 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Foundation Models: Building LLMs from a Modular Perspective
Sep 04, 2024



Advancements in LLMs have recently unveiled challenges tied to computational efficiency and continual scalability due to their requirements of huge parameters, making the applications and evolution of these models on devices with limited computation resources and scenarios requiring various abilities increasingly cumbersome. Inspired by modularity within the human brain, there is a growing tendency to decompose LLMs into numerous functional modules, allowing for inference with part of modules and dynamic assembly of modules to tackle complex tasks, such as mixture-of-experts. To highlight the inherent efficiency and composability of the modular approach, we coin the term brick to represent each functional module, designating the modularized structure as configurable foundation models. In this paper, we offer a comprehensive overview and investigation of the construction, utilization, and limitation of configurable foundation models. We first formalize modules into emergent bricks - functional neuron partitions that emerge during the pre-training phase, and customized bricks - bricks constructed via additional post-training to improve the capabilities and knowledge of LLMs. Based on diverse functional bricks, we further present four brick-oriented operations: retrieval and routing, merging, updating, and growing. These operations allow for dynamic configuration of LLMs based on instructions to handle complex tasks. To verify our perspective, we conduct an empirical analysis on widely-used LLMs. We find that the FFN layers follow modular patterns with functional specialization of neurons and functional neuron partitions. Finally, we highlight several open issues and directions for future research. Overall, this paper aims to offer a fresh modular perspective on existing LLM research and inspire the future creation of more efficient and scalable foundational models.
OpenEP: Open-Ended Future Event Prediction
Aug 14, 2024Future event prediction (FEP) is a long-standing and crucial task in the world, as understanding the evolution of events enables early risk identification, informed decision-making, and strategic planning. Existing work typically treats event prediction as classification tasks and confines the outcomes of future events to a fixed scope, such as yes/no questions, candidate set, and taxonomy, which is difficult to include all possible outcomes of future events. In this paper, we introduce OpenEP (an Open-Ended Future Event Prediction task), which generates flexible and diverse predictions aligned with real-world scenarios. This is mainly reflected in two aspects: firstly, the predictive questions are diverse, covering different stages of event development and perspectives; secondly, the outcomes are flexible, without constraints on scope or format. To facilitate the study of this task, we construct OpenEPBench, an open-ended future event prediction dataset. For question construction, we pose questions from seven perspectives, including location, time, event development, event outcome, event impact, event response, and other, to facilitate an in-depth analysis and understanding of the comprehensive evolution of events. For outcome construction, we collect free-form text containing the outcomes as ground truth to provide semantically complete and detail-enriched outcomes. Furthermore, we propose StkFEP, a stakeholder-enhanced future event prediction framework, that incorporates event characteristics for open-ended settings. Our method extracts stakeholders involved in events to extend questions to gather diverse information. We also collect historically events that are relevant and similar to the question to reveal potential evolutionary patterns. Experiment results indicate that accurately predicting future events in open-ended settings is challenging for existing LLMs.
