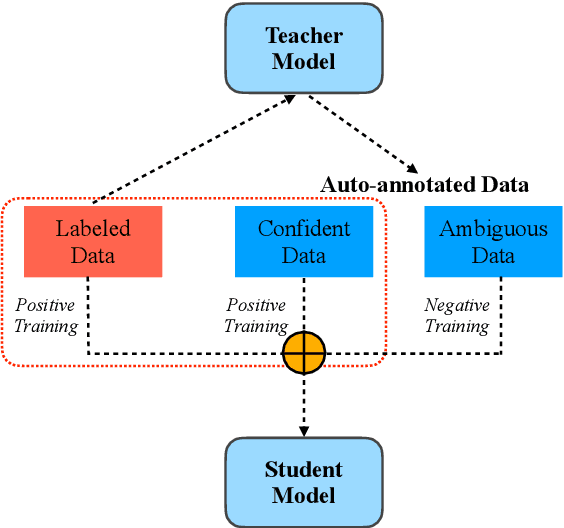
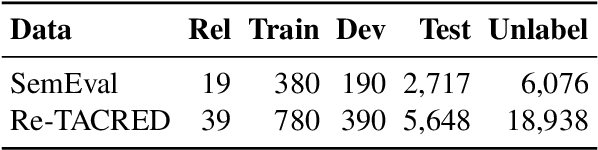
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD