 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Skin Disease Diagnosis: Interpretable Visual Concept Discovery with SAM Empowerment
Sep 14, 2024



Current AI-assisted skin image diagnosis has achieved dermatologist-level performance in classifying skin cancer, driven by rapid advancements in deep learning architectures. However, unlike traditional vision tasks, skin images in general present unique challenges due to the limited availability of well-annotated datasets, complex variations in conditions, and the necessity for detailed interpretations to ensure patient safety. Previous segmentation methods have sought to reduce image noise and enhance diagnostic performance, but these techniques require fine-grained, pixel-level ground truth masks for training. In contrast, with the rise of foundation models, the Segment Anything Model (SAM) has been introduced to facilitate promptable segmentation, enabling the automation of the segmentation process with simple yet effective prompts. Efforts applying SAM predominantly focus on dermatoscopy images, which present more easily identifiable lesion boundaries than clinical photos taken with smartphones. This limitation constrains the practicality of these approaches to real-world applications. To overcome the challenges posed by noisy clinical photos acquired via non-standardized protocols and to improve diagnostic accessibility, we propose a novel Cross-Attentive Fusion framework for interpretable skin lesion diagnosis. Our method leverages SAM to generate visual concepts for skin diseases using prompts, integrating local visual concepts with global image features to enhance model performance. Extensive evaluation on two skin disease datasets demonstrates our proposed method's effectiveness on lesion diagnosis and interpretability.
Adversarial Attacks to Multi-Modal Models
Sep 10, 2024



Multi-modal models have gained significant attention due to their powerful capabilities. These models effectively align embeddings across diverse data modalities, showcasing superior performance in downstream tasks compared to their unimodal counterparts. Recent study showed that the attacker can manipulate an image or audio file by altering it in such a way that its embedding matches that of an attacker-chosen targeted input, thereby deceiving downstream models. However, this method often underperforms due to inherent disparities in data from different modalities. In this paper, we introduce CrossFire, an innovative approach to attack multi-modal models. CrossFire begins by transforming the targeted input chosen by the attacker into a format that matches the modality of the original image or audio file. We then formulate our attack as an optimization problem, aiming to minimize the angular deviation between the embeddings of the transformed input and the modified image or audio file. Solving this problem determines the perturbations to be added to the original media. Our extensive experiments on six real-world benchmark datasets reveal that CrossFire can significantly manipulate downstream tasks, surpassing existing attacks. Additionally, we evaluate six defensive strategies against CrossFire, finding that current defenses are insufficient to counteract our CrossFire.
Residual-Conditioned Optimal Transport: Towards Structure-preserving Unpaired and Paired Image Restoration
May 05, 2024



Deep learning-based image restoration methods have achieved promising performance. However, how to faithfully preserve the structure of the original image remains challenging. To address this challenge, we propose a novel Residual-Conditioned Optimal Transport (RCOT) approach, which models the image restoration as an optimal transport (OT) problem for both unpaired and paired settings, integrating the transport residual as a unique degradation-specific cue for both the transport cost and the transport map. Specifically, we first formalize a Fourier residual-guided OT objective by incorporating the degradation-specific information of the residual into the transport cost. Based on the dual form of the OT formulation, we design the transport map as a two-pass RCOT map that comprises a base model and a refinement process, in which the transport residual is computed by the base model in the first pass and then encoded as a degradation-specific embedding to condition the second-pass restoration. By duality, the RCOT problem is transformed into a minimax optimization problem, which can be solved by adversarially training neural networks. Extensive experiments on multiple restoration tasks show the effectiveness of our approach in terms of both distortion measures and perceptual quality. Particularly, RCOT restores images with more faithful structural details compared to state-of-the-art methods.
Opportunities and challenges of ChatGPT for design knowledge management
Apr 06, 2023