MAVEN-Fact: A Large-scale Event Factuality Detection Dataset
Jul 22, 2024Event Factuality Detection (EFD) task determines the factuality of textual events, i.e., classifying whether an event is a fact, possibility, or impossibility, which is essential for faithfully understanding and utilizing event knowledge. However, due to the lack of high-quality large-scale data, event factuality detection is under-explored in event understanding research, which limits the development of EFD community. To address these issues and provide faithful event understanding, we introduce MAVEN-Fact, a large-scale and high-quality EFD dataset based on the MAVEN dataset. MAVEN-Fact includes factuality annotations of 112,276 events, making it the largest EFD dataset. Extensive experiments demonstrate that MAVEN-Fact is challenging for both conventional fine-tuned models and large language models (LLMs). Thanks to the comprehensive annotations of event arguments and relations in MAVEN, MAVEN-Fact also supports some further analyses and we find that adopting event arguments and relations helps in event factuality detection for fine-tuned models but does not benefit LLMs. Furthermore, we preliminarily study an application case of event factuality detection and find it helps in mitigating event-related hallucination in LLMs. Our dataset and codes can be obtained from \url{https://github.com/lcy2723/MAVEN-FACT}
Finding Safety Neurons in Large Language Models
Jun 20, 2024



Large language models (LLMs) excel in various capabilities but also pose safety risks such as generating harmful content and misinformation, even after safety alignment. In this paper, we explore the inner mechanisms of safety alignment from the perspective of mechanistic interpretability, focusing on identifying and analyzing safety neurons within LLMs that are responsible for safety behaviors. We propose generation-time activation contrasting to locate these neurons and dynamic activation patching to evaluate their causal effects. Experiments on multiple recent LLMs show that: (1) Safety neurons are sparse and effective. We can restore $90$% safety performance with intervention only on about $5$% of all the neurons. (2) Safety neurons encode transferrable mechanisms. They exhibit consistent effectiveness on different red-teaming datasets. The finding of safety neurons also interprets "alignment tax". We observe that the identified key neurons for safety and helpfulness significantly overlap, but they require different activation patterns of the shared neurons. Furthermore, we demonstrate an application of safety neurons in detecting unsafe outputs before generation. Our findings may promote further research on understanding LLM alignment. The source codes will be publicly released to facilitate future research.
R-Eval: A Unified Toolkit for Evaluating Domain Knowledge of Retrieval Augmented Large Language Models
Jun 17, 2024Large language models have achieved remarkable success on general NLP tasks, but they may fall short for domain-specific problems. Recently, various Retrieval-Augmented Large Language Models (RALLMs) are proposed to address this shortcoming. However, existing evaluation tools only provide a few baselines and evaluate them on various domains without mining the depth of domain knowledge. In this paper, we address the challenges of evaluating RALLMs by introducing the R-Eval toolkit, a Python toolkit designed to streamline the evaluation of different RAG workflows in conjunction with LLMs. Our toolkit, which supports popular built-in RAG workflows and allows for the incorporation of customized testing data on the specific domain, is designed to be user-friendly, modular, and extensible. We conduct an evaluation of 21 RALLMs across three task levels and two representative domains, revealing significant variations in the effectiveness of RALLMs across different tasks and domains. Our analysis emphasizes the importance of considering both task and domain requirements when choosing a RAG workflow and LLM combination. We are committed to continuously maintaining our platform at https://github.com/THU-KEG/R-Eval to facilitate both the industry and the researchers.
TacoERE: Cluster-aware Compression for Event Relation Extraction
May 11, 2024



Event relation extraction (ERE) is a critical and fundamental challenge for natural language processing. Existing work mainly focuses on directly modeling the entire document, which cannot effectively handle long-range dependencies and information redundancy. To address these issues, we propose a cluster-aware compression method for improving event relation extraction (TacoERE), which explores a compression-then-extraction paradigm. Specifically, we first introduce document clustering for modeling event dependencies. It splits the document into intra- and inter-clusters, where intra-clusters aim to enhance the relations within the same cluster, while inter-clusters attempt to model the related events at arbitrary distances. Secondly, we utilize cluster summarization to simplify and highlight important text content of clusters for mitigating information redundancy and event distance. We have conducted extensive experiments on both pre-trained language models, such as RoBERTa, and large language models, such as ChatGPT and GPT-4, on three ERE datasets, i.e., MAVEN-ERE, EventStoryLine and HiEve. Experimental results demonstrate that TacoERE is an effective method for ERE.
