 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Idiom Paraphrasing
Apr 20, 2022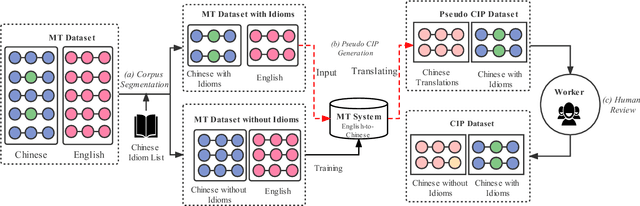
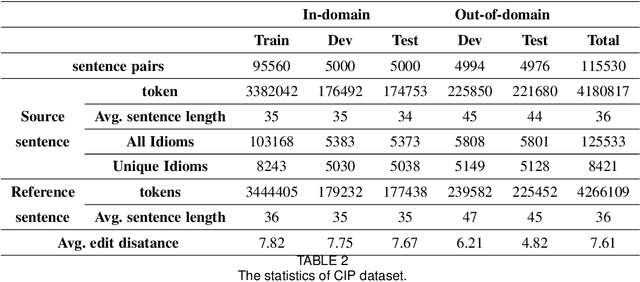
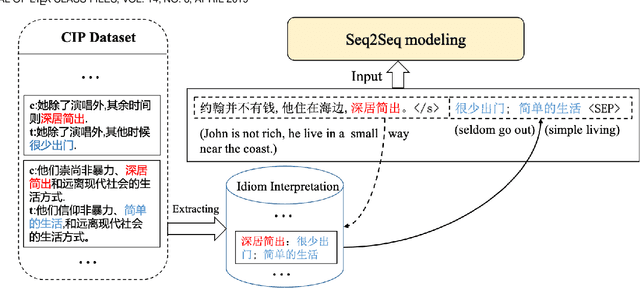

Idioms, are a kind of idiomatic expression in Chinese, most of which consist of four Chinese characters. Due to the properties of non-compositionality and metaphorical meaning, Chinese Idioms are hard to be understood by children and non-native speakers. This study proposes a novel task, denoted as Chinese Idiom Paraphrasing (CIP). CIP aims to rephrase idioms-included sentences to non-idiomatic ones under the premise of preserving the original sentence's meaning. Since the sentences without idioms are easier handled by Chinese NLP systems, CIP can be used to pre-process Chinese datasets, thereby facilitating and improving the performance of Chinese NLP tasks, e.g., machine translation system, Chinese idiom cloze, and Chinese idiom embeddings. In this study, CIP task is treated as a special paraphrase generation task. To circumvent difficulties in acquiring annotations, we first establish a large-scale CIP dataset based on human and machine collaboration, which consists of 115,530 sentence pairs. We further deploy three baselines and two novel CIP approaches to deal with CIP problems. The results show that the proposed methods have better performances than the baselines based on the established CIP dataset.
Prompt-Learning for Short Text Classification
Mar 31, 2022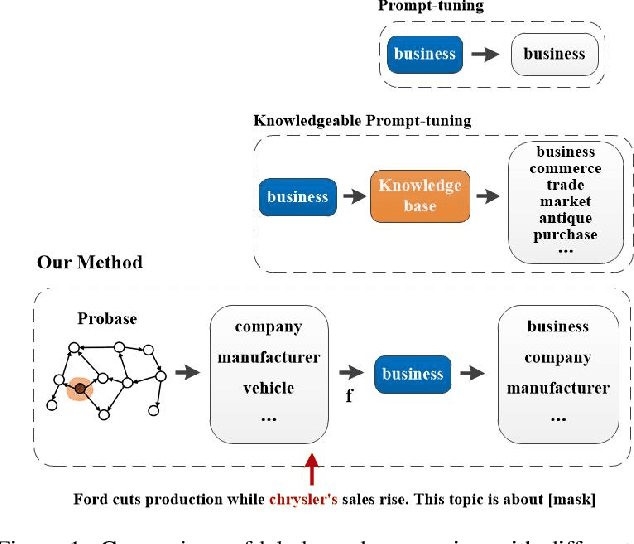

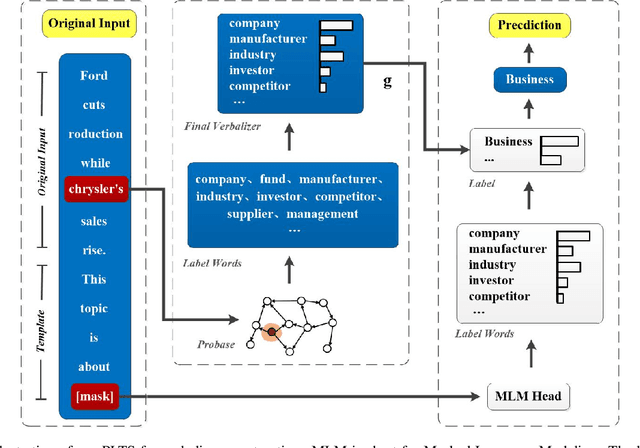
In the short text, the extremely short length, feature sparsity, and high ambiguity pose huge challenges to classification tasks. Recently, as an effective method for tuning Pre-trained Language Models for specific downstream tasks, prompt-learning has attracted a vast amount of attention and research. The main intuition behind the prompt-learning is to insert the template into the input and convert the text classification tasks into equivalent cloze-style tasks. However, most prompt-learning methods expand label words manually or only consider the class name for knowledge incorporating in cloze-style prediction, which will inevitably incur omissions and bias in short text classification tasks. In this paper, we propose a simple short text classification approach that makes use of prompt-learning based on knowledgeable expansion. Taking the special characteristics of short text into consideration, the method can consider both