Recent advancements in Natural Language Processing have opened up new possibilities for the development of large language models like ChatGPT, which can facilitate knowledge management in the design process by providing designers with access to a vast array of relevant information. However, integrating ChatGPT into the design process also presents new challenges. In this paper, we provide a concise review of the classification and representation of design knowledge, and past efforts to support designers in acquiring knowledge. We analyze the opportunities and challenges that ChatGPT presents for knowledge management in design and propose promising future research directions. A case study is conducted to validate the advantages and drawbacks of ChatGPT, showing that designers can acquire targeted knowledge from various domains, but the quality of the acquired knowledge is highly dependent on the prompt.
Human Emotion Knowledge Representation Emerges in Large Language Model and Supports Discrete Emotion Inference
Feb 21, 2023


How humans infer discrete emotions is a fundamental research question in the field of psychology. While conceptual knowledge about emotions (emotion knowledge) has been suggested to be essential for emotion inference, evidence to date is mostly indirect and inconclusive. As the large language models (LLMs) have been shown to support effective representations of various human conceptual knowledge, the present study further employed artificial neurons in LLMs to investigate the mechanism of human emotion inference. With artificial neurons activated by prompts, the LLM (RoBERTa) demonstrated a similar conceptual structure of 27 discrete emotions as that of human behaviors. Furthermore, the LLM-based conceptual structure revealed a human-like reliance on 14 underlying conceptual attributes of emotions for emotion inference. Most importantly, by manipulating attribute-specific neurons, we found that the corresponding LLM's emotion inference performance deteriorated, and the performance deterioration was correlated to the effectiveness of representations of the conceptual attributes on the human side. Our findings provide direct evidence for the emergence of emotion knowledge representation in large language models and suggest its casual support for discrete emotion inference.
GPTR: Gestalt-Perception Transformer for Diagram Object Detection
Dec 29, 2022



Diagram object detection is the key basis of practical applications such as textbook question answering. Because the diagram mainly consists of simple lines and color blocks, its visual features are sparser than those of natural images. In addition, diagrams usually express diverse knowledge, in which there are many low-frequency object categories in diagrams. These lead to the fact that traditional data-driven detection model is not suitable for diagrams. In this work, we propose a gestalt-perception transformer model for diagram object detection, which is based on an encoder-decoder architecture. Gestalt perception contains a series of laws to explain human perception, that the human visual system tends to perceive patches in an image that are similar, close or connected without abrupt directional changes as a perceptual whole object. Inspired by these thoughts, we build a gestalt-perception graph in transformer encoder, which is composed of diagram patches as nodes and the relationships between patches as edges. This graph aims to group these patches into objects via laws of similarity, proximity, and smoothness implied in these edges, so that the meaningful objects can be effectively detected. The experimental results demonstrate that the proposed GPTR achieves the best results in the diagram object detection task. Our model also obtains comparable results over the competitors in natural image object detection.
Dynamic Event-Triggered Discrete-Time Linear Time-Varying System with Privacy-Preservation
Oct 28, 2022This paper focuses on discrete-time wireless sensor networks with privacy-preservation. In practical applications, information exchange between sensors is subject to attacks. For the information leakage caused by the attack during the information transmission process, privacy-preservation is introduced for system states. To make communication resources more effectively utilized, a dynamic event-triggered set-membership estimator is designed. Moreover, the privacy of the system is analyzed to ensure the security of the real data. As a result, the set-membership estimator with differential privacy is analyzed using recursive convex optimization. Then the steady-state performance of the system is studied. Finally, one example is presented to demonstrate the feasibility of the proposed distributed filter containing privacy-preserving analysis.
A Multi-purpose Real Haze Benchmark with Quantifiable Haze Levels and Ground Truth
Jun 13, 2022


