 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECOND-Grasp: Semantic Contact-guided Dexterous Grasping
May 13, 2026Achieving reliable robotic manipulation, such as dexterous grasping, requires a synergy between physically stable interactions and semantic task guidance, yet these objectives are often treated as separate, disjoint goals. In this paper, we investigate how to integrate dexterous grasping techniques, i.e., physically stable grasps for object lifting and language-guided grasp generation, to achieve both physical stability and semantic understanding. To this end, we propose SECOND-Grasp (SEmantic CONtact-guided Dexterous Grasping), a unified framework that enables robotic hands to dynamically adjust grasping strategies based on semantic reasoning while ensuring physical feasibility. We begin by obtaining coarse contact proposals through vision-language reasoning to infer where contacts should occur based on object properties, followed by segmentation to localize these regions across views. To further ensure consistency across multiple viewpoints, we introduce Semantic-Geometric Consistency Refinement (SGCR), which refines initial contact predictions by enforcing semantic consistency across views and removing geometrically invalid regions, yielding reliable 3D contact maps. Then, we derive a feasible hand pose for each contact map via inverse kinematics, generating a supervision signal for policy learning. Our approach, trained on DexGraspNet, consistently outperforms baselines in lifting success rate on both seen and unseen categories, achieving 98.2% and 97.7%, respectively, while also improving intent-aware grasping by 12.8% and 26.2%. We further show promising results on additional datasets and robotic hands, including Shadow Hand and Allegro Hand.
Unintended Harms of Value-Aligned LLMs: Psychological and Empirical Insights
Jun 06, 2025



The application scope of Large Language Models (LLMs) continues to expand, leading to increasing interest in personalized LLMs that align with human values. However, aligning these models with individual values raises significant safety concerns, as certain values may correlate with harmful information. In this paper, we identify specific safety risks associated with value-aligned LLMs and investigate the psychological principles behind these challenges. Our findings reveal two key insights. (1) Value-aligned LLMs are more prone to harmful behavior compared to non-fine-tuned models and exhibit slightly higher risks in traditional safety evaluations than other fine-tuned models. (2) These safety issues arise because value-aligned LLMs genuinely generate text according to the aligned values, which can amplify harmful outcomes. Using a dataset with detailed safety categories, we find significant correlations between value alignment and safety risks, supported by psychological hypotheses. This study offers insights into the "black box" of value alignment and proposes in-context alignment methods to enhance the safety of value-aligned LLMs.
Self-Training Meets Consistency: Improving LLMs' Reasoning With Consistency-Driven Rationale Evaluation
Nov 22, 2024



Self-training approach for large language models (LLMs) improves reasoning abilities by training the models on their self-generated rationales. Previous approaches have labeled rationales that produce correct answers for a given question as appropriate for training. However, a single measure risks misjudging rationale quality, leading the models to learn flawed reasoning patterns. To address this issue, we propose CREST (Consistency-driven Rationale Evaluation for Self-Training), a self-training framework that further evaluates each rationale through follow-up questions and leverages this evaluation to guide its training. Specifically, we introduce two methods: (1) filtering out rationales that frequently result in incorrect answers on follow-up questions and (2) preference learning based on mixed preferences from rationale evaluation results of both original and follow-up questions. Experiments on three question-answering datasets using open LLMs show that CREST not only improves the logical robustness and correctness of rationales but also improves reasoning abilities compared to previous self-training approaches.
Federated Learning: Issues in Medical Application
Sep 01, 2021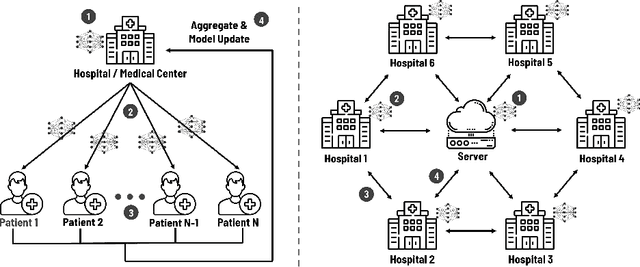
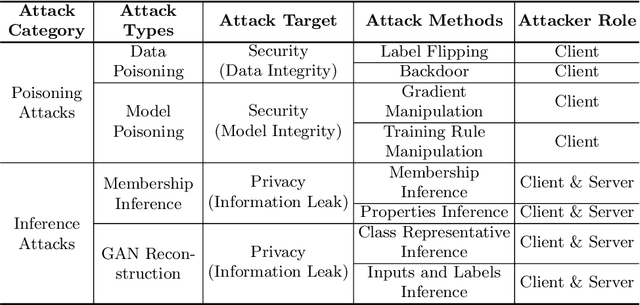
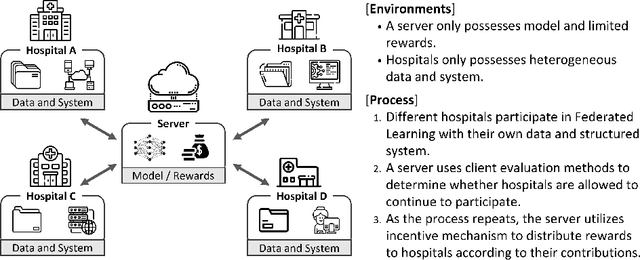
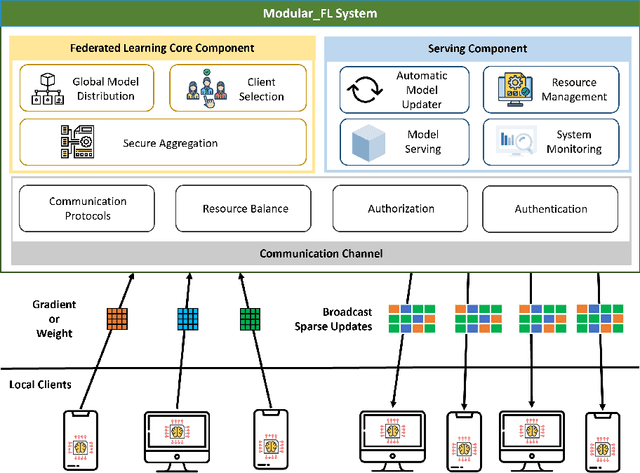
Since the federated learning, which makes AI learning possible without moving local data around, was introduced by google in 2017 it has been actively studied particularly in the field of medicine. In fact, the idea of machine learning in AI without collecting data from local clients is very attractive because data remain in local sites. However, federated learning techniques still have various open issues due to its own characteristics such as non identical distribution, client participation management, and vulnerable environments. In this presentation, the current issues to make federated learning flawlessly useful in the real world will be briefly overviewed. They are related to data/system heterogeneity, client management, traceability, and security. Also, we introduce the modularized federated learning framework, we currently develop, to experiment various techniques and protocols to find solutions for aforementioned issues. The framework will be open to public after development completes.