the short text itself and class name during expanding label words space. Specifically, the top $N$ concepts related to the entity in the short text are retrieved from the open Knowledge Graph like Probase, and we further refine the expanded label words by the distance calculation between selected concepts and class labels. Experimental results show that our approach obtains obvious improvement compared with other fine-tuning, prompt-learning, and knowledgeable prompt-tuning methods, outperforming the state-of-the-art by up to 6 Accuracy points on three well-known datasets.
Learning Relation-Specific Representations for Few-shot Knowledge Graph Completion
Mar 22, 2022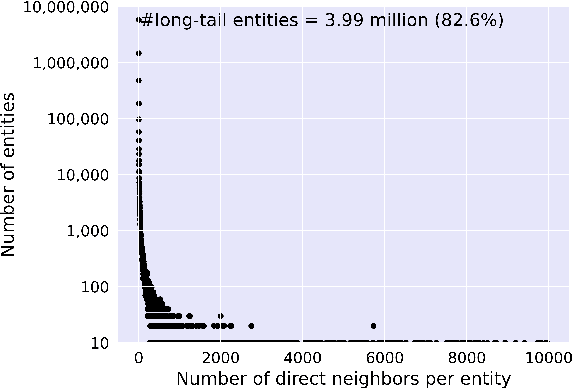
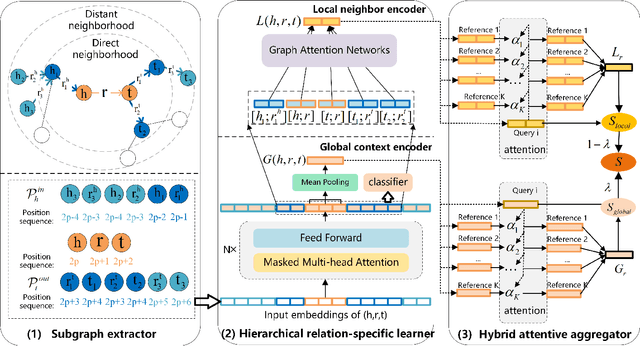

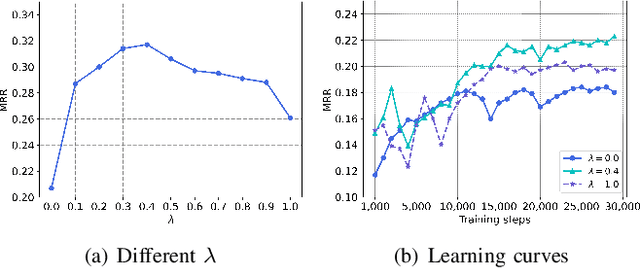
Recent years have witnessed increasing interest in few-shot knowledge graph completion (FKGC), which aims to infer unseen query triples for a few-shot relation using a handful of reference triples of the relation. The primary focus of existing FKGC methods lies in learning the relation representations that can reflect the common information shared by the query and reference triples. To this end, these methods learn the embeddings of entities with their direct neighbors, and use the concatenation of the entity embeddings as the relation representations. However, the entity embeddings learned only from direct neighborhoods may have low expressiveness when the entity has sparse neighbors or shares a common local neighborhood with other entities. Moreover, the embeddings of two entities are insufficient to represent the semantic information of their relationship, especially when they have multiple relations. To address these issues, we propose a Relation-Specific Context Learning (RSCL) framework, which exploits graph contexts of triples to capture the semantic information of relations and entities simultaneously. Specifically, we first extract graph contexts for each triple, which can provide long-term entity-relation dependencies. To model the graph contexts, we then develop a hierarchical relation-specific learner to learn global and local relation-specific representations for relations by capturing contextualized information of triples and incorporating local information of entities. Finally, we utilize the learned representations to predict the likelihood of the query triples. Experimental results on two public datasets demonstrate that RSCL outperforms state-of-the-art FKGC methods.