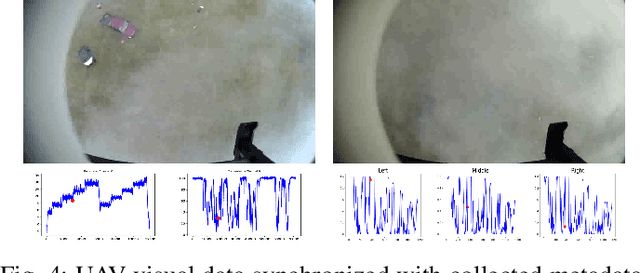
Imagery collected from outdoor visual environments is often degraded due to the presence of dense smoke or haze. A key challenge for research in scene understanding in these degraded visual environments (DVE) is the lack of representative benchmark datasets. These datasets are required to evaluate state-of-the-art object recognition and other computer vision algorithms in degraded settings. In this paper, we address some of these limitations by introducing the first paired real image benchmark dataset with hazy and haze-free images, and in-situ haze density measurements. This dataset was produced in a controlled environment with professional smoke generating machines that covered the entire scene, and consists of images captured from the perspective of both an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV). We also evaluate a set of representative state-of-the-art dehazing approaches as well as object detectors on the dataset. The full dataset presented in this paper, including the ground truth object classification bounding boxes and haze density measurements, is provided for the community to evaluate their algorithms at: https://a2i2-archangel.vision. A subset of this dataset has been used for the Object Detection in Haze Track of CVPR UG2 2022 challenge.
E^2TAD: An Energy-Efficient Tracking-based Action Detector
Apr 09, 2022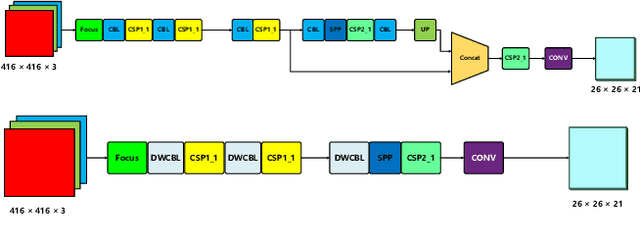