Event GDR: Event-Centric Generative Document Retrieval
May 11, 2024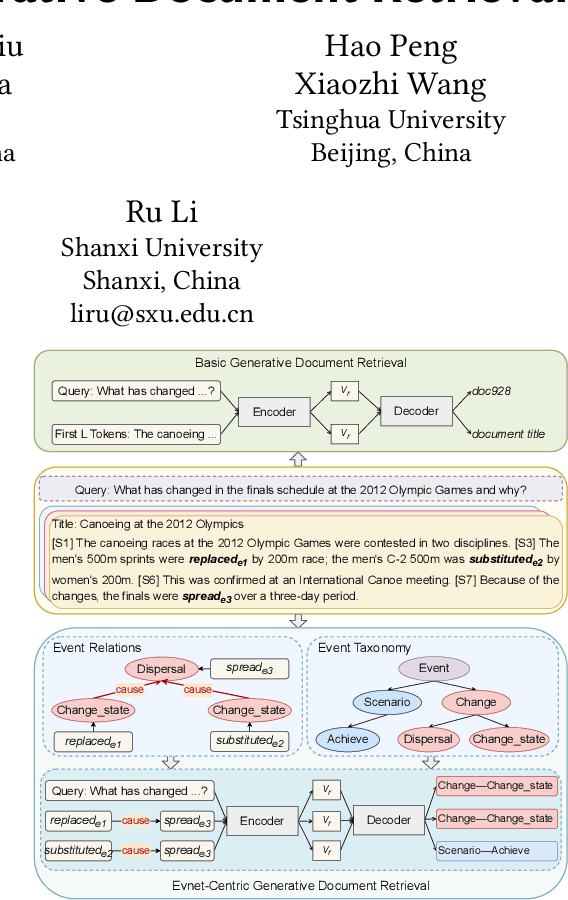
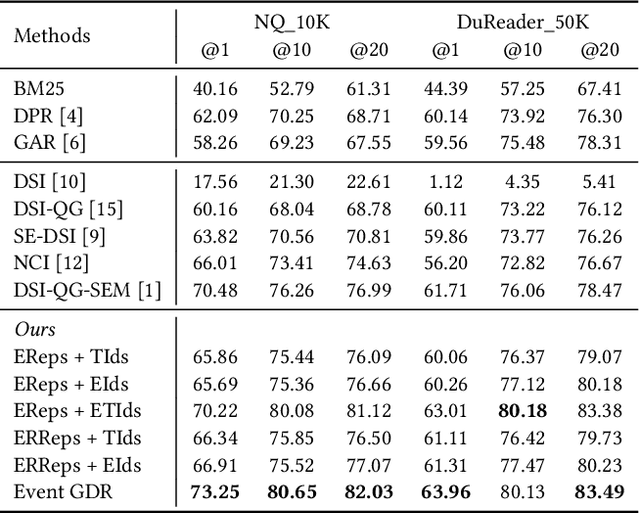
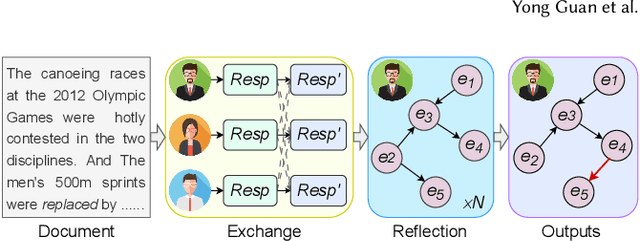
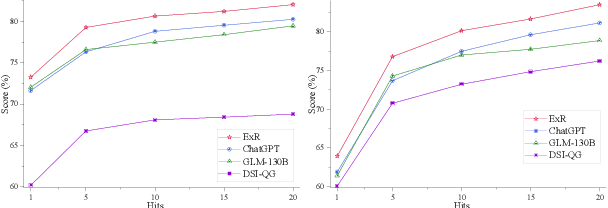
Generative document retrieval, an emerging paradigm in information retrieval, learns to build connections between documents and identifiers within a single model, garnering significant attention. However, there are still two challenges: (1) neglecting inner-content correlation during document representation; (2) lacking explicit semantic structure during identifier construction. Nonetheless, events have enriched relations and well-defined taxonomy, which could facilitate addressing the above two challenges. Inspired by this, we propose Event GDR, an event-centric generative document retrieval model, integrating event knowledge into this task. Specifically, we utilize an exchange-then-reflection method based on multi-agents for event knowledge extraction. For document representation, we employ events and relations to model the document to guarantee the comprehensiveness and inner-content correlation. For identifier construction, we map the events to well-defined event taxonomy to construct the identifiers with explicit semantic structure. Our method achieves significant improvement over the baselines on two datasets, and also hopes to provide insights for future research.