OPP-Miner: Order-preserving sequential pattern mining
Feb 09, 2022
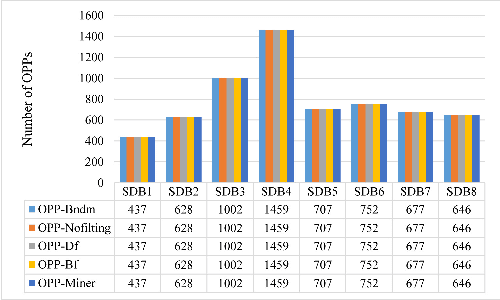
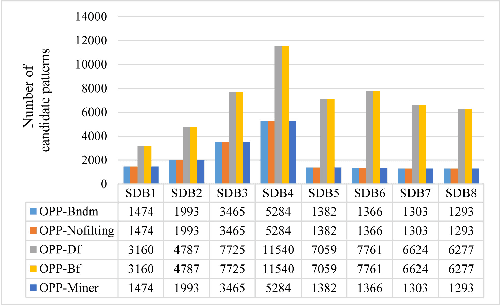
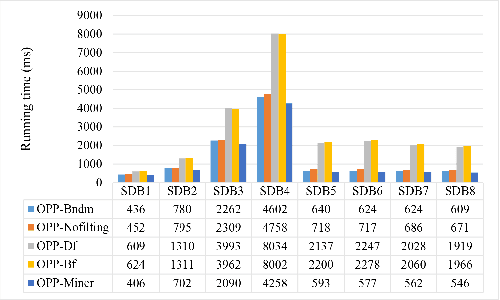
A time series is a collection of measurements in chronological order. Discovering patterns from time series is useful in many domains, such as stock analysis, disease detection, and weather forecast. To discover patterns, existing methods often convert time series data into another form, such as nominal/symbolic format, to reduce dimensionality, which inevitably deviates the data values. Moreover, existing methods mainly neglect the order relationships between time series values. To tackle these issues, inspired by order-preserving matching, this paper proposes an Order-Preserving sequential Pattern (OPP) mining method, which represents patterns based on the order relationships of the time series data. An inherent advantage of such representation is that the trend of a time series can be represented by the relative order of the values underneath the time series data. To obtain frequent trends in time series, we propose the OPP-Miner algorithm to mine patterns with the same trend (sub-sequences with the same relative order). OPP-Miner employs the filtration and verification strategies to calculate the support and uses pattern fusion strategy to generate candidate patterns. To compress the result set, we also study finding the maximal OPPs. Experiments validate that OPP-Miner is not only efficient and scalable but can also discover similar sub-sequences in time series. In addition, case studies show that our algorithms have high utility in analyzing the COVID-19 epidemic by identifying critical trends and improve the clustering performance.