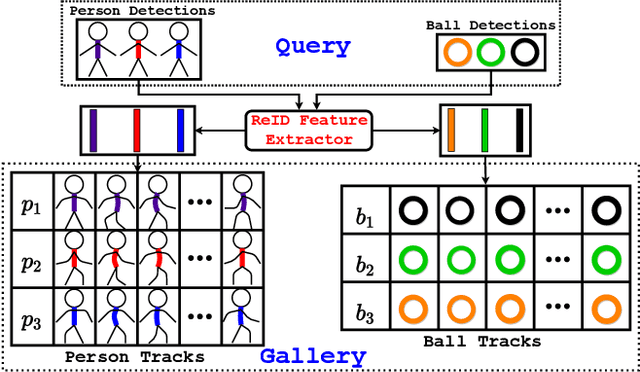
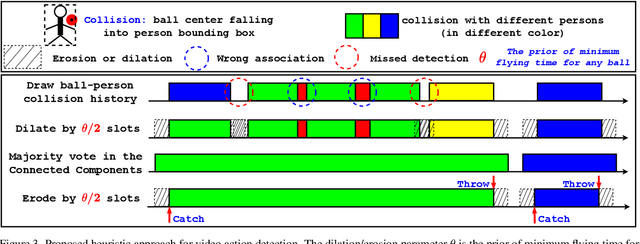
Video action detection (spatio-temporal action localization) is usually the starting point for human-centric intelligent analysis of videos nowadays. It has high practical impacts for many applications across robotics, security, healthcare, etc. The two-stage paradigm of Faster R-CNN inspires a standard paradigm of video action detection in object detection, i.e., firstly generating person proposals and then classifying their actions. However, none of the existing solutions could provide fine-grained action detection to the "who-when-where-what" level. This paper presents a tracking-based solution to accurately and efficiently localize predefined key actions spatially (by predicting the associated target IDs and locations) and temporally (by predicting the time in exact frame indices). This solution won first place in the UAV-Video Track of 2021 Low-Power Computer Vision Challenge (LPCVC).
Learning First-Order Rules with Relational Path Contrast for Inductive Relation Reasoning
Oct 17, 2021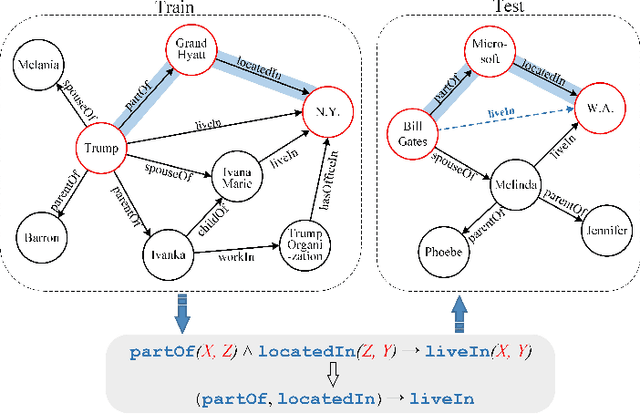
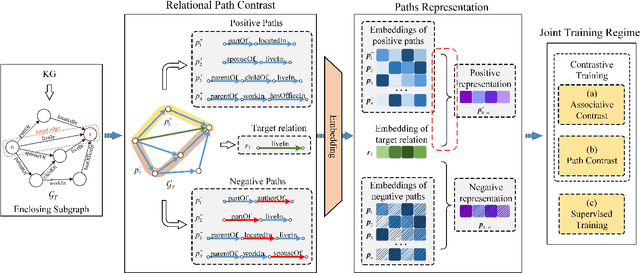
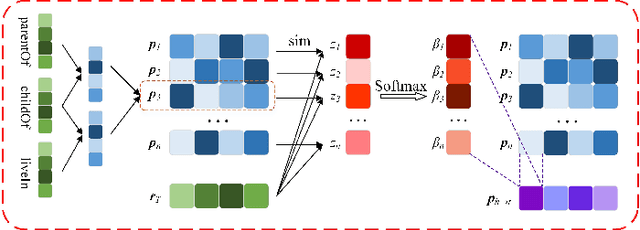
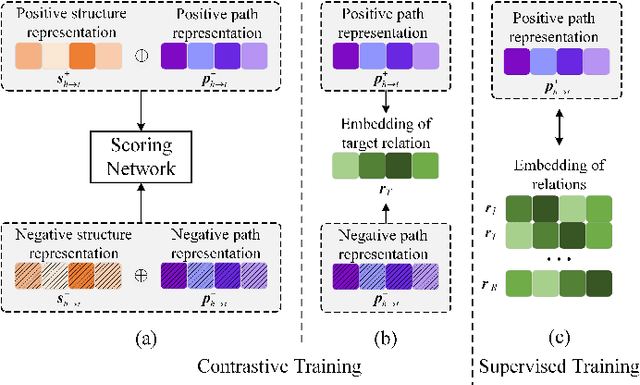
Relation reasoning in knowledge graphs (KGs) aims at predicting missing relations in incomplete triples, whereas the dominant paradigm is learning the embeddings of relations and entities, which is limited to a transductive setting and has restriction on processing unseen entities in an inductive situation. Previous inductive methods are scalable and consume less resource. They utilize the structure of entities and triples in subgraphs to own inductive ability. However, in order to obtain better reasoning results, the model should acquire entity-independent relational semantics in latent rules and solve the deficient supervision caused by scarcity of rules in subgraphs. To address these issues, we propose a novel graph convolutional network (GCN)-based approach for interpretable inductive reasoning with relational path contrast, named RPC-IR. RPC-IR firstly extracts relational paths between two entities and learns representations of them, and then innovatively introduces a contrastive strategy by constructing positive and negative relational paths. A joint training strategy considering both supervised and contrastive information is also proposed. Comprehensive experiments on three inductive datasets show that RPC-IR achieves outstanding performance comparing with the latest inductive reasoning methods and could explicitly represent logical rules for interpretability.