ADELIE: Aligning Large Language Models on Information Extraction
May 08, 2024Large language models (LLMs) usually fall short on information extraction (IE) tasks and struggle to follow the complex instructions of IE tasks. This primarily arises from LLMs not being aligned with humans, as mainstream alignment datasets typically do not include IE data. In this paper, we introduce ADELIE (Aligning large language moDELs on Information Extraction), an aligned LLM that effectively solves various IE tasks, including closed IE, open IE, and on-demand IE. We first collect and construct a high-quality alignment corpus IEInstruct for IE. Then we train ADELIE_SFT using instruction tuning on IEInstruct. We further train ADELIE_SFT with direct preference optimization (DPO) objective, resulting in ADELIE_DPO. Extensive experiments on various held-out IE datasets demonstrate that our models (ADELIE_SFT and ADELIE_DPO) achieve state-of-the-art (SoTA) performance among open-source models. We further explore the general capabilities of ADELIE, and experimental results reveal that their general capabilities do not exhibit a noticeable decline. We will release the code, data, and models to facilitate further research.
Event-level Knowledge Editing
Feb 20, 2024Knowledge editing aims at updating knowledge of large language models (LLMs) to prevent them from becoming outdated. Existing work edits LLMs at the level of factual knowledge triplets. However, natural knowledge updates in the real world come from the occurrences of new events rather than direct changes in factual triplets. In this paper, we propose a new task setting: event-level knowledge editing, which directly edits new events into LLMs and improves over conventional triplet-level editing on (1) Efficiency. A single event edit leads to updates in multiple entailed knowledge triplets. (2) Completeness. Beyond updating factual knowledge, event-level editing also requires considering the event influences and updating LLMs' knowledge about future trends. We construct a high-quality event-level editing benchmark ELKEN, consisting of 1,515 event edits, 6,449 questions about factual knowledge, and 10,150 questions about future tendencies. We systematically evaluate the performance of various knowledge editing methods and LLMs on this benchmark. We find that ELKEN poses significant challenges to existing knowledge editing approaches. Our codes and dataset are publicly released to facilitate further research.
MAVEN-Arg: Completing the Puzzle of All-in-One Event Understanding Dataset with Event Argument Annotation
Nov 15, 2023



Understanding events in texts is a core objective of natural language understanding, which requires detecting event occurrences, extracting event arguments, and analyzing inter-event relationships. However, due to the annotation challenges brought by task complexity, a large-scale dataset covering the full process of event understanding has long been absent. In this paper, we introduce MAVEN-Arg, which augments MAVEN datasets with event argument annotations, making the first all-in-one dataset supporting event detection, event argument extraction (EAE), and event relation extraction. As an EAE benchmark, MAVEN-Arg offers three main advantages: (1) a comprehensive schema covering 162 event types and 612 argument roles, all with expert-written definitions and examples; (2) a large data scale, containing 98,591 events and 290,613 arguments obtained with laborious human annotation; (3) the exhaustive annotation supporting all task variants of EAE, which annotates both entity and non-entity event arguments in document level. Experiments indicate that MAVEN-Arg is quite challenging for both fine-tuned EAE models and proprietary large language models (LLMs). Furthermore, to demonstrate the benefits of an all-in-one dataset, we preliminarily explore a potential application, future event prediction, with LLMs. MAVEN-Arg and our code can be obtained from https://github.com/THU-KEG/MAVEN-Argument.