Towards Efficient Local Causal Structure Learning
Feb 28, 2021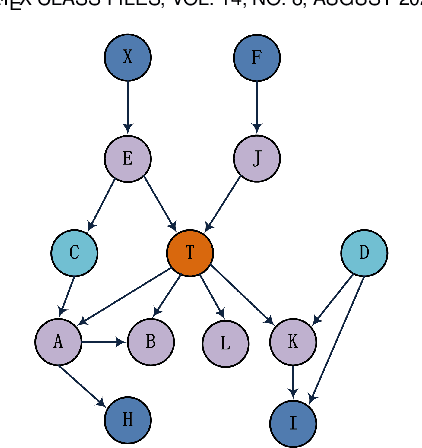
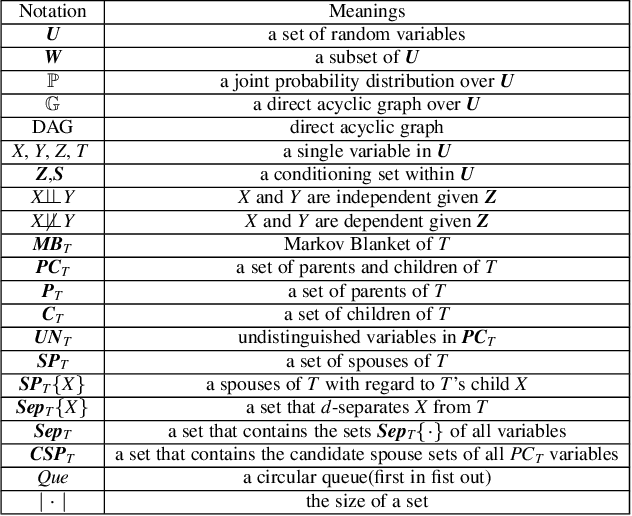
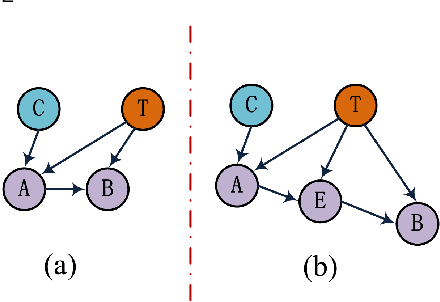

Local causal structure learning aims to discover and distinguish direct causes (parents) and direct effects (children) of a variable of interest from data. While emerging successes have been made, existing methods need to search a large space to distinguish direct causes from direct effects of a target variable T. To tackle this issue, we propose a novel Efficient Local Causal Structure learning algorithm, named ELCS. Specifically, we first propose the concept of N-structures, then design an efficient Markov Blanket (MB) discovery subroutine to integrate MB learning with N-structures to learn the MB of T and simultaneously distinguish direct causes from direct effects of T. With the proposed MB subroutine, ELCS starts from the target variable, sequentially finds MBs of variables connected to the target variable and simultaneously constructs local causal structures over MBs until the direct causes and direct effects of the target variable have been distinguished. Using eight Bayesian networks the extensive experiments have validated that ELCS achieves better accuracy and efficiency than the state-of-the-art algorithms.
Trustworthy Preference Completion in Social Choice
Dec 14, 2020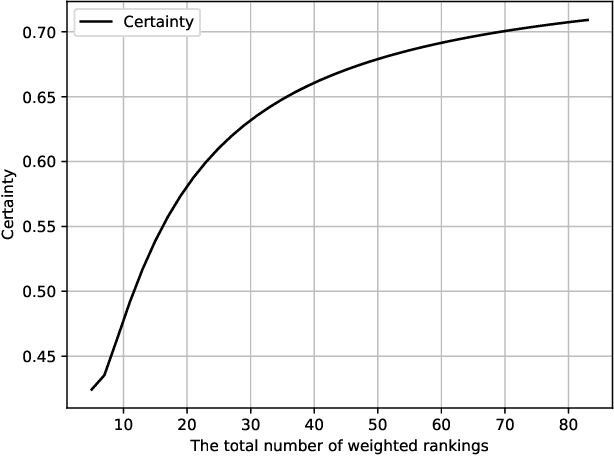
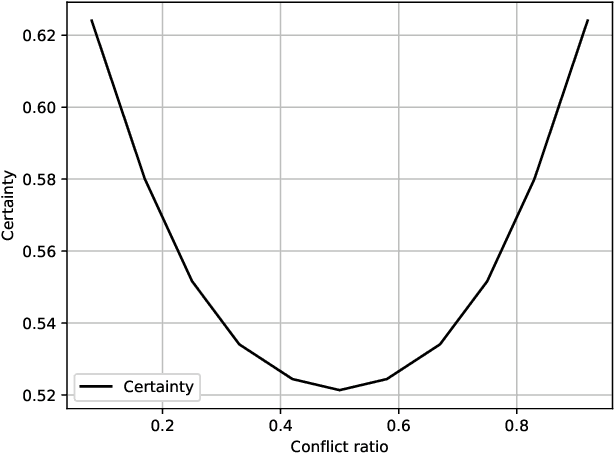
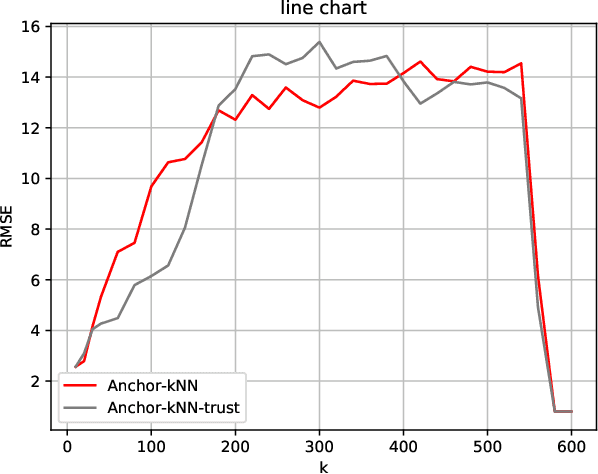
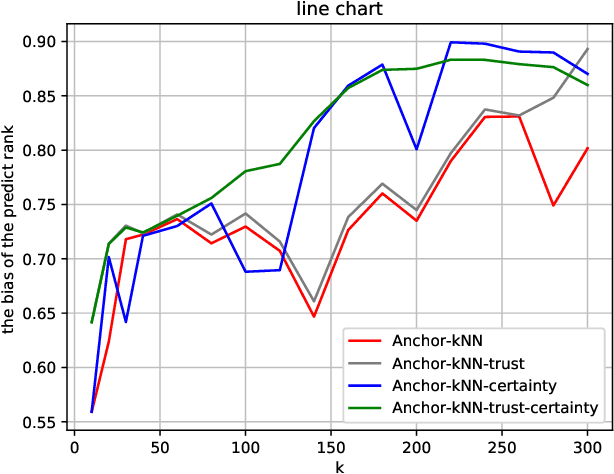
As from time to time it is impractical to ask agents to provide linear orders over all alternatives, for these partial rankings it is necessary to conduct preference completion. Specifically, the personalized preference of each agent over all the alternatives can be estimated with partial rankings from neighboring agents over subsets of alternatives. However, since the agents' rankings are nondeterministic, where they may provide rankings with noise, it is necessary and important to conduct the trustworthy preference completion. Hence, in this paper firstly, a trust-based anchor-kNN algorithm is proposed to find $k$-nearest trustworthy neighbors of the agent with trust-oriented Kendall-Tau distances, which will handle the cases when an agent exhibits irrational behaviors or provides only noisy rankings. Then, for alternative pairs, a bijection can be built from the ranking space to the preference space, and its certainty and conflict can be evaluated based on a well-built statistical measurement Probability-Certainty Density Function. Therefore, a certain common voting rule for the first $k$ trustworthy neighboring agents based on certainty and conflict can be taken to conduct the trustworthy preference completion. The properties of the proposed certainty and conflict have been studied empirically, and the proposed approach has been experimentally validated compared to state-of-arts approaches with several data sets.
Chinese Lexical Simplification
Oct 14, 2020

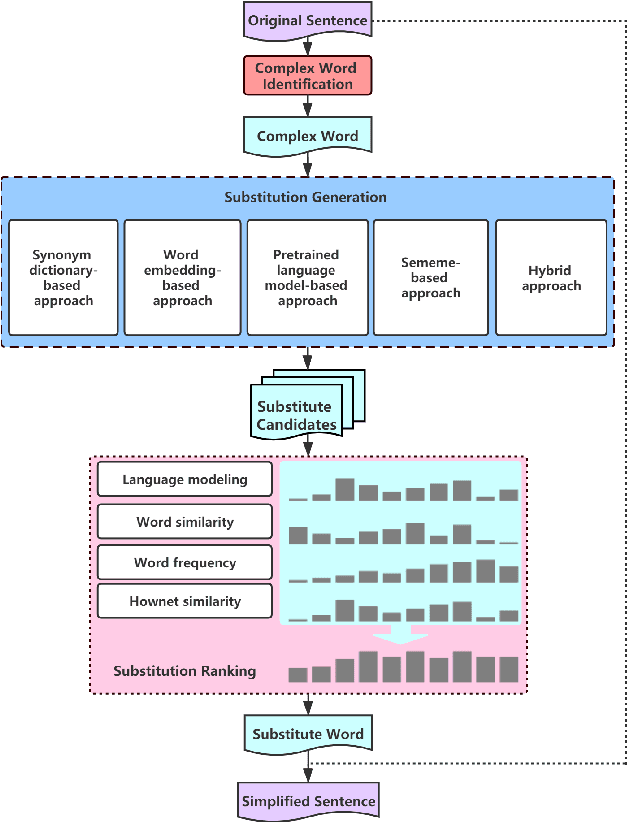
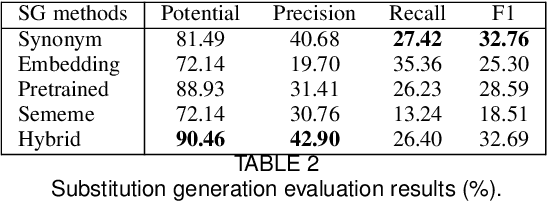
Lexical simplification has attracted much attention in many languages, which is the process of replacing complex words in a given sentence with simpler alternatives of equivalent meaning. Although the richness of vocabulary in Chinese makes the text very difficult to read for children and non-native speakers, there is no research work for Chinese lexical simplification (CLS) task. To circumvent difficulties in acquiring annotations, we manually create the first benchmark dataset for CLS, which can be used for evaluating the lexical simplification systems automatically. In order to acquire more thorough comparison, we present five different types of methods as baselines to generate substitute candidates for the complex word that include synonym-based approach, word embedding-based approach, pretrained language model-based approach, sememe-based approach, and a hybrid approach. Finally, we design the experimental evaluation of these baselines and discuss their advantages and disadvantages. To our best knowledge, this is the first study for CLS task.
A Survey on Large-scale Machine Learning
Aug 10, 2020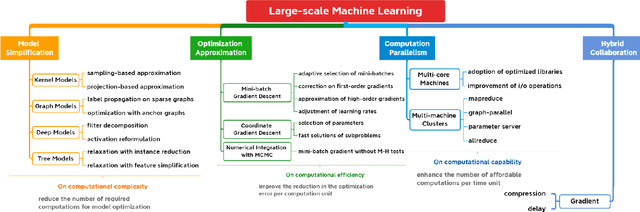


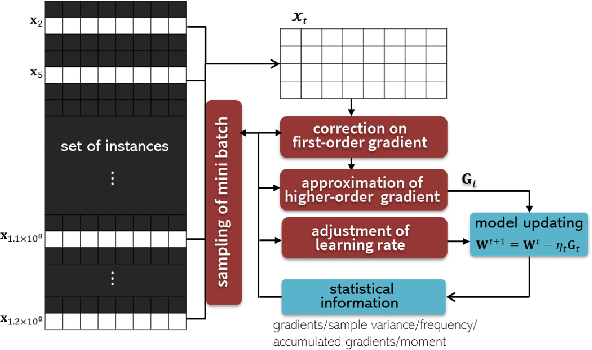
Machine learning can provide deep insights into data, allowing machines to make high-quality predictions and having been widely used in real-world applications, such as text mining, visual classification, and recommender systems. However, most sophisticated machine learning approaches suffer from huge time costs when operating on large-scale data. This issue calls for the need of {Large-scale Machine Learning} (LML), which aims to learn patterns from big data with comparable performance efficiently. In this paper, we offer a systematic survey on existing LML methods to provide a blueprint for the future developments of this area. We first divide these LML methods according to the ways of improving the scalability: 1) model simplification on computational complexities, 2) optimization approximation on computational efficiency, and 3) computation parallelism on computational capabilities. Then we categorize the methods in each perspective according to their targeted scenarios and introduce representative methods in line with intrinsic strategies. Lastly, we analyze their limitations and discuss potential directions as well as open issues that are promising to address in the future.
LSBert: A Simple Framework for Lexical Simplification
Jun 25, 2020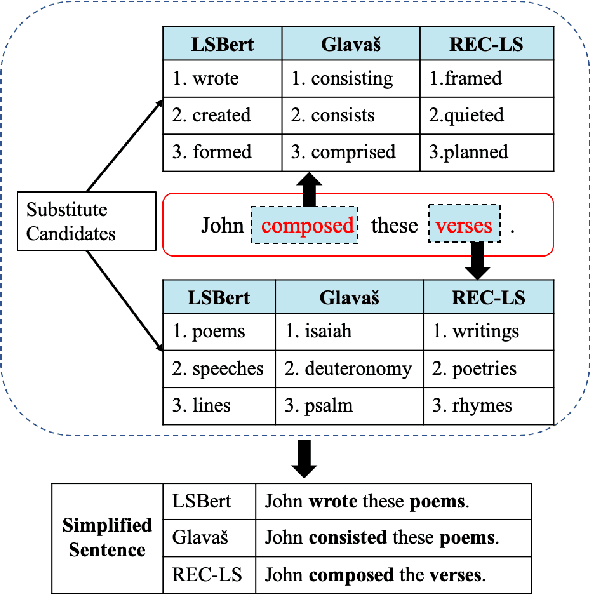
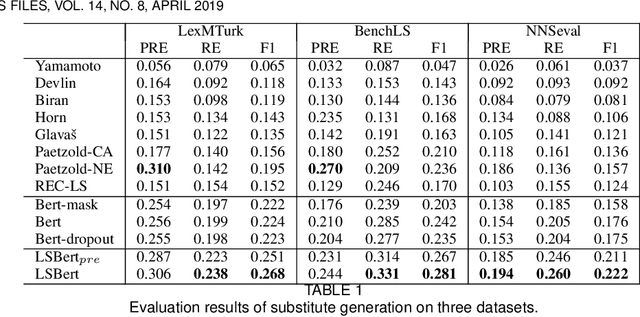
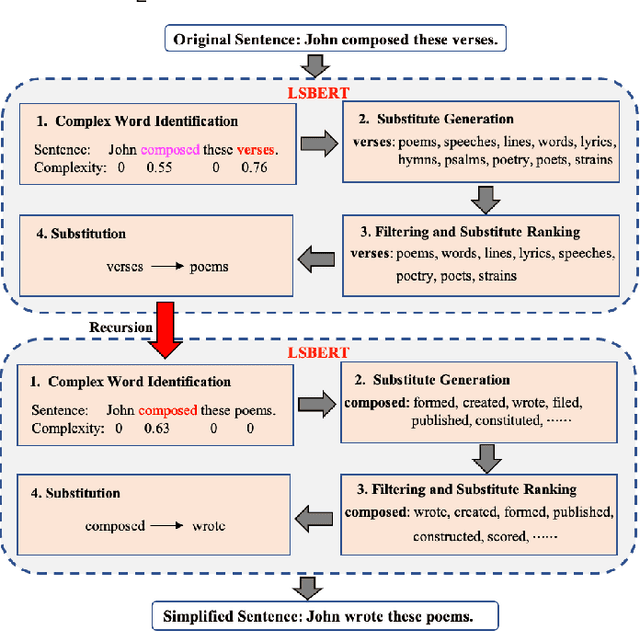
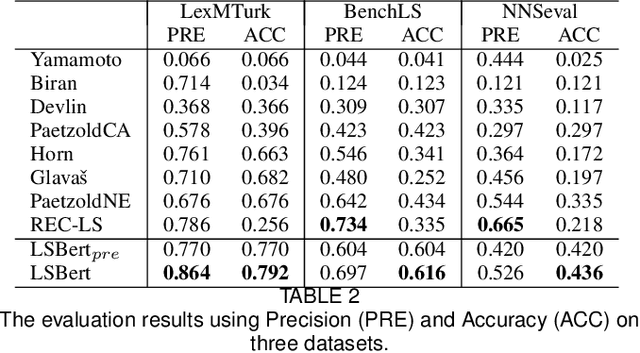
Lexical simplification (LS) aims to replace complex words in a given sentence with their simpler alternatives of equivalent meaning, to simplify the sentence. Recently unsupervised lexical simplification approaches only rely on the complex word itself regardless of the given sentence to generate candidate substitutions, which will inevitably produce a large number of spurious candidates. In this paper, we propose a lexical simplification framework LSBert based on pretrained representation model Bert, that is capable of (1) making use of the wider context when both detecting the words in need of simplification and generating substitue candidates, and (2) taking five high-quality features into account for ranking candidates, including Bert prediction order, Bert-based language model, and the paraphrase database PPDB, in addition to the word frequency and word similarity commonly used in other LS methods. We show that our system outputs lexical simplifications that are grammatically correct and semantically appropriate, and obtains obvious improvement compared with these baselines, outperforming the state-of-the-art by 29.8 Accuracy points on three well-known benchmarks.
Causality-based Feature Selection: Methods and Evaluations
Nov 17, 2019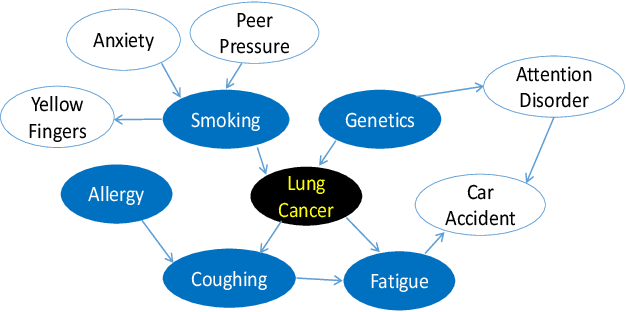
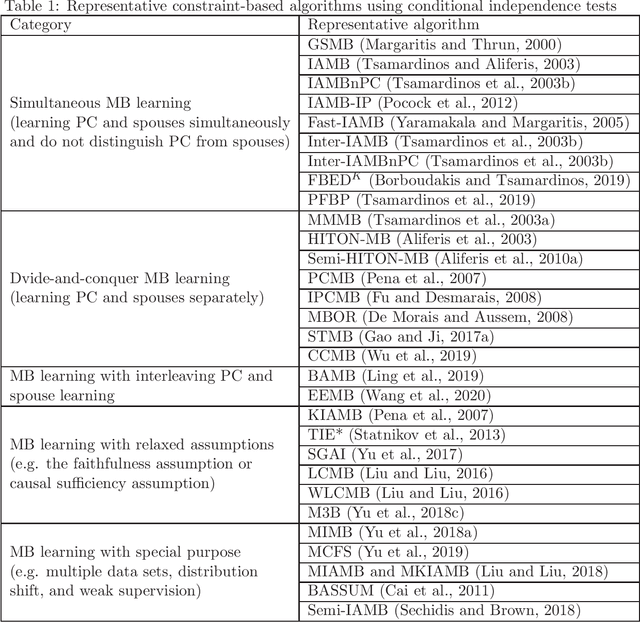
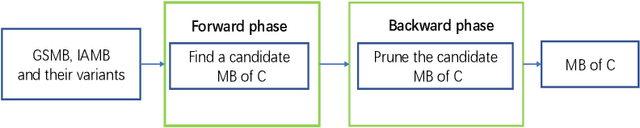
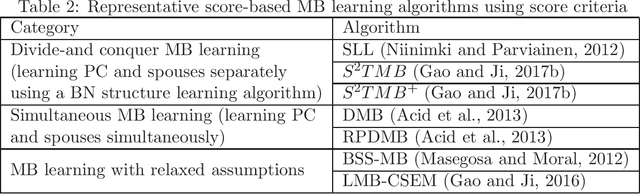
Feature selection is a crucial preprocessing step in data analytics and machine learning. Classical feature selection algorithms select features based on the correlations between predictive features and the class variable and do not attempt to capture causal relationships between them. It has been shown that the knowledge about the causal relationships between features and the class variable has potential benefits for building interpretable and robust prediction models, since causal relationships imply the underlying mechanism of a system. Consequently, causality-based feature selection has gradually attracted greater attentions and many algorithms have been proposed. In this paper, we present a comprehensive review of recent advances in causality-based feature selection. To facilitate the development of new algorithms in the research area and make it easy for the comparisons between new methods and existing ones, we develop the first open-source package, called CausalFS, which consists of most of the representative causality-based feature selection algorithms (available at https://github.com/kuiy/CausalFS). Using CausalFS, we conduct extensive experiments to compare the representative algorithms with both synthetic and real-world data sets. Finally, we discuss some challenging problems to be tackled in future causality-based feature selection research.